【Kafka-架构及基本原理】Kafka生产者、消费者、Broker原理解析 & Kafka原理流程图
1)Kafka原理
1.1.生产者流程细节
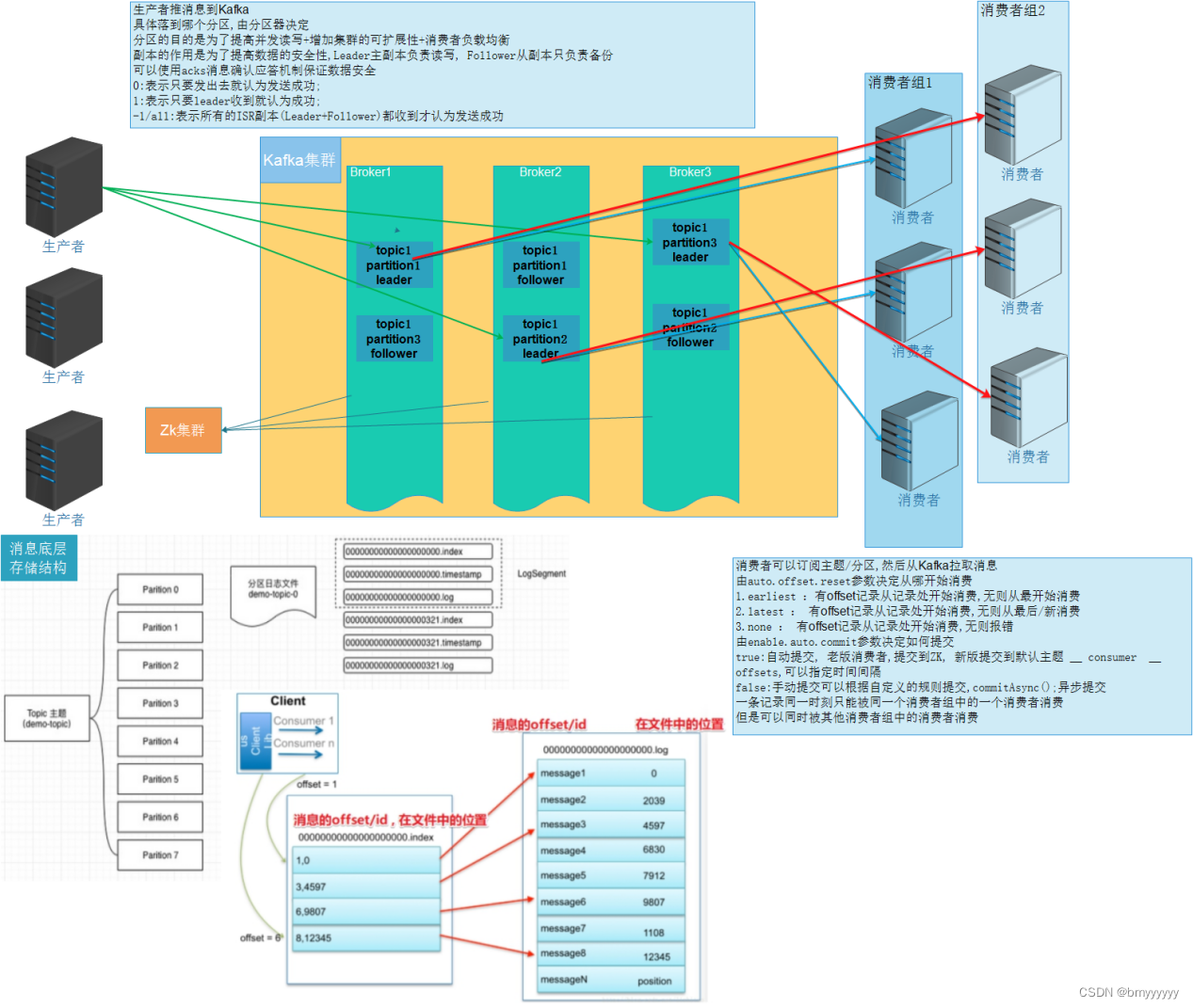
1、生产者发送消息到 Kafka 集群,是以推送的方式发送的。
2、生产者只需要连接任意一台 Kafka 节点即可。
3、生产者发送的消息会被封装成为一个 record 对象,其中包含了发送的主题,分区,key,value。
4、发送出去的消息是如何进行分区的呢?
-
如果是没有指定分区和 key,那么就会按照轮循的方式进行循环分区。
-
如果是指定了 key 但是没有指定分区,那么就会按照 DefaultPartitioner 这个类进行分区,底层使用 hash 取模的方式进行分区。
-
如果是指定了分区,那么就会按照指定的分区将所有的 value 都发送到一个分区中(优先级最高)
-
可以自定义分区类(根据 DefaultPartitioner 来进行模仿即可)
注意:在这个过程中的 key 只是逻辑上的一个业务标记(key 是可以重复的),而 value 才是消息中的真正内容。
5、分区的作用?
-
提高读写的效率。
-
增大了集群的扩容性(机器增加的时候可以对分区数进行增加)
-
方便消费者负载均衡(消费者数=分区数)
6、每一条消息发送给 Kafka 集群的时候,首先发送到一个缓冲区中,然后以 batch 的方式发送给 Kafka,并且按照顺序写入的方式追加到文件中。
7、每一条消息发送给分区之后都会有一个。唯一标识 offset(偏移量),offset 是区内有序的,全局无序的,也就是说 Kafka 具有局部有序的特性。
1.2.Broker 的存储流程细节
1、消息到达 Kafka 之后会根据分区规则进入到指定的分区中(分区是分散在各个节点中的,一般分区数与 Broker 数量成倍数关系,保证均衡性)
2、分区其实就是物理层面上的文件夹。
3、分区下面还有文件的分段(segment)(和 hive 中的分桶差不多),每个 segment 由 index 索引文件和 log 日志文件组成,index 文件中记录着信息的索引,log 文件中记录的就是消息的内容。
4、查询的时候会先到 index 文件中根据 offset 找到 log 文件中对应的消息的位置。
5、数据并不是一直存储在 Kafka 中的,会有删除策略。
-
首先文件达到一定的时间(默认时间是七天,168小时)的时候,就会对数据进行自动删除。
-
其次就是文件达到一定的大小就会删除。
注意:数可以在配置文件中随时进行修改。
6、数据越来越多也不会对Kafka的读写产生影响,因为:
-
写入:各分区采用的是顺序写入,追加的方式。
-
Kafka 的 index 文件是采用的二分查找法,数据越多查找的越爽。
1.3.消费者流程细节
1、消费者从 Kafka 中消费消息采用的是拉取的模式。
2、消费者连接 Kafka 集群中的任意一个节点,并且指定想要订阅的主题或者主题 + 分区。
3、消费者从哪个偏移量开始消费,由 auto、offset、reset 决定。
-
earliest:如果有 offset 记录的位置,就从记录的位置开始消费,如果没有 offset 的记录,就从最早的位置开始消费。 -
latest:如果有 offset 记录的位置,就从记录的位置开始消费,如果没有 offset 的记录,就从最新的位置开始消费。 -
none:如果有 offset 提交记录,就从记录位置开始消费,没有则报错。
4、消费者消费数据之后需要提交 offset。
-
自动提交:按照固定的时间间隔进行提交(提交到默认主题:__consumer_offsets) -
手动提交:可以自定义没消费多少条,统一提交一次,也就是说可以分批提交。注意:提交的信息包括,消费者消费到哪个主题的哪个分区了的哪个偏移量了。
5、消费者组内可以有多个消费者(如果没有设置消费者组就会有默认的消费者组,但是建议手动设置,方便管理)
注意:同一时间的一条消息只能被一个消费者组内的一个消费者所消费,但是可以被不同的消费者组的消费者再次消费。
6、消费者组中的消费者数量建议等于分区数。
2)Kafka读写流程图