版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011479200/article/details/88575038
在深入学习Kafka之前,需要先了解topics, brokers, producers和consumers等几个主要术语。 下面说明了主要术语的详细描述和组件。
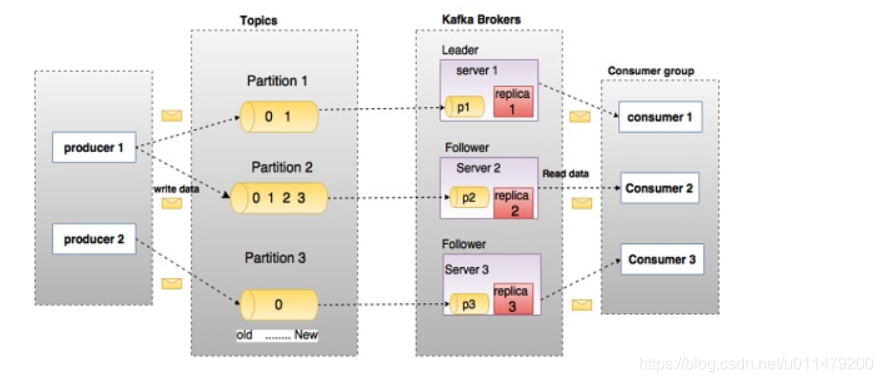
主题和分区
在上图中,主题(topic)被配置为三个分区。
分区1(Partition 1)具有两个偏移因子0和1。
分区2(Partition 2)具有四个偏移因子0,1,2和3
分区3(Partition 3)具有一个偏移因子0。
replica 的id与托管它的服务器的id相同。
假设,如果该主题的复制因子设置为3,则Kafka将为每个分区创建3个相同的副本,并将它们放入群集中以使其可用于其所有操作。 为了平衡集群中的负载,每个代理存储一个或多个这些分区。 多个生产者和消费者可以同时发布和检索消息。
总结:
多个Broker是为了做集群来实现高可用.(Leader挂掉了,Follower会成为Leader继续发挥Leader的作用)
Topics主题分为多个分区
每个分区消息都有一个称为偏移量的唯一序列标识.
Replicas of partition - 副本只是分区的备份。 副本从不读取或写入数据。 它们用于防止数据丢失。
集群:Kafka Cluster - Kafka拥有多个经纪人称为Kafka集群。 Kafka集群可以在无需停机的情况下进行扩展。 这些集群用于管理消息数据的持久性和复制。