01 线性回归模型
1.1 最小二乘法
1.线性回归模型:
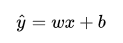
2.损失函数的定义:
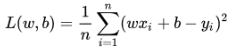
3.目标函数:
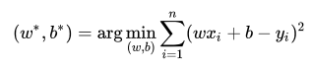
4.计算方法:
(1)根据《微积分2》二元函数极值的求法,我们需要将损失函数 L(w,b)分别对w,b进行求偏导,使得偏导分别为零
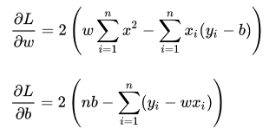
(2) 梯度下降法更新w,b参数
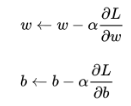
1.2 应用举例
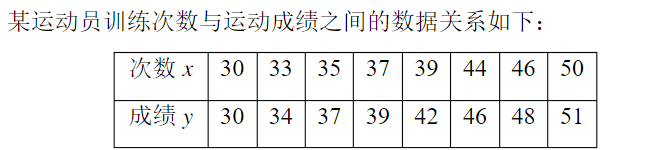
代码如下:
(1)初始化坐标点,同时数据可视化
import numpy as np
import torch as t
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 将输入的值,和要输出的结果分别存放在Input,Output之中
"""
注意:要想使用pytorch微分求导,必须初始化二维张量
"""
Input = t.tensor([[30.,33.,35.,37.,39.,44.,46.,50.]],requires_grad = True)
Output = t.tensor([[30.,34.,37.,39.,42.,46.,48.,51.]],requires_grad = True)
# 绘制散点图时,需要把张量转化为numpy的数据结构
X = Input.data.numpy()
Y = Output.data.numpy()
plt.scatter(X,Y)
plt.show()
Input = Input.data
Output = Output.data
初始数据的分布图:

(2)初始化参数
# 随机初始化参数(因为w,b是需要计算梯度来更新参数的)
w = t.tensor([0.],requires_grad = True)
b = t.tensor([0.],requires_grad = True)
(3) 训练模型
# 迭代的次数
EPOCHS = 1000
# 学习率
lr = 0.00001
for epoch in range (EPOCHS):
# 初始化损失函数 Loss = sum((output - y_pred)^2)/n
loss_function = t.nn.MSELoss()
# 在原来初始的参数w,b的条件下,计算出预测值
y_pred = Input * w + b
# 计算预测值与目标值之间的误差
loss = loss_function(Output,y_pred)
if epoch%10==0:
print('epoch = %d, w = %.4f, b = %.4f, loss = %.8f' % (epoch,w.item(),b.item(),loss.item()))
# 得到预测值与目标值误差之后,即得到损失函数之后分别求L对w,b的偏导
loss.backward()
# 更新参数
w.data -= lr * w.grad
b.data -= lr * b.grad
# Pytorch中更新完参数之后需要对原来的梯度进行清零否则会累加
w.grad.data.zero_()
b.grad.data.zero_()
# 训练完毕,将拟合情况可视化
X = Input.data.numpy()
Y = Output.data.numpy()
plt.scatter(X,Y)
X = np.linspace(30,50,100)
Y = w.item() * X + b.item()
plt.plot(X,Y)
plt.xlabel('times')
plt.ylabel('score')
plt.show()a -= lr * b.grad
w.grad.data.zero_()
b.grad.data.zero_()
X = Input.data.numpy()
Y = Output.data.numpy()
plt.scatter(X,Y)
X = np.linspace(30,50,100)
Y = w.item() * X + b.item()
plt.plot(X,Y)
plt.xlabel('times')
plt.ylabel('score')
plt.show()
训练过程(截取的片段):

拟合结果:

1.3 归纳总结
训练的关键:
(1)输入值与目标输出的存储:需要用二维的张量存储,在pytorch中,x = torch.tensor([[]],reqiures_grad = True),然后取x.data只取张量的数值部分
(2)初始化参数w,b:w,b = torch.tensor([[]],reqiures_grad = True)
(3)训练模型:
1)选择损失函数 loss_function = t.nn.MSELoss()
2)计算预测值
3)调用损失函数将目标值和预测值代入损失函数 loss = loss_function(Output,y_pred)
4)计算 损失函数 L 对w,b偏导,loss.backward()
5)更新梯度,每一轮更新需要将梯度清零 w.grad.data.zero_(); b.grad.grad.zero_()
1.4 参考资料
【1】《机器学习》 周志华 清华大学出版社
【2】 视频:https://morvanzhou.github.io/tutorials/machine-learning/torch/