一.决策树:
- 决策树是什么?决策树是一种基于分类和回归的算法。下面主要讨论分类算法。

上面的流程图就是一个决策树,模块分为判断模块或终止模块,长方形代表判断模块,椭圆形代表终止模块,决策树由结点和有向边组成,结点类似于树上,树干与树躯体的交点,有向边类似于树干,结点分为内部结点,叶结点,
内部结点指长方形模块,内部包含属性或特征,叶结点内部包含一个类(我们将分类的结果分为多个类),有向边是指箭头以及直线所构成的边。
. 决策树的三个步骤(一般情况下)——(收集数据,准备数据,分析数据,训练算法,测试算法,使用算法)特征选择,决策树的生成,决策树的修剪(本文不讨论决策树的修剪)
. 决策树的学习目标:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
. 决策树的本质:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
我们可以把决策树看作成一个if -then 集合(if-elif…-else)决策树的根节点到叶节点构建一条规则,路径上内部结点的属性对应着规则的条件。
二.决策树构建
1 .熵:简单的说熵是衡量我们这个世界中事物混乱程度的一个指标,热力学第二定律中认为孤立系统总是存在从高有序度转变成低有序度的趋势,这就是熵增的原理。
2.信息熵(或香农熵):(信息熵越大,变量的不确定越大,反之越小)信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有多少信息量。直到1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题
它描述了变量的不确定性,即含有有效信息的量,就相当于一个人说了一堆话,你可能觉得他说了一堆废话,只有几句有用的话一样,信息熵就很好度量了这一特点。
H§=−plog2p−(1−p)log2(1−p)当物体只有一个特征时,信息熵表达式为上式。

图片描述了在概率为0或1的点信息熵最小即变量的不确定性最小,且概率越接近0.5,不确定性越大。
3.条件熵

条件熵的公式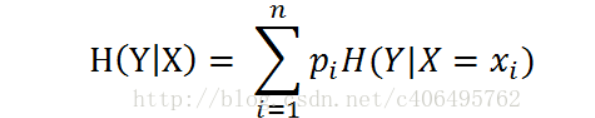
表示在X(某一特征)确定下,对应的信息熵。通俗的讲,信息熵,是对多个数据有用信息的度量,如果我们已经确定了X为有用信息,在此情况下,计算Y的不确定性的度量,如果是是否工作这一特征,我们分别计算有工作没有工作的信息熵,得出的是再次数据集中任意工作关系对应的对个别贷款的不确定性度量,即对类别的判别准确度。然后再根据特征的对应属性,划分子节点,判断其为内部结点还是叶节点,如果只有一类则为叶节点,若为多类,则其信息熵不为0,所以递归上式算法。
4.信息增益:
信息增益的定义:

这里为什么要乘5/15,不同样本对应的比例,因为不同数量对应的有效信息量不同。
更多关于熵的概念:信息熵及其相关概念https://blog.csdn.net/am290333566/article/details/81187124
5.ID3算法:
ID3算法的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。
from math import log
import operator
def createdata():
data= [[0, 0, 0, 0, 'no'], #数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] #特征标签
return data, labels
def xinxishang(data):#香农熵,信息熵
lendata=len(data)
datadict={}
for i in data:
label=i[-1]
if label not in datadict.keys():
datadict[label]=0
datadict[label]+=1
xiangnong=0
for key in datadict:
gailv=datadict[key]/lendata
xiangnong -=gailv*log(gailv,2)
return xiangnong
#按指定特征值划分
def splitdata(data,index,value):(分割数据,意在构建决策树的每一层)
newdata=[]
for i in data:
if i[index]==value:
newdatabefore=i[:index](将原始数据的不包含index的前半部分放入新数据)
newdatabefore.extend(i[index+1:])(将后半部分放入)
newdata.append(newdatabefore)
return newdata
#选择最优特征
def choosebesttezheng(data):(ID3算法选择信息增益(表示在知道某个数据的条件下,hsu'ju'de'bu'qu'ding'xing'jian'xiao'de数据的不确定性减小的程度)的最大值作为最优特征)
numbertezheng=len(data[0])-1
xiangnong=xinxishang(data)
zengyishang=0
besttezheng=-1
for i in range(numbertezheng):
a=[tezheng[i] for tezheng in data ]
seta=set(a)(集合,并排好序)
tiaojianshang=0
for value in seta:
newdata=splitdata(data,i,value)
lennewdata=len(newdata)
newdatagailv=lennewdata/len(data)
tiaojianshang+=newdatagailv*xinxishang(newdata)
zengyishangbefore=xiangnong-tiaojianshang
if (zengyishangbefore>zengyishang):
zengyishang=zengyishangbefore
besttezheng=i
return besttezheng
def vote(list1):(投票法当所有特征被split完,仍有不确定性,则使用投票法,多的胜出)
b={}
for vote in list1:
if vote not in b.keys():
b[vote]=0
b[vote]+=1
sortedb=sorted(b.items(),key=operator.itemgetter,reverse=True)
return sortedb
def createtree(data,labels,liebiao):
labelslist=[i[-1] for i in data]
if labelslist.count(labelslist[0])==len(labelslist):(如果一个属性对应的类全为1/0,则返回这个类)
return labelslist[0]
if len(data[0])==1:
return vote(labelslist)
besttezheng=choosebesttezheng(data)
bestlabel=labels[besttezheng]
liebiao.append(bestlabel)
mytree={bestlabel:{}}
del labels[besttezheng]
shuxing=[i[besttezheng] for i in data]
setshuxing=set(shuxing)
for value in setshuxing:
mytree[bestlabel][value]=createtree(splitdata(data,besttezheng,value),labels,liebiao)(递归调用:自己调用自己且有返回值)
return mytree
data,labels=createdata()
c=[]
mytree=createtree(data,labels,c)
def getnumleaf(mytree):#叶子节点数
numleaf=0
firstkey=next(iter(mytree))
firstvalue=mytree[firstkey]
for i in firstvalue.keys():
if firstvalue[i].__name__=="dict":
numleaf+=getnumleaf(firstvalue[i])(从下到上的数)
else :
numleaf+=1
return numleaf
def gettreedeep(mytree):#树的深度
maxtreedeep=0
firstkey=next(iter(mytree))
firstvalue=mytree[firstkey]
for i in firstvalue.keys():
if firstvalue[i].__name__=="dict":
thisdeep=1+gettreedeep(firstvalue[i])(考虑到set后的顺序)
else :
thisdeep+=1
if thisdeep>maxtreedeep:
maxtreedeep=thisdeep
return maxtreedeep
def fenlei(mytree,labels,ceshishuju):(对决策树的预测)
firstdict=next(iter(mytree))
firstvalue=mytree[firstdict]
first_index=labels.index(firstdict)
for i in firstvalue.keys():
if ceshishuju[first_index]==i:
if type(firstvalue[i]).__name__=="dict":
result=fenlei(firstvalue[i],labels,ceshishuju)
else:
result=firstvalue[i]
return result
a="年龄"
ceshishuju=(int(input(a+":")))
dict1={}
dict1[a]=ceshishuju(输入一组数据判断其对应的类)
a="有工作"
ceshishuju=(int(input(a+":")))
dict1[a]=ceshishuju
a="有自己的房子"
ceshishuju=(int(input(a+":")))
dict1[a]=ceshishuju
a="信贷情况"
ceshishuju=(int(input(a+":")))
dict1[a]=ceshishuju
d=[]
for i in c:
for j in dict1.keys():
if i==j:
d.append(dict1[j])
result=fenlei(mytree,c,d)
if result=="yes":
result="贷款"
else:
result="不贷款"
print(result)
递归创建决策树时,递归有两个终止条件:第一个停止条件是所有的类标签完全相同,则直接返回该类标签;第二个停止条件是使用完了所有特征,仍然不能将数据划分仅包含唯一类别的分组,即决策树构建失败,特征不够用。此时说明数据纬度不够,由于第二个停止条件无法简单地返回唯一的类标签,这里挑选出现数量最多的类别作为返回值。
结果如下:

6.信息增益,信息增益率(C4.5算法),基尼指数(Geni)(CART算法)
在使用信息增益时,信息增益偏向于特征多的值,因为对应的条件熵小,导致过拟合,(一味的训练数据导致无法预测超出数据外的数据)
信息增益比 = 惩罚参数 * 信息增益
书中公式: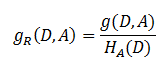
注意:其中的HA(D),对于样本集合D,将当前特征A作为随机变量(取值是特征A的各个特征值),求得的经验熵。
(之前是把集合类别作为随机变量,现在把某个特征作为随机变量,按照此特征的特征取值对集合D进行划分,计算熵HA(D))
信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
惩罚参数:数据集D以特征A作为随机变量的熵的倒数,即:将特征A取值相同的样本划分到同一个子集中(之前所说数据集的熵是依据类别进行划分的)
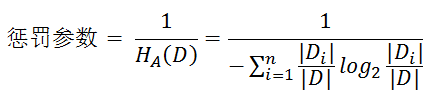
缺点:信息增益比偏向取值较少的特征
原因: 当特征取值较少时HA(D)的值较小,因此其倒数较大,因而信息增益比较大。因而偏向取值较少的特征。
使用信息增益比:基于以上缺点,并不是直接选择信息增益率最大的特征,而是现在候选特征中找出信息增益高于平均水平的特征,然后在这些特征中再选择信息增益率最高的特征。
具体讲解https://www.cnblogs.com/muzixi/p/6566803.html
基尼指数:
本质上与信息增益差别不大,主要是其的不确定性值整体小于信息增益,

三.总结
优点
- 易于理解和解释,决策树可以可视化。
- 几乎不需要数据预处理。其他方法经常需要数据标准化
- 可以同时处理数值变量和分类变量。其他方法大都适用于分析一种变量的集合。
- 可以处理多值输出变量问题。
- 即使对真实模型来说,假设无效的情况下,也可以较好的适用。
缺点
- 会因为一些问题过拟合。