常用的分类评估指标包括:
- accuracy_score,
- f1_score,
- precision_score,
- recall_score等等。
常用的回归评估指标包括:
- r2_score,
- explained_variance_score等等。
常用的聚类评估指标包括:
-adjusted_rand_score,
- adjusted_mutual_info_score等等
分类模型的评估
模型分类效果全部信息:
-
confusion_matri混淆矩阵,误差矩阵。 -
TP:True Positive真正例FP:False Positive假正例 -
FN:False Negative假反例TN:True Negative真反例
模型整体分类效果: -
accuracy正确率。通用分类评估指标。
模型对某种类别的分类效果:
precision精确率,也叫查准率。模型不把正样本标错的能力。“不冤枉一个好人”。recall召回率,也叫查全率。模型识别出全部正样本的能力。“也绝不放过一个坏人”。f1_scoreF1得分。精确率和召回率的调和平均值。
利用不同方式将类别分类效果进行求和平均得到整体分类效果:
macro_averaged:宏平均。每种类别预测的效果一样重要。micro_averaged:微平均。每一次分类预测的效果一样重要。weighted_averaged:加权平均。每种类别预测的效果跟按该类别样本出现的频率成正 比。sampled_averaged: 样本平均。仅适用于多标签分类问题。根据每个样本多个标签的预测 值和真实值计算评测指标。然后对样本求平均。
仅仅适用于概率模型,且问题为二分类问题的评估方法:
- ROC曲线
- auc_score
from sklearn import metrics
y_pred = [0,0,0,1,1,1,1,1] y_true = [0,1,0,1,1,0,0,1]
print(metrics.confusion_matrix(y_true,y_pred))
print('准确率:',metrics.accuracy_score(y_true,y_pred))
print('类别精度:',metrics.precision_score(y_true,y_pred,average = None)) #不求平均
print('宏平均精度:',metrics.precision_score(y_true,y_pred,average = 'macro'))
print('微平均召回率:',metrics.recall_score(y_true,y_pred,average = 'micro'))
print('加权平均F1得分:',metrics.f1_score(y_true,y_pred,average = 'weighted'))
OUT:
[[2 2] [1 3]]
准确率: 0.625
类别精度: [ 0.66666667 0.6 ]
宏平均精度: 0.633333333333
微平均召回率: 0.625
加权平均F1得分: 0.619047619048
回归模型的评估
回归模型最常用的评估指标有:
- r2_score(R方,拟合优度,可决系数)
- explained_variance_score(解释方差得分)
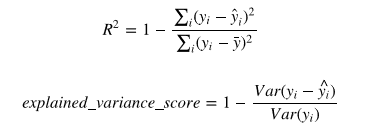
from sklearn.metrics import explained_variance_score
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print('explained_variance_score:',explained_variance_score(y_true, y_pred))
print('r2_score:',r2_score(y_true, y_pred))
OUT:
explained_variance_score: 0.9571734475374732
r2_score: 0.9486081370449679
使用虚拟估计器产生基准得分
对于监督学习(分类和回归),可以用一些基于经验的简单估计策略(虚拟估计)的得分作为参照基准 值。
DummyClassifier 实现了几种简单的分类策略:
- stratified 通过在训练集类分布方面来生成随机预测.
- most_frequent 总是预测训练集中最常见的标签.
- prior 类似most_frequenct,但具有precit_proba方法
- uniform 随机产生预测.
- constant 总是预测用户提供的常量标签.
DummyRegressor 实现了四个简单的经验法则来进行回归:
- mean 总是预测训练目标的平均值.
- median 总是预测训练目标的中位数.
- quantile 总是预测用户提供的训练目标的 quantile(分位数).
- constant 总是预测由用户提供的常数值.
# 让我们创建一个不平衡的数据集:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X, y = iris.data, iris.target
y[y != 1] = -1
#将鸢尾花中0,2类别合并成-1类别
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
print(y)
OUT:
[-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1]
# 比较线性svm分类器和虚拟估计器的得分
from sklearn.dummy import DummyClassifier
from sklearn.svm import SVC
svc = SVC(kernel='linear', C=1).fit(X_train, y_train)
print('linear svc classifier score:',svc.score(X_test, y_test))
dummy = DummyClassifier(strategy='most_frequent',random_state=0)
dummy.fit(X_train, y_train)
print('dummy calssifier score:',dummy.score(X_test, y_test))
OUT:
linear svc classifier score: 0.631578947368421
dummy calssifier score: 0.5789473684210527
#可见线性分类器和虚拟估计器得分没有差太多,改用核函数为rbf的svc
svcrbf = SVC(kernel='rbf', C=1).fit(X_train, y_train)
print('rbf kernel svc score:',svcrbf.score(X_test, y_test))
OUT:
rbf kernel svc score: 0.9736842105263158
欠拟合,过拟合与交叉验证
在机器学习问题中,经常会出现模型在训练数据上的得分很高,
但是在新的数据上表现很差的情况,这称之为过拟合overfitting,又叫高方差high variance。
而如果在训练数据上得分就很低,这称之为欠拟合underfitting,又叫高偏差high bias。
- 留出法
为了解决过拟合问题,常见的方法将数据分为训练集和测试集,用训练集去训练模型的参数,用测 试集去测试训练后模型的表现。
有时对于一些具有超参数的模型(例如svm.SVC的参数C和kernel就 属于超参数),还需要从训练集中划出一部分数据去验证超参数的有效性。
- 交叉验证法
在数据数量有限时,按留出法将数据分成3部分将会严重影响到模型训练的效果。
为了有效利用有 限的数据,可以采用交叉验证cross_validation方法。
交叉验证的基本思想是:以不同的方式多次将数据集划分成训练集和测试集,分别训练和测试,再 综合最后的测试得分。每个数据在一些划分情况下属于训练集,在另外一些划分情况下属于测试 集。
简单的2折交叉验证:把数据集平均划分成A,B两组,先用A组训练B组测试,再用B组训练A组测 试,所以叫做交叉验证.
常用的交叉验证方法:K折(KFold),留一交叉验证(LeaveOneOut,LOO),留P交叉验证 (LeavePOut,LPO),重复K折交叉验证(RepeatedKFold),随机排列交叉验证(ShuffleSplit)。
此外,为了保证训练集中每种标签类别数据的分布和完整数据集中的分布一致,可以采用分层交叉 验证方法(StratifiedKFold,StratifiedShuffleSplit)。
当数据集的来源有不同的分组时,独立同分布假设(independent identical distributed:i.i.d)将被打 破,可以使用分组交叉验证方法来确保测试集合中的的所有样本来自训练样本中没有表示过的新的 分组。(GroupKFold,LeaveOneGroupOut,LeavePGroupsOut,GroupShuffleSplit)
对于时间序列数据,一个非常重要的特点是时间相邻的观测之间的相关性(自相关性),因此用过去 的数据训练而用未来的数据测试非常重要。
TimeSeriesSplit可以实现这样的分割。
# 随机排列交叉验证
import numpy as np
from sklearn.model_selection import ShuffleSplit
X = np.arange(5)
ss = ShuffleSplit(n_splits=10, test_size=0.6, random_state=0)
for train_index, test_index in ss.split(X):
print("%s %s" % (train_index, test_index))
OUT:
[2 3 6 7 8 9] [0 1 4 5]
[0 1 3 4 5 8 9] [2 6 7]
[0 1 2 4 5 6 7] [3 8 9]
# 时间序列分割
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4],[2, 2],[4, 6]]) y = np.array([1, 2, 3, 4, 5, 6, 7, 8])
tscv = TimeSeriesSplit(n_splits=3,max_train_size = 3)
for train_index, test_index in tscv.split(X,y):
print("%s %s" % (train_index, test_index))
OUT:
[0 1] [2 3]
[1 2 3] [4 5]
[3 4 5] [6 7]
交叉验证综合评分
调用 cross_val_score 函数可以计算模型在各交叉验证数据集上的得分。
可以指定metrics中的打分函数,也可以指定交叉验证迭代器。
from sklearn.model_selection import cross_val_score
from sklearn import svm
from sklearn import datasets
iris = datasets.load_iris()
clf = svm.SVC(kernel='linear', C=1)
scores = cross_val_score(clf, iris.data, iris.target, cv=5)
#采用5折交叉验证
print(scores)
#平均得分和 95% 置信区间
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
OUT:
[0.96666667 1. 0.96666667 0.96666667 1. ]
Accuracy: 0.98 (+/- 0.03)
#默认情况下,每个 CV 迭代计算的分数是估计器的 score 方法。
#可以通过使用 scoring 参数来改变计算方式如下
from sklearn import metrics
scores = cross_val_score( clf, iris.data, iris.target, cv=5, scoring='f1_macro')
scores
OUT:
[0.96658312 1. 0.96658312 0.96658312 1. ]
#通过传入一个交叉验证迭代器来指定其他交叉验证策略
from sklearn.model_selection import ShuffleSplit
n_samples = iris.data.shape[0]
ss = ShuffleSplit(n_splits=10, test_size=0.3, random_state=0)
cross_val_score(clf, iris.data, iris.target, cv=ss)
OUT:
[0.97777778 0.97777778 1. 0.95555556 1. 0.97777778
0.97777778 1. 0.97777778 0.97777778]
cross_validate函数和cross_val_score函数类似,但功能更为强大,它允许指定多个指标进行评 估,
并且除返回指定的指标外,还会返回一个fit_time和score_time即训练时间和评分时间
from sklearn.model_selection import cross_validate
from sklearn.metrics import recall_score
clf = svm.SVC(kernel='linear', C=1, random_state=0)
scores = cross_validate(clf, iris.data, iris.target, scoring=['f1_macro','f1_micro'], cv=10, return_train_score=False)
print(sorted(scores.keys()))
#scores['test_recall_macro']
print(scores['fit_time']) #训练集拟合时间
print(scores['score_time']) #测试集评分时间
print('f1_micro:',scores['test_f1_micro'])
print('f1_macro:',scores['test_f1_macro'])
OUT:
['fit_time', 'score_time', 'test_f1_macro', 'test_f1_micro']
[0.00099921 0. 0.00099874 0. 0.00099897 0.00099897
0. 0.00099993 0. 0.00099945]
[0.00099969 0.00199819 0.00099921 0.00199842 0.00099897 0.00099921
0.00199795 0.0009985 0.00199842 0.00099897]
f1_micro: [1. 0.93333333 1. 1. 0.86666667 1.
0.93333333 1. 1. 1. ]
f1_macro: [1. 0.93265993 1. 1. 0.86111111 1.
0.93265993 1. 1. 1. ]
使用cross_val_predict可以返回每条样本作为CV中的测试集时,对应的模型对该样本的预测结果。
这就要求使用的CV策略能保证每一条样本都有机会作为测试数据,否则会报异常。
from sklearn import metrics
from sklearn.model_selection import cross_val_predict
predicted = cross_val_predict(clf, iris.data, iris.target, cv=10)
print(predicted)
print(metrics.accuracy_score(iris.target, predicted))
OUT:
0.9733333333333334