原文:https://blog.csdn.net/MrLevo520/article/details/76696073?locationNum=2&fps=1
总结:Hive,Hive on Spark和SparkSQL区别
2017年08月04日 22:36:07 阅读数:18083 标签: sparkmapreducehive大数据 更多
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/MrLevo520/article/details/76696073
Hive on Mapreduce
Hive的原理大家可以参考这篇大数据时代的技术hive:hive介绍,实际的一些操作可以看这篇笔记:新手的Hive指南,至于还有兴趣看Hive优化方法可以看看我总结的这篇Hive性能优化上的一些总结
Hive on Mapreduce执行流程
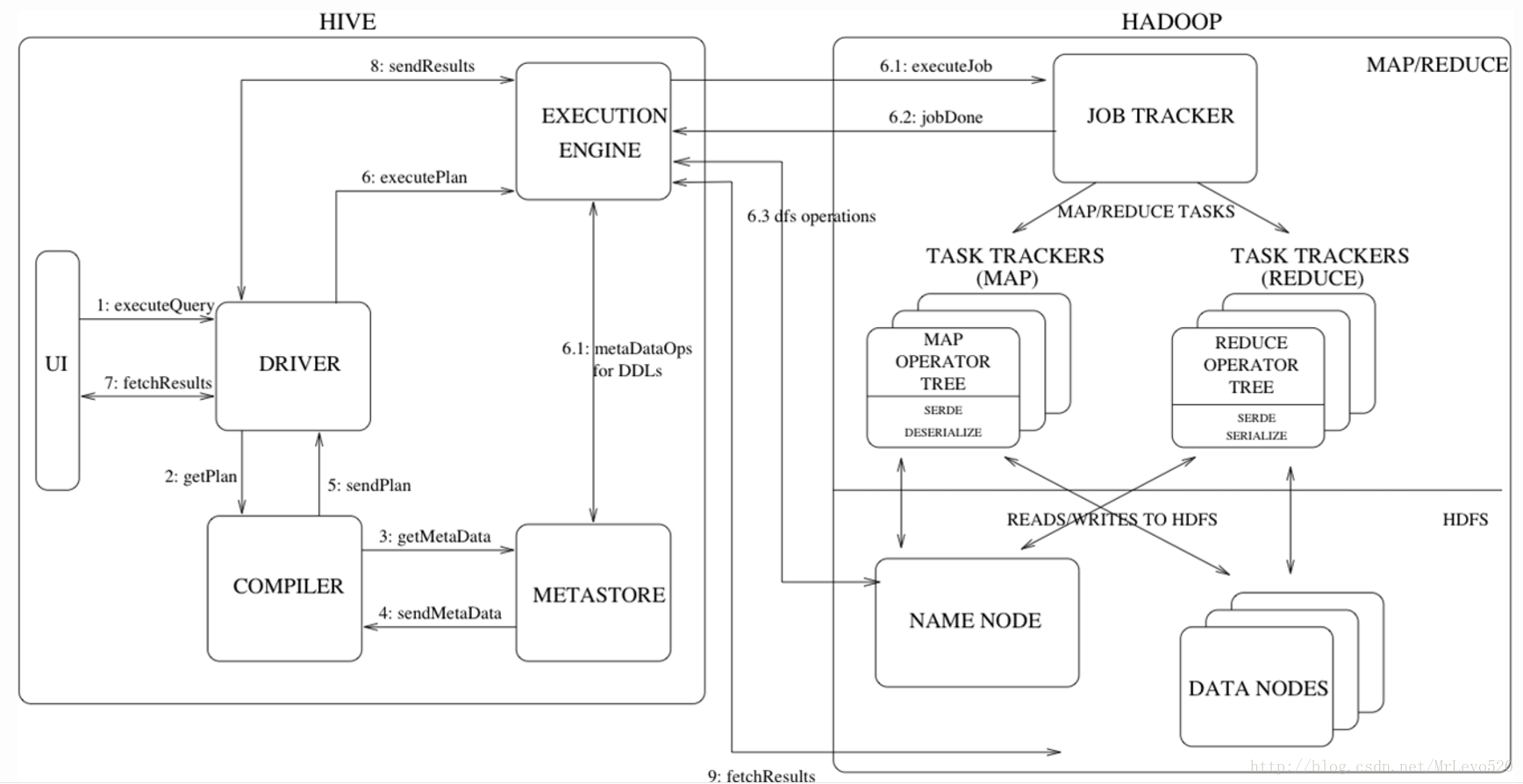
执行流程详细解析
- Step 1:UI(user interface) 调用 executeQuery 接口,发送 HQL 查询语句给 Driver
- Step 2:Driver 为查询语句创建会话句柄,并将查询语句发送给 Compiler, 等待其进行语句解析并生成执行计划
- Step 3 and 4:Compiler 从 metastore 获取相关的元数据
- Step 5:元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词调整分区,生成计划
- Step 6 (6.1,6.2,6.3):由 Compiler 生成的执行计划是阶段性的 DAG,每个阶段都可能会涉及到 Map/Reduce job、元数据的操作、HDFS 文件的操作,Execution Engine 将各个阶段的 DAG 提交给对应的组件执行。
- Step 7, 8 and 9:在每个任务(mapper / reducer)中,查询结果会以临时文件的方式存储在 HDFS 中。保存查询结果的临时文件由 Execution Engine 直接从 HDFS 读取,作为从 Driver Fetch API 的返回内容。
Hive on Mapreduce特点
- 关系数据库里,表的加载模式是在数据加载时候强制确定的(表的加载模式是指数据库存储数据的文件格式),如果加载数据时候发现加载的数据不符合模式,关系数据库则会拒绝加载数据,这个就叫“写时模式”,写时模式会在数据加载时候对数据模式进行检查校验的操作。Hive在加载数据时候和关系数据库不同,hive在加载数据时候不会对数据进行检查,也不会更改被加载的数据文件,而检查数据格式的操作是在查询操作时候执行,这种模式叫“读时模式”。在实际应用中,写时模式在加载数据时候会对列进行索引,对数据进行压缩,因此加载数据的速度很慢,但是当数据加载好了,我们去查询数据的时候,速度很快。但是当我们的数据是非结构化,存储模式也是未知时候,关系数据操作这种场景就麻烦多了,这时候hive就会发挥它的优势。
- 关系数据库一个重要的特点是可以对某一行或某些行的数据进行更新、删除操作,hive**不支持对某个具体行的操作,hive对数据的操作只支持覆盖原数据和追加数据**。Hive也不支持事务和索引。更新、事务和索引都是关系数据库的特征,这些hive都不支持,也不打算支持,原因是hive的设计是海量数据进行处理,全数据的扫描时常态,针对某些具体数据进行操作的效率是很差的,对于更新操作,hive是通过查询将原表的数据进行转化最后存储在新表里,这和传统数据库的更新操作有很大不同。
- Hive也可以在hadoop做实时查询上做一份自己的贡献,那就是和hbase集成,hbase可以进行快速查询,但是hbase不支持类SQL的语句,那么此时hive可以给hbase提供sql语法解析的外壳,可以用类sql语句操作hbase数据库。
- Hive可以认为是MapReduce的一个封装、包装。Hive的意义就是在业务分析中将用户容易编写、会写的Sql语言转换为复杂难写的MapReduce程序,从而大大降低了Hadoop学习的门槛,让更多的用户可以利用Hadoop进行数据挖掘分析。
与传统数据库之间对比—From:Hive和传统数据库进行比较
| 比较项 | SQL | HiveQL |
|---|---|---|
| ANSI SQL | 支持 | 不完全支持 |
| 更新 | UPDATE\INSERT\DELETE | insert OVERWRITE\INTO TABLE |
| 事务 | 支持 | 不支持 |
| 模式 | 写模式 | 读模式 |
| 数据保存 | 块设备、本地文件系统 | HDFS |
| 延时 | 低 | 高 |
| 多表插入 | 不支持 | 支持 |
| 子查询 | 完全支持 | 只能用在From子句中 |
| 视图 | Updatable | Read-only |
| 可扩展性 | 低 | 高 |
| 数据规模 | 小 | 大 |
| …. | …… | …… |
SparkSQL
SparkSQL简介
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,Shark应运而生,但又因为Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),2014年spark团队停止对Shark的开发,将所有资源放SparkSQL项目上
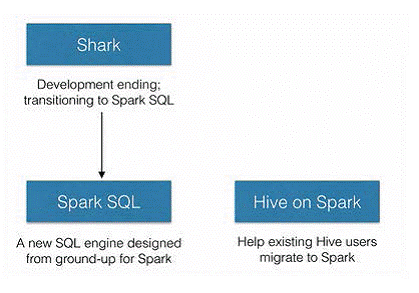
其中SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
-
SparkSQL的两个组件
- SQLContext:Spark SQL提供SQLContext封装Spark中的所有关系型功能。可以用之前的示例中的现有SparkContext创建SQLContext。
- DataFrame:DataFrame是一个分布式的,按照命名列的形式组织的数据集合。DataFrame基于R语言中的data frame概念,与关系型数据库中的数据库表类似。通过调用将DataFrame的内容作为行RDD(RDD of Rows)返回的rdd方法,可以将DataFrame转换成RDD。可以通过如下数据源创建DataFrame:已有的RDD、结构化数据文件、JSON数据集、Hive表、外部数据库。
SparkSQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Operation–>Data Source–>Result的次序来描述的。
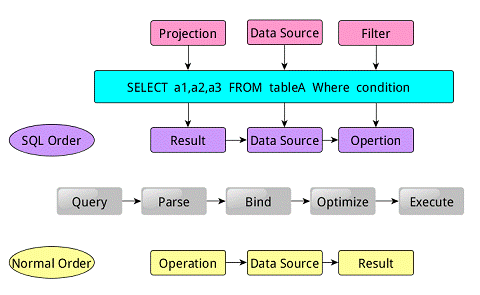
当执行SparkSQL语句的顺序
- 对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
- Projection:简单说就是select选择的列的集合,参考:SQL Projection
- 将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
- 一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
- 计划执行(Execute),按Operation–>Data Source–>Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
Hive on Spark
hive on Spark是由Cloudera发起,由Intel、MapR等公司共同参与的开源项目,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。通过该项目,可以提高Hive查询的性能,同时为已经部署了Hive或者Spark的用户提供了更加灵活的选择,从而进一步提高Hive和Spark的普及率。
Hive on Spark与SparkSql的区别
hive on spark大体与SparkSQL结构类似,只是SQL引擎不同,但是计算引擎都是spark!敲黑板!这才是重点!
我们来看下,在pyspark中使用Hive on Spark是中怎么样的体验
<span style="color:#000000"><code class="language-python"><span style="color:#880000">#初始化Spark SQL</span>
<span style="color:#880000">#导入Spark SQL</span>
<span style="color:#000088">from</span> pyspark.sql <span style="color:#000088">import</span> HiveContext,Row
<span style="color:#880000"># 当不能引入Hive依赖时</span>
<span style="color:#880000"># from pyspark.sql import SQLContext,Row</span>
<span style="color:#880000"># 注意,上面那一点才是关键的,他两来自于同一个包,你们区别能有多大</span>
hiveCtx = HiveContext(sc) <span style="color:#880000">#创建SQL上下文环境</span>
input = hiveCtx.jsonFile(inputFile) <span style="color:#880000">#基本查询示例</span>
input.registerTempTable(<span style="color:#009900">"tweets"</span>) <span style="color:#880000">#注册输入的SchemaRDD(SchemaRDD在Spark 1.3版本后已经改为DataFrame)</span>
<span style="color:#880000">#依据retweetCount(转发计数)选出推文</span>
topTweets = hiveCtx.sql(<span style="color:#009900">"SELECT text,retweetCount FROM tweets ORDER BY retweetCount LIMIT 10"</span>)</code></span>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们可以看到,sqlcontext和hivecontext都是出自于pyspark.sql包,可以从这里理解的话,其实hive on spark和sparksql并没有太大差别
结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序。而且大家的引擎都是spark
SparkSQL和Hive On Spark都是在Spark上实现SQL的解决方案。Spark早先有Shark项目用来实现SQL层,不过后来推翻重做了,就变成了SparkSQL。这是Spark官方Databricks的项目,Spark项目本身主推的SQL实现。Hive On Spark比SparkSQL稍晚。Hive原本是没有很好支持MapReduce之外的引擎的,而Hive On Tez项目让Hive得以支持和Spark近似的Planning结构(非MapReduce的DAG)。所以在此基础上,Cloudera主导启动了Hive On Spark。这个项目得到了IBM,Intel和MapR的支持(但是没有Databricks)。—From SparkSQL与Hive on Spark的比较
Hive on Mapreduce和SparkSQL使用场景
Hive on Mapreduce场景
- Hive的出现可以让那些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户能够在HDFS大规模数据集上很方便地利用SQL 语言查询、汇总、分析数据,毕竟精通SQL语言的人要比精通Java语言的多得多
- Hive适合处理离线非实时数据
SparkSQL场景
- Spark既可以运行本地local模式,也可以以Standalone、cluster等多种模式运行在Yarn、Mesos上,还可以运行在云端例如EC2。此外,Spark的数据来源非常广泛,可以处理来自HDFS、HBase、 Hive、Cassandra、Tachyon上的各种类型的数据。
- 实时性要求或者速度要求较高的场所
Hive on Mapreduce和SparkSQL性能对比
结论:sparksql和hive on spark时间差不多,但都比hive on mapreduce快很多,官方数据认为spark会被传统mapreduce快10-100倍
更新
- 2017.8.4 第一次更新,收集和整理