版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lx_ros/article/details/81254937
1.(逻辑斯蒂分布)logistic distribution
X是连续型随机变量,则logistic distribution是:
其形状如下:

2.logistic 回归模型
- 一种分类模型,由条件概率分布P(Y|X)表示,是一种判别模型
- 逻辑回归模型的定义:
3.模型参数的估计
对于给定的训练数据集, ,估计其参数的方法有,
3.1 极大似然估计
- 记,
- 那么模型的极大似然函数为:
- 模型的对数似然函数为:
- 求 的极大值即可得到 的估计值。
3.2梯度下降法
- 损失函数:
- 梯度:
- 参数更新:
4.Python 代码实现
使用的数据下载(终端):wget https://raw.githubusercontent.com/lxrobot/General-source-code/master/logisticRegression/data.csv
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 24 14:54:18 2018
@author: rd
"""
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
from copy import deepcopy
import math
def loadData():
tmp=np.loadtxt("data.csv",dtype=np.str,delimiter=",")
data=tmp[1:,:].astype(np.float)
np.random.shuffle(data)
train_data=data[:int(0.7*len(data)),:]
test_data=data[int(0.7*len(data)):,:]
train_X=train_data[:,:-1]/50-1.0 #feature normalization[-1,1]
train_Y=train_data[:,-1]
test_X=test_data[:,:-1]/50-1.0
test_Y=test_data[:,-1]
return train_X,train_Y,test_X,test_Y
#pos=np.where(train_Y==1.0)
#neg=np.where(train_Y==0.0)
#plt.scatter(train_X[pos,0],train_X[pos,1],marker='o', c='b')
#plt.scatter(train_X[neg,0],train_X[neg,1],marker='x', c='r')
#plt.xlabel('Chinese exam score')
#plt.ylabel('Math exam score')
#plt.legend(['Not Admitted', 'Admitted'])
#plt.show()
#The sigmoid function
def sigmoid(z):
return 1/(1+np.exp(-z))
def loss(h,Y):
return (-Y*np.log(h)-(1-Y)*np.log(1-h)).mean()
def predict(X,theta,threshold):
bias=np.ones((X.shape[0],1))
X=np.concatenate((X,bias),axis=1)
z=np.dot(X,theta)
h=sigmoid(z)
pred=(h>threshold).astype(float)
return pred
def logisticRegression(X,Y,alpha,num_iters):
model={}
bias=np.ones((X.shape[0],1))
X=np.concatenate((X,bias),axis=1)
theta=np.ones(X.shape[1])
for step in xrange(num_iters):
z=np.dot(X,theta)
h=sigmoid(z)
grad=np.dot(X.T,(h-Y))/Y.size
theta-=alpha*grad
if step%1000==0:
z=np.dot(X,theta)
h=sigmoid(z)
print "{} steps, loss is {}".format(step,loss(h,Y))
print "accuracy is {}".format((predict(X[:,:-1],theta,0.5)==Y).mean())
model={'theta':theta}
return model
train_X,train_Y,test_X,test_Y=loadData()
model=logisticRegression(train_X,train_Y,alpha=0.01,num_iters=40000)
print "The test accuracy is {}".format((predict(test_X,model['theta'],0.5)==test_Y).mean()) 输出:
>>>python
0 steps, loss is 0.640056024601
accuracy is 0.614285714286
1000 steps, loss is 0.465700342681
accuracy is 0.757142857143
2000 steps, loss is 0.412992043943
accuracy is 0.885714285714
...
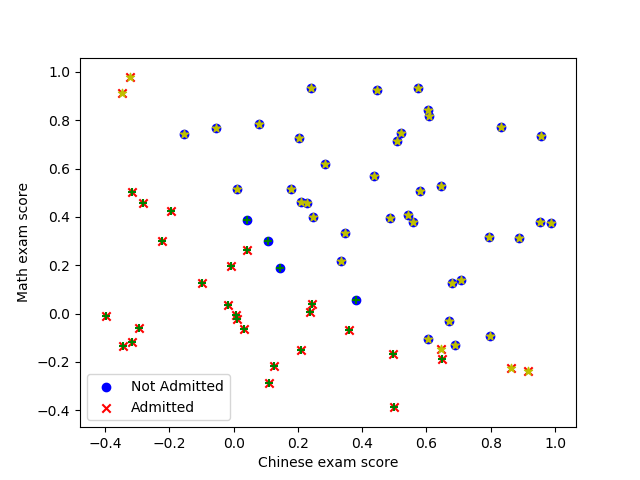
The test accuracy is 0.866666666667预测结果:(黄色星号,绿色十字为预测值)
refer
[1] https://towardsdatascience.com/building-a-logistic-regression-in-python-step-by-step-becd4d56c9c8