异常错误
java.lang.IllegalArgumentException: Error while instantiating ‘org.apache.spark.sql.hive.HiveSessionStateBuilder’:

原因
Could not locate executable null\bin\winutils.exe in the Hadoop binaries
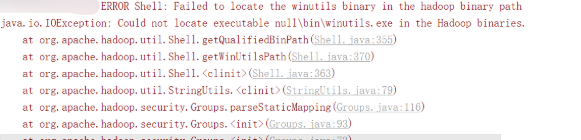
出现这个问题的原因是我们在windows上模拟开发环境,但并没有真正的搭建hadoop和spark
解决方法
下载:https://pan.baidu.com/s/1J5LsROsx6K8C4FUEjBEIYw
提取码:vsj0
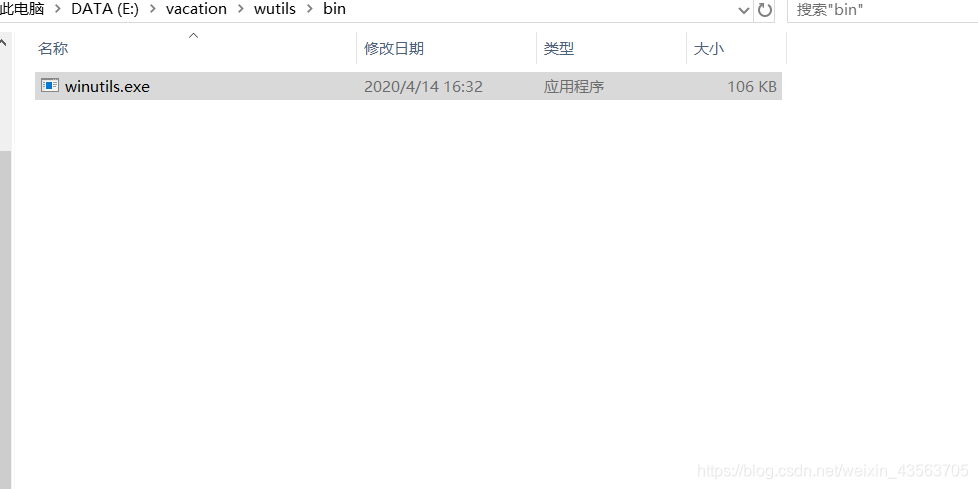
放到任意的目录下,我这里是放到了E:\vacation\wutils\bin
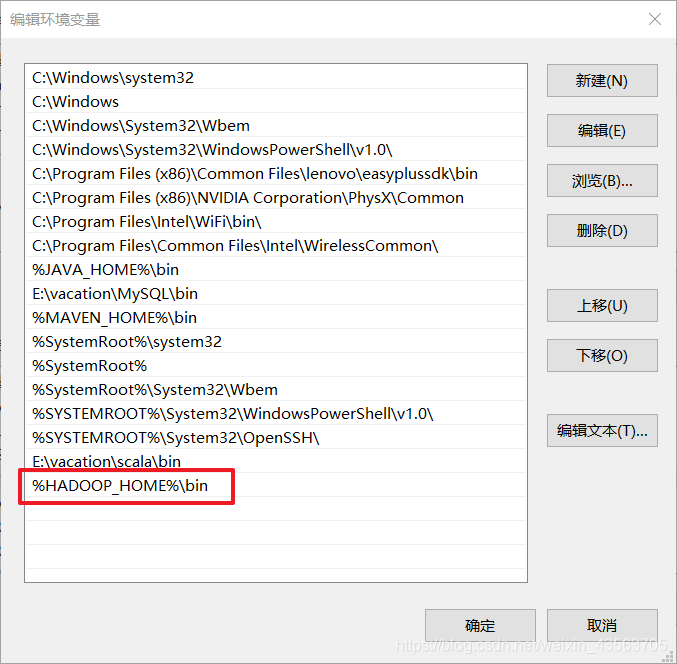
配置环境变量:
新建HADOOP_HOME:

编辑PATH
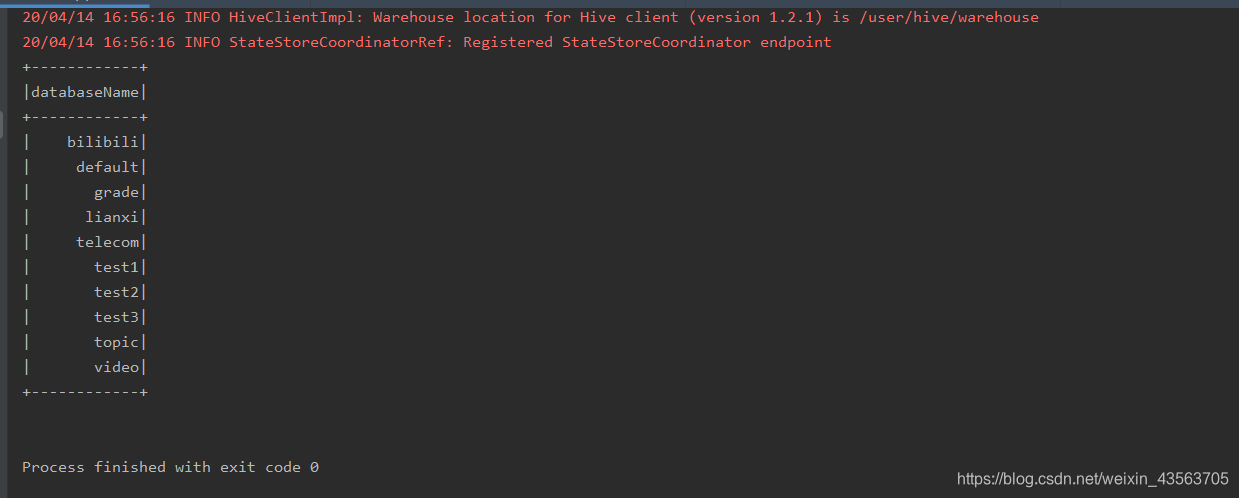
在重启电脑之后-----在运行代码
结果
package com.wzy.code
import org.apache.spark.sql.SparkSession
object HiveSupport {
def main(args: Array[String]): Unit = {
//创建sparkSession
val spark = SparkSession
.builder()
.appName("HiveSupport")
.master("local[*]")
//.config("spark.sql.warehouse.dir", "hdfs://node01:8020/user/hive/warehouse")
//.config("hive.metastore.uris", "thrift://node01:9083")
.enableHiveSupport()//开启hive语法的支持
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
//查看有哪些表
spark.sql("show databases").show()
/*
//创建表
spark.sql("CREATE TABLE person (id int, name string, age int) row format delimited fields terminated by ' '")
//加载数据,数据为当前SparkDemo项目目录下的person.txt(和src平级)
spark.sql("LOAD DATA LOCAL INPATH 'SparkDemo/person.txt' INTO TABLE person")
//查询数据
spark.sql("select * from person ").show()*/
spark.stop()
}
}