假如我们有一个带标签的数据集D,我们如何选择最优的模型? 衡量模型好坏的标准是看这个模型在新的数据集上面表现的如何,也就是看它的泛化误差。因为实际的数据没有标签,所以泛化误差是不可能直接得到的。于是我们需要在数据集D上面划分出来一小部分数据测试D的性能,用它来近似代替泛化误差。
留出法
留出法的想法很简单,将原始数据直接划分为互斥的两类,其中一部分用来训练模型,另外一部分用来测试。前者就是训练集,后者就是测试集。通常训练集和测试集的比例为7:3。
需要注意:训练\测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。那么问题来啦,什么叫保持一致性?譬如在分类过程中,要保证训练集和测试集中每一类的比例要和总样本中每一类的比例保持一致,这样的采样方式成为分层采样。
要注意,train_test_split没有采用分层采样,相当于对数据集进行了shuffle后按照给定的test_size进行数据集划分。
from sklearn import datasets #数据集模块
from sklearn.model_selection import train_test_split #训练集和测试集分割模块
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
train_x,test_x,train_y,test_y = train_test_split(iris_x,iris_y,test_size=0.3)
KNN = KNeighborsClassifier(n_neighbors=5)
KNN.fit(train_x,train_y)
print(KNN.score(test_x,test_y))
0.9555555555555556
留出法非常的简单。但是存在一些问题,比如有些模型还需要进行超参数评估,这个时候还需要划分一类数据集,叫做验证集。最后数据集的划分划分变成了这样:训练集,验证集还有测试集。 训练集是为了进行模型的训练,验证集是为了进行参数的调整,测试集是为了看这个模型的好坏。
但是,上面的划分依然有问题,划分出来验证集还有测试集,那么我们的训练集会变小。并且还有一个问题,那就是我们的模型会随着我们选择的训练集和验证集不同而不同。所以这个时候,我们引入了交叉验证。
交叉验证法数据集切分策略
1、 KFold方法 K折交叉验证
将数据集分为k等份,对于每一份数据集,其中k-1份用作训练集,单独的那一份用作测试集。
sklearn中的方法实现为
from sklearn.model_selection import KFold
kf = KFold(n_splits=2)
2、 RepeatedKFold p次k折交叉验证
在实际当中,我们只进行一次k折交叉验证还是不够的,我们需要进行多次,最典型的是:10次10折交叉验证,RepeatedKFold方法可以控制交叉验证的次数。
sklearn中的方法实现为
from sklearn.model_selection import RepeatedKFold
kf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=0)
3、 LeaveOneOut 留一法
留一法是k折交叉验证当中,k=n(n为数据集个数)的情形
sklearn中的方法实现为
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
4、 LeavePOut 留P法
和留一法原理类似,只不过每次测试集抽取的样本数由1变为P
sklearn中的方法实现为
from sklearn.model_selection import LeavePOut
loo = LeavePOut(p=2)
5、 ShuffleSplit 随机分配
使用ShuffleSplit方法,可以随机的把数据打乱,然后分为训练集和测试集。它还有一个好处是可以通过random_state这个种子来重现我们的分配方式,如果没有指定,那么每次都是随机的。
sklearn中的方法实现为
from sklearn.model_selection import ShuffleSplit
ss = ShuffleSplit(n_splits=4, random_state=0, test_size=0.25)
6、 StratifiedKFold 分层k折交叉验证
StratifiedKFold用法类似Kfold,但是他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同。
sklearn中的方法实现为
from sklearn.model_selection import StratifiedKFold
sk = StratifiedKFold(n_splits=4, random_state=0)
哈哈哈,重点来啦,以下是对上述划分数据集的个人理解
1、对于KFold,它不会考虑分层采样,这样会引入误差。如下所示:
X = [1,2,3,4,5,6,7,8,9,10,11,12]
y = [1,1,1,0,1,0,1,1,1,0,1,0]
kf = KFold(n_splits=4)
for train_index, test_index in kf.split(X,y):
print('train_index', train_index, 'test_index', test_index)
train_index [ 3 4 5 6 7 8 9 10 11] test_index [0 1 2]
train_index [ 0 1 2 6 7 8 9 10 11] test_index [3 4 5]
train_index [ 0 1 2 3 4 5 9 10 11] test_index [6 7 8]
train_index [0 1 2 3 4 5 6 7 8] test_index [ 9 10 11]
我们可以看到,它只是依次的选取测试集,剩下的即为训练集。不会考虑总样本中各个类别所占的比例。
如果令shuffle=True,则随机采样。
如果令random_state为一个常值,则每次得到的结果都一样,否则每一次得到的划分结果都不一样。
2、如果想考虑分层采样,那就要采用StratifiedKFold,如下所示
X = [1,2,3,4,5,6,7,8,9,10,11,12]
y = [1,1,1,0,1,0,1,1,1,0,1,0]
sf = StratifiedKFold(n_splits=4)
for train_index, test_index in sf.split(X,y):
print('train_index', train_index, 'test_index', test_index)
train_index [ 2 4 5 6 7 8 9 10 11] test_index [0 1 3]
train_index [ 0 1 3 6 7 8 9 10 11] test_index [2 4 5]
train_index [ 0 1 2 3 4 5 8 10 11] test_index [6 7 9]
train_index [0 1 2 3 4 5 6 7 9] test_index [ 8 10 11]
从上面可以看出,每一次划分之后,训练集和测试集中各个类别的比例都与总样本中各个类别的比例相同。这样就可以避免一些误差。
如果令shuffle=True,则随机采样。但不同于KFold,即使随机采样,也要符合分层采样的原则。
如果令random_state为一个常值,则每次得到的结果都一样,否则每一次得到的划分结果都不一样。
3、ShuffleSplit
随机划分。它与Kfold的区别是:KFold中的k个测试集必须互斥,而这个里面不用保证互斥。
同样,如果random_state为一个常值int,那么每次分组的结果都一样。即可以通过random_state这个种子来重现我们的分配方式,如果没有指定,那么每次都是随机的。
X = [1,2,3,4,5,6,7,8,9,10,11,12]
y = [1,1,1,0,1,0,1,1,1,0,1,0]
ss = ShuffleSplit(n_splits=4,test_size=0.25)
for train_index, test_index in ss.split(X,y):
print('train_index', train_index, 'test_index', test_index)
train_index [ 9 10 7 1 2 5 11 0 6] test_index [8 3 4]
train_index [ 7 10 5 6 8 3 1 9 4] test_index [ 2 11 0]
train_index [ 4 10 1 11 8 3 7 9 6] test_index [5 0 2]
train_index [ 4 2 3 7 11 6 9 8 1] test_index [ 0 5 10]
交叉验证
上面讲的是如何使用交叉验证进行数据集的划分。当我们用交叉验证的方法并且结合一些性能度量方法来评估模型好坏的时候,我们可以直接使用sklearn当中提供的交叉验证评估方法,这些方法如下:
1、cross_value_score
利用交叉验证对某个超参数模型进行打分。
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets #数据集模块
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
knn = KNeighborsClassifier(n_neighbors=5)
print(cross_val_score(knn,iris_x,iris_y,cv=10,scoring='accuracy'))
print(cross_val_score(knn,iris_x,iris_y,cv=10,scoring='accuracy').mean())
[1. 0.93333333 1. 1. 0.86666667 0.93333333
0.93333333 1. 1. 1. ]
0.9666666666666668
当cv为int型时,默认使用KFold或StratifiedKFold。默认是以scoring=’f1_macro’进行评测的。所有的打分选项如下:
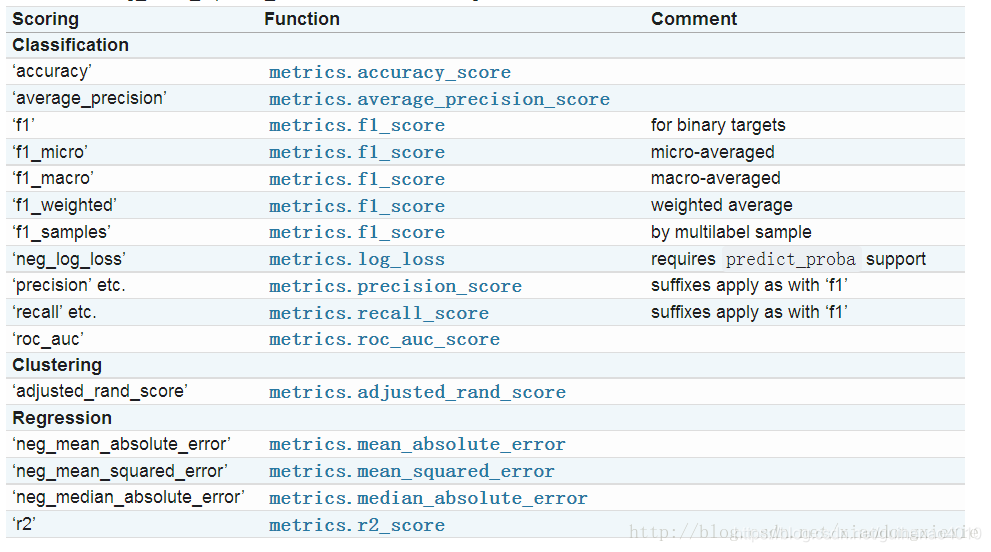
最喜欢的个人理解又来啦_?_
我们知道交叉验证是为了验证摸个模型超参数条件下的模型是否训练的比较好。因此我们可以设置一个循环,循环变量为超参数的取值,便可以得到一系列交叉验证的结果。由此便可以得到交叉验证结果最好的那个超参数。
2、validation_curve
这个就是交叉验证曲线,跟我们上面设置循环变量的方法一致。不得不感叹sklearn真的很强大啊。
from sklearn import datasets #数据集模块
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import validation_curve
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
para_range = np.arange(1,30)
train_loss,test_loss = validation_curve(KNeighborsClassifier(),iris_x,iris_y,
param_name='n_neighbors',param_range=para_range,
cv=10,scoring='accuracy')
train_accuracy = np.mean(train_loss,axis=1)
test_accuracy = np.mean(test_loss,axis=1)
plt.plot(train_accuracy,color='r',label='train')
plt.plot(test_accuracy,color='b',label='test')
plt.xlabel('n_neighbors')
plt.ylabel('accuracy')
plt.legend()
plt.show()
其中param_range为超参数的取值范围,param_name为要改变的超参数的名称。
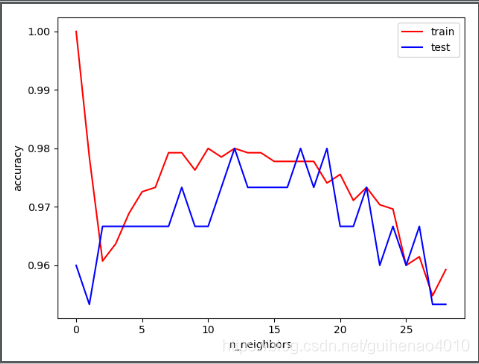
验证曲线和学习曲线的区别是,横轴为某个超参数的一系列值,由此来看不同参数设置下模型的准确率,而不是不同训练集大小下的准确率。
从验证曲线上可以看到随着超参数设置的改变,模型可能从欠拟合到合适再到过拟合的过程,进而选择一个合适的设置,来提高模型的性能。
需要注意的是如果我们使用验证分数来优化超参数,那么该验证分数是有偏差的,它无法再代表模型的泛化能力,我们就需要使用其他测试集来重新评估模型的泛化能力。
3、learning_curve 学习曲线
学习曲线可以判断我们的模型是处于过拟合还是欠拟合的状态。
rom sklearn.model_selection import learning_curve
import numpy as np
from sklearn import datasets #数据集模块
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
train_sizes, train_loss, test_loss = learning_curve(
KNeighborsClassifier(n_neighbors=5), iris_x, iris_y, cv=10, scoring='neg_mean_squared_error',
train_sizes=[0.1, 0.15, 0.25, 0.35,0.45,0.55,0.65,0.75,0.85, 1])
train_loss = -np.mean(train_loss,axis=1)
test_loss = -np.mean(test_loss,axis=1)
plt.plot(train_sizes,train_loss,color='r',label='training')
plt.plot(train_sizes,test_loss,color='g',label='cross_validation')
plt.xlabel('size')
plt.ylabel('accuracy')
plt.legend()
plt.show()
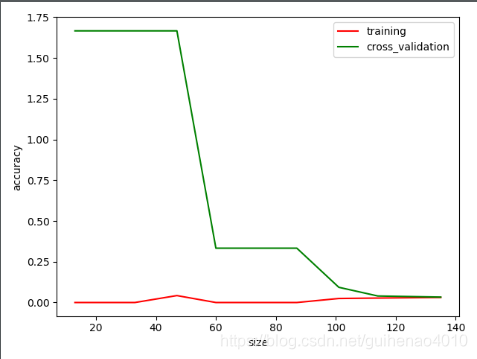
总结:
学习曲线Learning Curve:评估样本量和指标的关系
验证曲线validation Curve:评估参数和指标的关系