Pandas 是 Python 中基于Numpy构建的数据操纵和分析软件包,包含使数据分析工作变得快速简洁的高级数据结构和操作工具。通过Pandas Series 和 Pandas DataFrame这两个数据结构,我们可以轻松直观地处理带标签数据和关系数据。本节主要介绍Pandas Series的基本使用。
Pandas Series
Pandas Series是一种类似于数组的一维对象,可以存储不同类型的数据。其中,Series对象的数据存在一组与之关联的数据标签(索引),通过Series的values和index能够获取其数组表示形式和索引对象。你可以为Pandas Series 中的每个元素指定索引,并通过索引选取Series中的单个或一组值。
首先,在 Python 中导入 Pandas,通常使用pd导入 Pandas。
import pandas as pd
使用 pd.Series(data, index) 命令创建 Pandas Series, index 是一个索引标签列表。
我们创建 一个Pandas Series 对象来存储商品信息,其中单价为数据,商品名为索引标签。
import pandas as pd goods = pd.Series(data = [39,8,15], index = ['pen', 'ice cream', 'notebook']) goods
运行结果:

如果不指定索引标签,则默认索引从0开始。
import pandas as pd words = pd.Series(data = ['a','b','c','d']) words

我们还可以单独输出 Pandas Series 的索引标签和数据来查看详细内容。
print('商品单价:', goods.values) print('商品名:', goods.index)
运行结果:
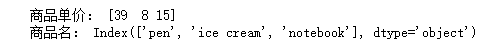
如果你不清楚是否存在某个索引标签,可以使用 in命令来判断该标签是否存在:
aa = 'notebook' in goods bb = 'milk' in goods cc = 'pen' in goods print(aa,bb,cc)
运行结果:
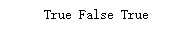
Pandas Series 的算术运算
还是使用上面存储商品信息的实例,我们来对其进行元素级算术运算。
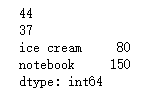
print(goods + 1) print() print(goods - 2) print() print(goods * 3) print() print(goods / 4)
运行结果:

除此之外, 我们也可以对Series对象的部分条目应用算术运算。如下所示:
print(goods['pen'] + 5) print(goods.iloc[0] - 2) print(goods[['ice cream', 'notebook']] * 10)
运行结果: