spark整合hive就是让hive运行在spark上面,其实跟hive没有太大的关系,就是使用了hive的标准(HQL,元数据库,UDF,序列化,反序列化机制)
hive原来的计算模型是MR,将计算结果写入到HDFS中,有点慢,而spark整合hive是让hive运行在spark集群上面,使用spark中的RDD(DataFrame),这样速度很快。
下面来说一下这个元数据:
真正要计算的数据是保存在HDFS中的,hive使用MySQL当作元数据库,MySQL这个元数据库,保存的是hive表的描述信息,描述了有哪些database,table,以及表有多少列,每一列是什么类型,还有描述表的数据保存在HDFS的什么位置。
hive的元数据库建立了一种映射关系,执行HQL时,先到MySQL元数据库中查找描述信息,然后根据描述信息生成任务,然后将任务下发到spark集群中执行。
那么hive和MySQL有什么区别呢?
hive是一个数据仓库(存储数据并分析数据,分析数据仓库中的数据量很大,一般要分析很长的时间)
mysql是一个关系型数据库(关系型数据的增删改查(低延迟))
根据上面的介绍,我们知道首先要安装上MySQL。
1.安装MySQL
在集群上的一台机器上安装上MySQL,详细的安装过程请参考博客:
https://blog.csdn.net/weixin_43866709/article/details/88956929
2.启动MySQL,并创建一个普通用户,并且授权
启动MySQL:
mysql -uroot -p密码
创建一个普通用户并且授权(经过授权其他机器才可以连接上MySQL数据库):
> CREATE USER '用户名'@'%' IDENTIFIED BY '密码'; //创建用户
> GRANT ALL PRIVILEGES ON hivedb.* TO '用户名'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION;
> FLUSH PRIVILEGES;
3.在spark的conf目录下创建一个hive的配置文件,hive-site.xml(在没有安装hive的情况下)
如果安装了hive,直接将hive中的hive-site.xml拷贝到spark中就可以了,
文件内容如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<!--MySQL在哪台机器上-->
<value>jdbc:mysql://node-6:3306/hivedb?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<!--MySQL连接驱动-->
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<!--MySQL用户名-->
<value>bigdata</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<!--填写密码-->
<value>密码</value>
<description>password to use against metastore database</description>
</property>
</configuration>
4.上传一个MySQL连接驱动(sparkSubmit也要连接MySQL,获取元数据信息)
MySQL驱动下载地址:http://www.codedocs.net/maven2/mysql/mysql-connector-java/5.1.6

5.启动spark-sql
cd spark/bin
./spark-sql --master spark://L1:7077,L2:7077 --driver-class-path /home/hadoop/local-jars/mysql-connector-java-5.1.6.jar
说明:
我安装的集群是两个master,所以这里指定了两个master节点
–driver-class-path是指定MySQL连接驱动所在位置
启动完成之后,打开MySQL图形化界面管理工具,如Nacicat,连接上MySQL,或者使用MySQL命令行,可以看到有一个hivedb的数据库,里面一共有29张表,这些表就是用来记录hive表的元数据信息的。
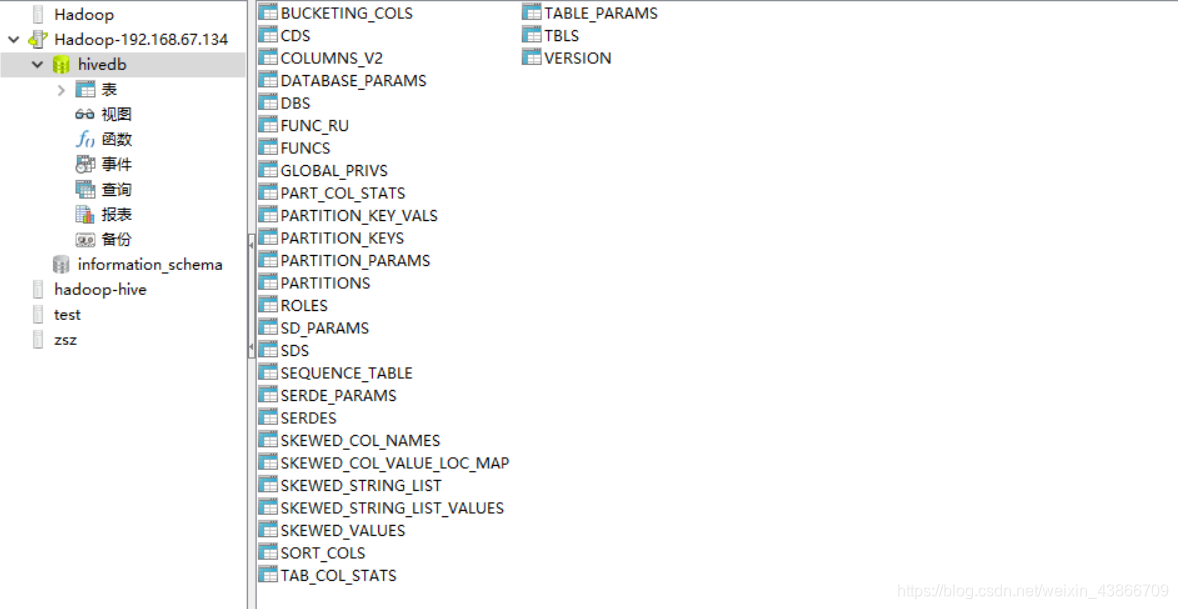
6.创建一个table
创建命令:
create table t_boy(id bigint,name string,fv double) row format delimited fields terminated by ',';
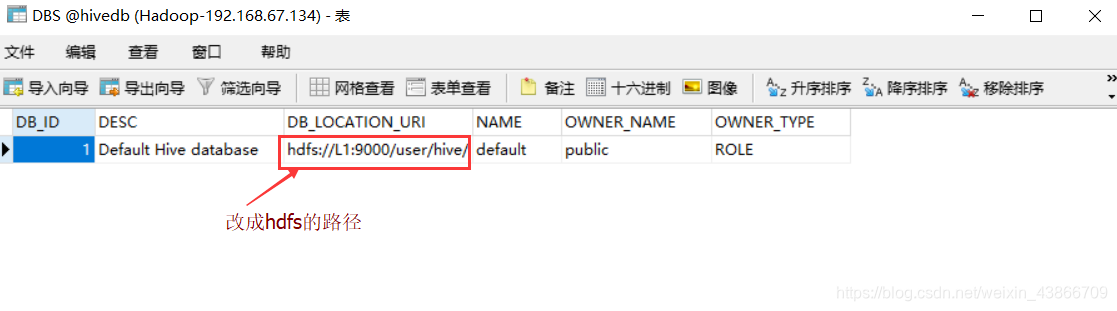
创建成功之后,就可以看到这个表的信息了:
需要手动改一下DBS表中的DB_LOCATION_UIR改成hdfs的地址:(现在默认是本地的文件路径)
7.要在/etc/profile中配置一个环境变量(让sparkSQL知道hdfs在哪里,其实就是namenode在哪里)
export HADOOP_CONF_DIR=Hadoop下conf目录的路径
然后执行source /etc/profile使之生效.
8.重新启动SparkSQL的命令行
此时准备工作就完成了,可以上传一个文件到hive中:
load data local inpath '/home/hadoop/local-file/person.txt' into table t_boy;
上传之后,可以书写sql语句了:
select * from t_boy;
然后可以看到spark-sql会将sql语句转换成RDD提交到集群上运行。
附加
1.在启动spark-sql时,也可以直接指定sql命令,例如:
./spark-sql --master spark://L1:7077,L2:7077 --driver-class-path /home/hadoop/local-jars/mysql-connector-java-5.1.6.jar -e 'show tables;'
还可以将hive的sql语句写在一个文件中执行(用-f这个参数):
./spark-sql --master spark://L1:7077,L2:7077 --driver-class-path /home/hadoop/local-jars/mysql-connector-java-5.1.6.jar -f hive-sqls.sql
-f后面跟的是存放sql语句的文件名。
2.在IDEA中开发,整合hive:
首先要整合hive,必须加入hive的支持,在pom.xml文件中加入下面内容:
<!-- spark如果想整合Hive,必须加入hive的支持 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
然后将hive-site.xml,Hadoop中的core-site.xml,hadoop-site.xml文件拷贝到maven项目中的sources文件夹下:
然后再创建SparkSession时也要开启对hive的支持:
//如果想让hive运行在spark上,一定要开启spark对hive的支持
val spark = SparkSession.builder()
.appName("HiveOnSpark")
.master("local[*]")
.enableHiveSupport()//启用spark对hive的支持(可以兼容hive的语法了)
.getOrCreate()