案例: 预测酸奶的日销量, 由此可以准备产量, 使得损失小(利润大),假设销量是y , 影响销量的有两个因素x1, x2,
需要预先采集数据,每日的x1,x2和销量y_, 拟造数据集X,Y_, 假设y_=x1+x2,为了更真实加一个噪声(-0.05-0.05)
batch_size=8 #一次喂给神经网络多少数据 seed=23455 #构造数据集 rdm=np.random.RandomState(seed) #基于seed产生随机数 X=rdm.rand(32,2) #32组数据 Y_=[[x1+x2+(rdm.rand()/10.0-0.05)] for (x1,x2) in X] #rdm.rand()/10.0 是(0,1)随机数 print('X:\n',X) print('Y_:\n',Y_) #定义神经网络的输入 参数 输出 定义前向传播过程 x=tf.placeholder(tf.float32,shape=(None,2)) y_=tf.placeholder(tf.float32,shape=(None,1)) # 合格或者不合格的特征 w1=tf.Variable(tf.random_normal([2,1],stddev=1,seed=1)) y=tf.matmul(x,w1) #定义损失函数 后向传播方法 loss_mse=tf.reduce_mean(tf.square(y_-y)) train_step=tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse) #train_step=tf.train.MomentumOptimizer(0.001,0.9).minimize(loss) #其他方法 #train_step=tf.train.AdamOptimizer(0.001).minimize(loss) #生成会话 训练 with tf.Session() as sess: #用会话计算结果 init_op=tf.global_variables_initializer() sess.run(init_op) print('w1:\n', sess.run(w1)) #输出目前(未经训练的)参数取值 #训练模型 steps=20000 #训练20000次 for i in range(steps): start=(i*batch_size) %32 end=start+batch_size sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]}) #8组数据 if i % 500==0: #每500轮打印一次w1值 print('After %d training steps,w1 is:' %i) print(sess.run(w1),'\n') print('Final w1 is:',sess.run(w1)) 结果显示 w1=[0.98,1.015] 这与Y_=x1+x2一致,预测正确!!
1.loss优化
上述例子中, loss函数是均方和, 但是实际中,预测的销量(即要准备的产量y_) 与真实的销量y 之间的差异导致的损失 取决于 生产成本cost 与销售利润profit,
当预测多了, 损失成本, 预测少了,损失利润,
所以这里要自定义loss, 上述代码不变,只需要修改下loss参数

batch_size=8 #一次喂给神经网络多少数据 seed=23455 cost=1 profit=9 #构造数据集 rdm=np.random.RandomState(seed) #基于seed产生随机数 X=rdm.rand(32,2) #32组数据 Y_=[[x1+x2+(rdm.rand()/10.0-0.05)] for (x1,x2) in X] #rdm.rand()/10.0 是(0,1)随机数 print('X:\n',X) print('Y_:\n',Y_) #定义神经网络的输入 参数 输出 定义前向传播过程 x=tf.placeholder(tf.float32,shape=(None,2)) y_=tf.placeholder(tf.float32,shape=(None,1)) # 合格或者不合格的特征 w1=tf.Variable(tf.random_normal([2,1],stddev=1,seed=1)) y=tf.matmul(x,w1) #定义损失函数 后向传播方法 loss=tf.reduce_sum(tf.where(tf.greater(y,y_),cost*(y-y_),profit*(y_-y)))
#tf.where(tf.greater(y,y_),cost*(y-y_),profit*(y_-y))第一个表示逻辑值,当为真时取第二项
#为假时取第三项
train_step=tf.train.GradientDescentOptimizer(0.001).minimize(loss) #train_step=tf.train.MomentumOptimizer(0.001,0.9).minimize(loss) #其他方法 #train_step=tf.train.AdamOptimizer(0.001).minimize(loss) #生成会话 训练 with tf.Session() as sess: #用会话计算结果 init_op=tf.global_variables_initializer() sess.run(init_op) print('w1:\n', sess.run(w1)) #输出目前(未经训练的)参数取值 #训练模型 steps=20000 #训练3000次 for i in range(steps): start=(i*batch_size) %32 end=start+batch_size sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]}) #8组数据 if i % 500==0: #每500轮打印一次结果 print('After %d training steps,w1 is:' %i) print(sess.run(w1),'\n') print('Final w1 is:',sess.run(w1))
得到结果是w1=[1.02,1.04] ,系数都大于1 ,这是由于多预测的损失 少于少预测的损失,结果也往多的方向预测了.要是 cost=9 ,profit=1,
最终得到参数w1=[0.96, 0.97] 都小于1
除了均方和, 自定义loss只要, 还有第三种 交叉熵(cross entropy)的loss,
交叉熵(cross entropy): 表示两个概率分布之间的距离, ce越大,距离也就越大.


交叉熵 ce
ce=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-12,1.0)))
n个分类的n输出

ce=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
cem=tf.reduce_mean(ce)
2.learning_rate 学习率调整
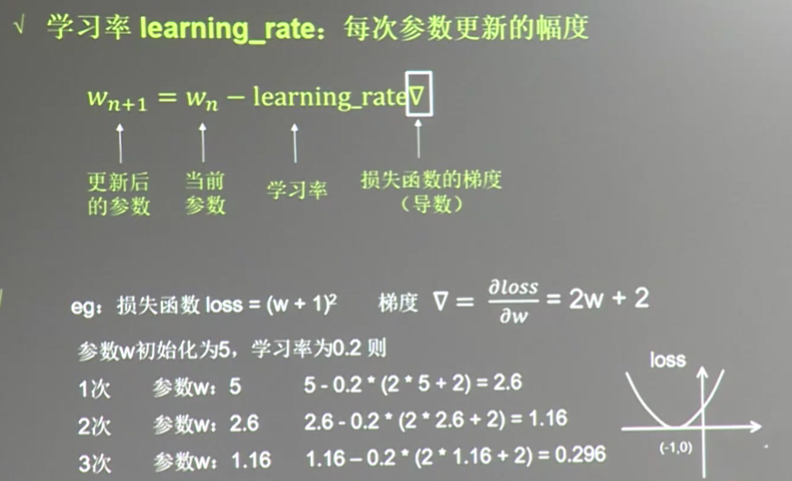
设置learning_rate=0.2
w=tf.Variable(tf.constant(5,dtype=tf.float32)) loss=tf.square(w+1) #定义损失函数 train_step=tf.train.GradientDescentOptimizer(0.2).minimize(loss) with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op) for i in range(40): #迭代40次 sess.run(train_step) w_val=sess.run(w) loss_val=sess.run(loss) print('after %d steps, w is %f, loss is %f.'%(i,w_val,loss_val))
若上述learning_rate=0.001, w趋于-1速度很慢, learning_rate=1, w会发散,不会趋于-1
上述learning_rate 不能太大,也不能太小

#学习率 决定参数的更新 learning_rate #根据运行的轮数决定动态更新学习率 learning_rate=LEARNING_RATE_BASE*LEARNING_RATE_DECAY^(global_step/LEARNING_RATE_STEP) #LEARNING_RATE_BASE是学习率初始值 LEARNING_RATE_DECAY是学习衰减率(0,1) #多少轮更新一次学习率,LEARNING_RATE_STEP 一般是总样本数/batch_size global_step=tf.Variable(0,trainable=False) #记录当前共运行了多少轮batch-size learning_rate=tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
# staircase true 学习率阶梯型衰减, false则为平滑下降的曲线
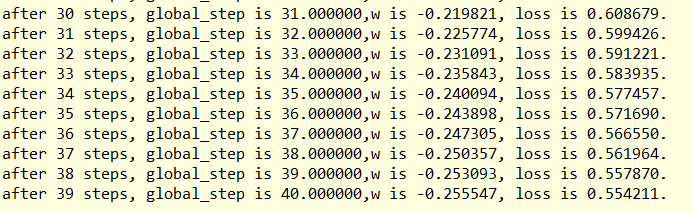
#根据运行的轮数决定动态更新学习率 LEARNING_RATE_BASE=0.1 #最初学习率 LEARNING_RATE_DECAY=0.9 #学习率衰减率 LEARNING_RATE_STEP=1 # 喂入多少batch_size后更新一次学习率,一般是总样本数/batch_size,这里为了方便为1 global_step=tf.Variable(0,trainable=False) #记录当前共运行了多少轮batch-size #定义指数下降学习率 learning_rate=tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True) #优化参数 ,初值5 w=tf.Variable(tf.constant(5,dtype=tf.float32)) loss=tf.square(w+1) #定义损失函数 train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step) with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op) for i in range(40): #迭代40次 sess.run(train_step) learning_rate_val=sess.run(learning_rate) global_step_val=sess.run(global_step) w_val=sess.run(w) loss_val=sess.run(loss) print('after %d steps, global_step is %f,w is %f, loss is %f.' %(i,global_step_val,w_val,loss_val))
结果: