系列文章目录
一、kafka基本原理
二、使用java简单操作kafka
三、简单了解kafka设计原理
文章目录
前言
文章中的linux命令不了解没关系,正常使用的时候有简单的使用方法,不用记这些命令,只是用来讲解kafka的一些功能使用。
了解kafka
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
一、简单了解kafka基本概念
| 序号 | 名称 | 基本概念 | 备注 |
|---|---|---|---|
| 1 | Broker | 一个kafka就是一个broker,一个或多个broker可以组成一个kafka集群 | |
| 2 | Topic | kafka根据topic对消息进行归类,发布到kafka集群的每条消息指定一个topic | 主题 |
| 3 | Producer | 消息生产者,向broker发送消息的客户端 | 生产者 |
| 4 | Consumer | 消息消费者,向broker读取消息的客户端 | 消费者 |
| 5 | ConsumerGroup | 每个consumer属于一个特定的consumer group,一条消息可以被多个不同的consumer group消费,但是一个consumer group 只能有一个consumer能够消费 | 消费组 |
| 6 | Partition | 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 | 分区 |
二、使用kafka
1.安装kafka
参考如下教程
2.简单使用
- 创建一个名字为test的主题
cd /opt/software/kafka_2.13-2.7.1
bin/kafka-topics.sh --create --zookeeper 192.168.220.66:2181 --replication-factor 1 --partitions 1 --topic test
- 查看kafka存在的topic
bin/kafka-topics.sh --list --zookeeper 192.168.220.66:2181
- 向test这个topic发一条消息
bin/kafka-console-producer.sh --broker-list 192.168.220.66:9092 --topic test
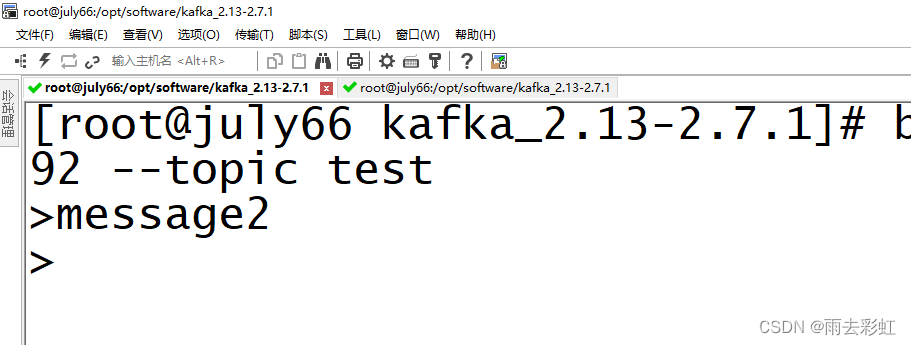
输入一条message1

消费一下消息(这里默认是消费执行完消费命令之后,生产者生产的消息,后边可以配置从指定位置或时间等条件进行消费)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.220.66:9092 --topic test

3.单播消息
一条消息只能被某一个消费者消费的模式,类似queue模式。(只需让所有消费者在同一个消费组里即可)
4.多播消息(发布订阅)
一条消息能被多个消费者消费的模式,类似publish-subscribe模式消费。(kafka对同一条消息只能被同一个消费组下的某一个消费者消费,要实现多播只要保证这些消费者属于不同的消费者组即可。)
- 设置消费者组
让testGroup的消费者组消费topic为test的主题
bin/kafka-console-consumer.sh --bootstrap-server 192.168.220.66:9092 --consumer-property group.id=testGroup --topic test
- 查看消费组的消费偏移量
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.220.66:9092 --describe --group testGroup


5.topic、partition、消息日志Log
慢慢来讲解这个图里边的内容。

一个topic(主题)是可以有多个partition(分区)的,上边我们创建了一个test的topic(主题),只有一个partition(分区)。
我们再创建一个拥有两个partition(分区)的topic(主题),test2。
bin/kafka-topics.sh --create --zookeeper 192.168.220.66:2181 --replication-factor 1 --partitions 2 --topic test2
查看test2
bin/kafka-topics.sh --describe --zookeeper 192.168.220.66:2181 --topic test2

Partition(分区)
partition是一个有序的message序列,生产者生产的message按顺序添加到一个叫commit log的文件中。每个partition中的消息都有一个唯一的编号,称为offset,用来标识某个partition(分区)中的message。- kafka为什么能再次消费已经消费的消息呢,是因为它把message存在log文件里,这写日志的存放地址已经在安装的时候进行的设置。
vim config/server.properties

- 这些日志文件默认是保存一周,这个可以进行配置和上述配置都在同一个配置文件中,kafka的性能与保留消息数据量大小没有关系,因为保存大量的数据消息日志信息不会有什么影响(当然如果磁盘容量紧张的话就另说了)。

每个consumer是基于自己在commit log中的消费进度(offset)也就是偏移量来进行工作的。在kafka中,消费offset由consumer自己来维护。一般情况下我们按照顺序逐条进行消费commit log中的消息,我们也可以通过制度offset来进行消费,实现重复消费,跳过一些消息消费等。这意味着kafka中的consumer对集群的影响是非常小的,添加或者减少一个consumer,对应集群或者其他的consumer来说,都是没有影响的,因为每个consumer维护各自的消费offset。
为什么要对Topic下数据进行分区存储?
-
commit log
文件会受到机器的文件系统大小限制,分区之后可以将不同的分区存放在不同的机器上,相当于对数据做了分布式存储,理论上一个topic可以处理任意数量的数据。 -
为了提高并行度。
topic中的分区是可以扩容的。
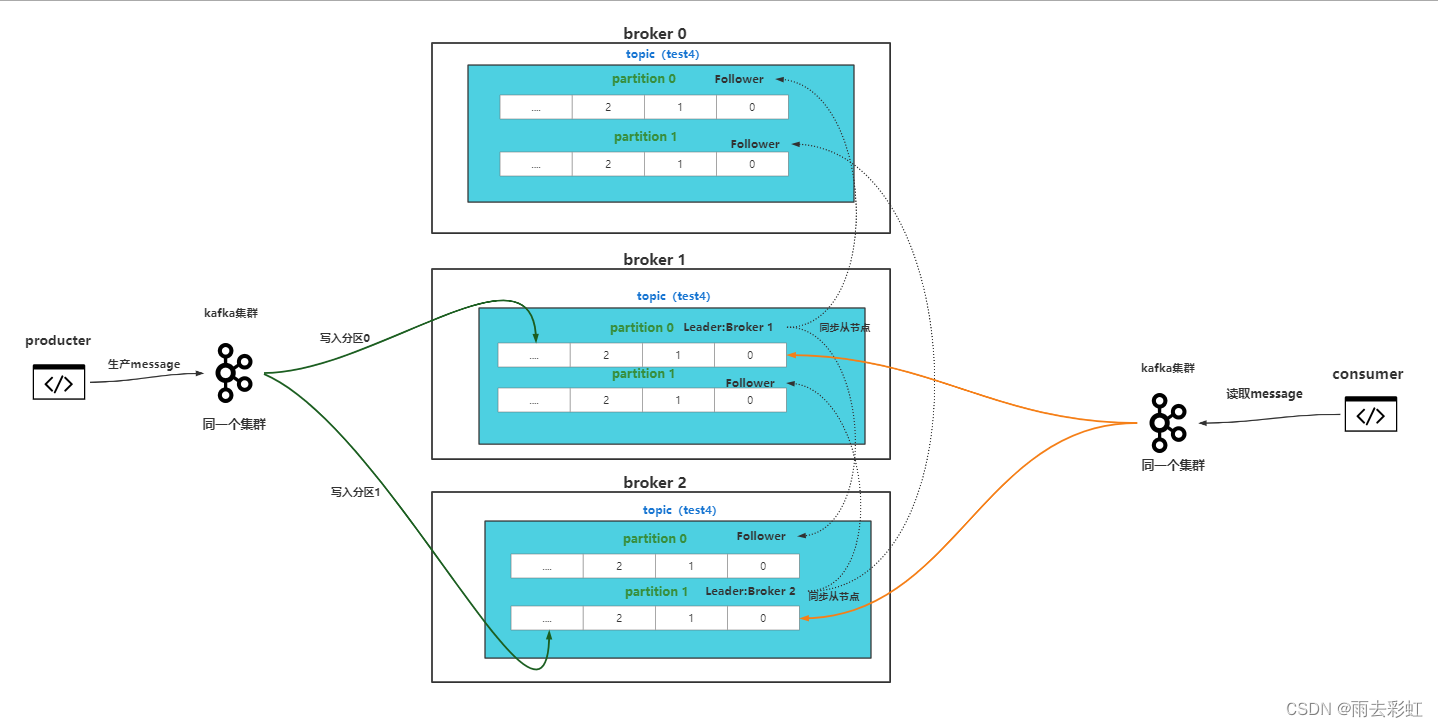
6.Leader、Replicas、Isr

- Leader:节点负责指定partition的所有读写请求
- Replicas:表示某个partition在哪几个broker上存在备份(有几个副本)。不管这个这几个节点是不是leader,甚至这个节点挂了,也会列出来。
- Isr:是replicas的一个子集,它只列出当前还存活的,并且已经同步备份了该partition的节点。(我理解就是健康的节点,随时可以follower变leader的节点)
一个broker可能体现不出来什么,看下边的kafka集群。
搭建kafka集群
再创建一个topic为test4。副本数为三个,分区数两个。
bin/kafka-topics.sh --create --zookeeper 192.168.220.66:2181 --replication-factor 3 --partitions 2 --topic test4
查询该topic
bin/kafka-topics.sh --describe --zookeeper 192.168.220.66:2181 --topic test4

如果leader节点挂了,会通过zookeeper进行选举,选取新的leader。
模拟挂掉一个brokerid为1的kafka
挂掉之前的topic信息

为了区分哪个是broker的id为1的进程,我重启了一个虚拟机,然后先启动broker,id为1的kafka,然后查询一下进程。
bin/kafka-server-start.sh -daemon config/server-1.properties
jps

kill 2286

三、简单了解一下官方文档
安装的kafka版本是2.7
如果忘记了自己装的kafka版本,之前我有提过,你下载的kafka后一部分代表你的kafka版本。
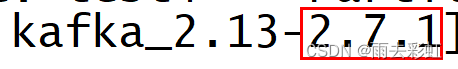

我英语也不是很好,但是我建议如果想要深入掌握kafka的话,有时间多看看官方文档。
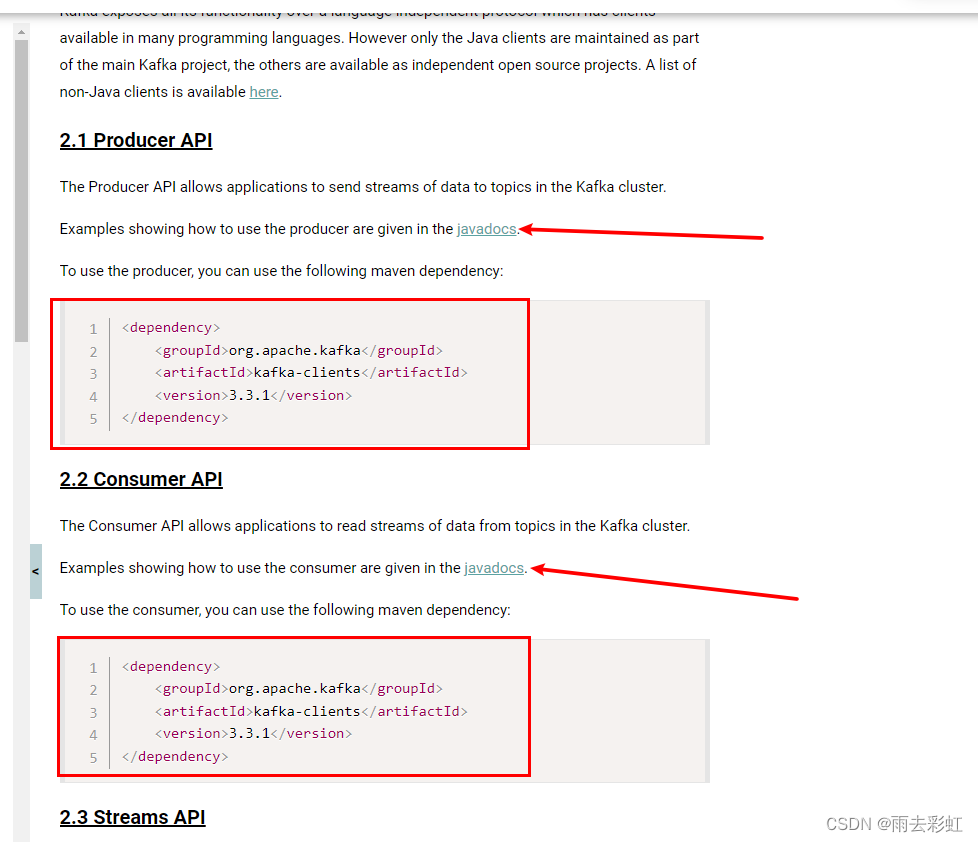
总结
这些命令在官方文档中都能够找到,包括使用java开发也会有详细的信息。比如引入那些依赖等等。教程再好,我们最终也是要自己能理解官方文档,一百个人有一百个哈姆雷特,可能你比我理解kafka更加的透彻。