pandas数据清理和计算
1. dataframe.merge:根据一个或多个键将不同dataframe的列连接起来
语法:DataFrame.merge(left,right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(’_x’, ‘_y’), copy=True, indicator=False, validate=None)
参数说明:
left与right:需要合并的两个DataFrame
how:指的是合并(连接)的方式,有inner(内连接,即只保留键的交集),left(以左边键为基准,如果右边的键在左边能找到,则保留,否则不保留),right(右外连接),outer(保留键的并集);默认为inner
on : 指的是用于连接的列索引名称。必须存在右右两个DataFrame对象中,如果没有指定且其他参数也未指定,则以两个DataFrame的列名交集做为连接键
left_on:键名/键名列表,指明左侧DataFrame中需要连接的是哪些列
right_on:键名/键名列表,指明右侧DataFrame中需要连接的是哪些列
left_index:布尔值,指明是否使用左侧DataFrame键名做新键名
right_index:布尔值,指明是否使用右侧DataFrame键名做新键名
sort:默认为True,将合并的数据进行排序。在大多数情况下设置为False可以提高性能
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(’_x’,’_y’)
#实例
import pandas as pd
import numpy as np
from pandas import DataFrame
left_df=DataFrame(np.random.randint(0,20,20).reshape(5,4),index=list('abcde'),columns=list('pqxy'))
right_df=DataFrame(np.random.randint(0,20,20).reshape(5,4),index=list('cdefg'),columns=list('qxyz'))
merged=pd.merge(left_df,right_df,on='x',how='outer')
merged2=pd.merge(left_df,right_df,on='x',how='left')
merged3=pd.merge(left_df,right_df,left_on='p',right_on='z',how='left')
print(left_df)
print(right_df)
print('merged_outer',merged)
print('merged_outer',merged2)
print('merged_inner',merged3)
#输出:
p q x y
a 11 9 17 0
b 15 16 5 7
c 6 15 17 8
d 13 17 11 17
e 17 17 18 5
q x y z
c 17 17 7 4
d 14 8 13 2
e 3 6 19 13
f 4 12 7 18
g 7 15 1 18
merged_outer :代码含义:将两个df在‘x’列上合并,合并的方法是‘outer,得出的效果是:保留两个df的x列的并集,q_x,y_x 是左边df的列,q_y,y_y是右边df的;列,空值用NAN填充
p q_x x y_x q_y y_y z
0 11.0 9.0 17 0.0 17.0 7.0 4.0
1 6.0 15.0 17 8.0 17.0 7.0 4.0
2 15.0 16.0 5 7.0 NaN NaN NaN
3 13.0 17.0 11 17.0 NaN NaN NaN
4 17.0 17.0 18 5.0 NaN NaN NaN
5 NaN NaN 8 NaN 14.0 13.0 2.0
6 NaN NaN 6 NaN 3.0 19.0 13.0
7 NaN NaN 12 NaN 4.0 7.0 18.0
8 NaN NaN 15 NaN 7.0 1.0 18.0
merged_left 代码含义:将两个df在‘x’列上合并,合并的方法是‘left,得出的效果是:保留左边df的x列的所有值,右边x列的值如果在左边x列能找到,则保留,否则,不保留,q_x,y_x 是左边df的列,q_y,y_y是右边df的;
merged_outer
p q_x x y_x q_y y_y z
0 11 9 17 0 17.0 7.0 4.0
1 15 16 5 7 NaN NaN NaN
2 6 15 17 8 17.0 7.0 4.0
3 13 17 11 17 NaN NaN NaN
4 17 17 18 5 NaN NaN NaN
merged_inner:left_on,right_,指明左右两个df需要合并的列,方法为left,保留左边df的p列的所有值,右边Z列的值如果在左边x列能找到,则保留,否则,不保留,q_x,y_x 是左边df的列,q_y,y_y是右边df的,空值用NAN填充
p q_x x_x y_x q_y x_y y_y z
0 11 9 17 0 NaN NaN NaN NaN
1 15 16 5 7 NaN NaN NaN NaN
2 6 15 17 8 NaN NaN NaN NaN
3 13 17 11 17 3.0 6.0 19.0 13.0
4 17 17 18 5 NaN NaN NaN NaN
参考这个教程:https://www.yiibai.com/pandas/python_pandas_merging_joining.html
2. dataframe.join():根据一个或多个键将不同dataframe的行连接起来,按索引合并
语法:DataFrame.join(other, on=None, how=‘left’, lsuffix=’’, rsuffix=’’, sort=False)
other:其他需要连接的dataframe
lsuffix: str
rsuffix:str
how={‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘left’
代码释义: 连接左右两个df,保留右边df所有索引,左边df的索引如果能在右边找到,则保留,否则不保留
left_df=DataFrame(np.random.randint(0,20,20).reshape(5,4),index=list('abcde'),columns=list('pqxy'))
right_df=DataFrame(np.random.randint(0,20,20).reshape(5,4),index=list('cdefg'),columns=list('qxyz'))
joined=left_df.join(right_df,lsuffix='left',rsuffix='right',how='right')
print(left_df)
print(right_df)
print('joined_outer',joined)
#输出:
p q x y
a 7 7 3 6
b 2 11 4 2
c 1 2 9 7
d 16 14 7 5
e 11 17 7 12
q x y z
c 10 17 1 3
d 3 4 13 14
e 1 6 3 9
f 2 1 13 19
g 2 1 1 14
joined_outer
p qleft xleft yleft qright xright yright z
c 1.0 2.0 9.0 7.0 10 17 1 3
d 16.0 14.0 7.0 5.0 3 4 13 14
e 11.0 17.0 7.0 12.0 1 6 3 9
f NaN NaN NaN NaN 2 1 13 19
g NaN NaN NaN NaN 2 1 1 14
3. pandas.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False)
作用:将两个DF首尾相接
objs:需要连接的series/dataframe组成的列表
axis : {0/’index’, 1/’columns’}, default 0
join={‘inner’, ‘outer’}, default ‘outer’
join_axes : 需要连接的索引/索引列表,如传入,则需定义axis
ignore_index:bool值,默认false,即不以原df的索引做索引
keys:sequence,用于多层索引的df ,
sort :布尔值,默认none
#
df1=DataFrame(np.random.randint(0,20,20).reshape(5,4),index=list('abcde'),columns=list('pqxy'))
df2=DataFrame(np.random.randint(0,20,20).reshape(5,4),index=list('cdefg'),columns=list('qxyz'))
concated=pd.concat([df1,df2],join_axes=[df1.index],axis=1)
print(concated)
#输出:
p q x y q x y z
a 6 9 11 9 NaN NaN NaN NaN
b 19 10 17 14 NaN NaN NaN NaN
c 15 13 12 12 14.0 1.0 4.0 6.0
d 11 3 12 4 6.0 3.0 13.0 11.0
e 14 7 10 7 15.0 3.0 8.0 2.0
4. DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
dataframe:原对象
other : DataFrame or Series/dict-like object, or list of these 需要添加的对象
ignore_index : boolean, default False
If True, do not use the index labels.
verify_integrity : boolean, default False
If True, raise ValueError on creating index with duplicates.
sort : boolean, default None
#实例:
df1=DataFrame(data=[['a0','b0','c0','d0'],['a1','b1','c1','d1'],['a2','b2','c2','d2'],['a3','b3','c3','d3']],index=[0,1,2,3],columns=["A",'B','c','d'])
df2=DataFrame(data=[['a4','b4','c4','d4'],['a5','b5','c5','d5'],['a6','b6','c6','d6'],['a7','b7','c8','d9']],index=[2,3,5,7],columns=["A",'B','c','d'])
print(df1.append(df2))
#输出:
A B c d
0 a0 b0 c0 d0
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
2 a4 b4 c4 d4
3 a5 b5 c5 d5
5 a6 b6 c6 d6
7 a7 b7 c8 d9
5. dataframe.stack() ,数据的堆叠,dataframe.stack() 数据的呃平铺平铺
DataFrame.stack(level=-1, dropna=True)
数据层次化格式有两种:
结构一:花括号
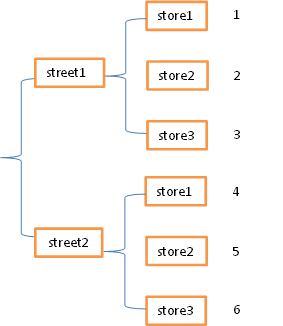
结构2:表格型
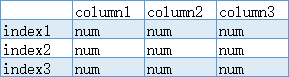
stack和unstack的作用就是在这两种结构间转换
import pandas as pd
import numpy as np
data=pd.Series(np.random.randn(10),index=[["a","a","a","b","b","b","c","c","d","d"],[1,2,3,1,2,3,1,2,2,3]])
print(data)
print(data.unstack())
print(data.unstack().stack())
#输出:
a 1 -0.906812
2 -0.810398
3 0.774799
b 1 -0.533640
2 0.552980
3 0.296164
c 1 -0.789318
2 0.615479
d 2 -0.258791
3 0.126236
dtype: float64
1 2 3
a -0.906812 -0.810398 0.774799
b -0.533640 0.552980 0.296164
c -0.789318 0.615479 NaN
d NaN -0.258791 0.126236
a 1 -0.906812
2 -0.810398
3 0.774799
b 1 -0.533640
2 0.552980
3 0.296164
c 1 -0.789318
2 0.615479
d 2 -0.258791
3 0.126236
dtype: float64
6. dataframe.pivot()轴向转换
df.pivot(index,columns,values): 将index指定为行索引,columns是列索引,values则是DataFrame中的值
import pandas as pd
from pandas import DataFrame
import numpy as np
df=DataFrame({"种类":['a','a','b','b','c','c'],'信息':['price','qty','price','qty','price','qty'],'值':['4','3','5','4','6','5']})
print(df)
print(df.pivot("信息",'种类','值'))
#输出:
种类 信息 值
0 a price 4
1 a qty 3
2 b price 5
3 b qty 4
4 c price 6
5 c qty 5
种类 a b c
信息
price 4 5 6
qty 3 4 5