第三十三周学习笔记
CS231n
Deep Learning Software
CPU vs GPU
CPU:Fewer cores,but each core is much faster and much more capable;great at sequential tasks
GPU:More cores,but each core is much slower and “dumber”;great for parallel tasks(matrix multiplicatio)
在课程中的对比中:
- 使用cuDNN比仅仅使用CUDA快了3倍多
问题:如果不够仔细,可能会导致训练由于读取数据并转移到GPU上出现瓶颈
Solution:
- 读取所有数据到内存(小数据集)
- 使用SSD而不是HDD
- 使用多个CPU线程来读取数据
深度学习框架
使用深度学习框架的原因
- 更容易建立大的计算图
- 更容易计算梯度
- 在GPU上更高效
TensorFlow
by Google
高层封装
- Kears
- TFLearn
- TensorLayer
- tf.layers
- TF-Slim
- tf.contrib.learn
- Pretty Tensor
- Sonnet
类似的框架有Theano
Pytorch
by Facebook
问题:Pytorch与tensorflow有何不同?
tensorflow先建立计算图然后反复运行计算图(静态图),pytorch每次运算的时候都建立一个新的计算图(动态图),这使得代码更简洁
Static vs Dynamic
Optimization,静态图可以在运行之前做好优化
Serialization,静态图建立后,可以序列化并且不使用建立网络的代码即可运行,动态图需要一直保留建立网络的代码
Conditional,动态图方便使用条件语句,静态图不方便
loops,动态图方便循环,静态图不方便
Caffe
by UC Berkeley
- 主要用C++写的
- 有Python和MATLAB接口
- 善于训练和微调前向分类模型
- 通常不用写代码????
- 研究中不再有很多使用了,但经常用来部署模型
Caffe2
by Facebook
- 静态图,类似TensorFlow
- 主要用C++写的
- 好的Python接口
- 可以在Python中训练模型,然后序列化和部署时不需要Python
- 在IOS/Android上运行
Adivice
- tensorflow适用于多数项目,社区庞大,也有很多高层封装
- Pytorch适用于研究,但尚在成长
- 在生产环境中考虑Caffe,Caffe2,Tensoflow
- 在手机上考虑TensorFlow或Caffe2
CNN architecture
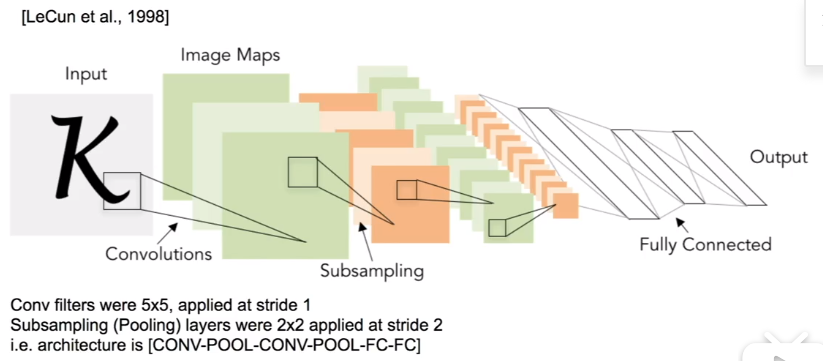
LeNet-5
AlexNet
第一个在ImageNet分类上表现好的大规模卷积网络
Architecture:
CONV1-MAX POOL1-NORM1-CONV2-MAX POOL2-NORM2-CONV3-CONV4-CONV5-MAX POOL3-FC6-FC7-FC8
与LeNet相似,只是更深
细节
- ReLU的第一次出场
- 使用Norm层(当前不再流行)
- 使用较多数据增强
- 因为在GTX580上训练,显存只有3GB,所以网络被分成了两份在两个GPU上分别训练,因此AlexNet的图例看起来有两个部分

2013年的冠军ZFNET基本上是对AlexNet的超参数进行调整得到的结果
2014年的赢家是GoogleNet,VGG表现也很接近,它们都是更深的网络
VGGNet
AlexNet 8层->VGGNet 16-19层

细节
- ILSVRC’14 2nd in classification, 1st in localization
- VGG19比VGG16提高了一点,需要更多内存
- FC1000之前的FC4096 generalize well to other tasks
GoogLeNet
更深的网络
- 22层
- 高效的Inception模块
- 没有全连接层
- 仅仅5百万个参数,比AlexNet少12倍
- ILSVRC’14 分类的冠军
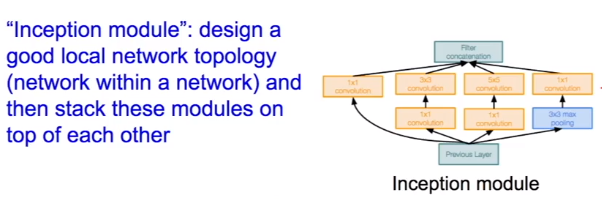
在直接进行卷积前,使用bottleneck层来降低输入的深度维数,从而减少计算的复杂度,bottleneck就是1×1的卷积,在维持空间维度的基础上改变深度维
GoogLeNet堆叠这种Inception模块来得到整个网络
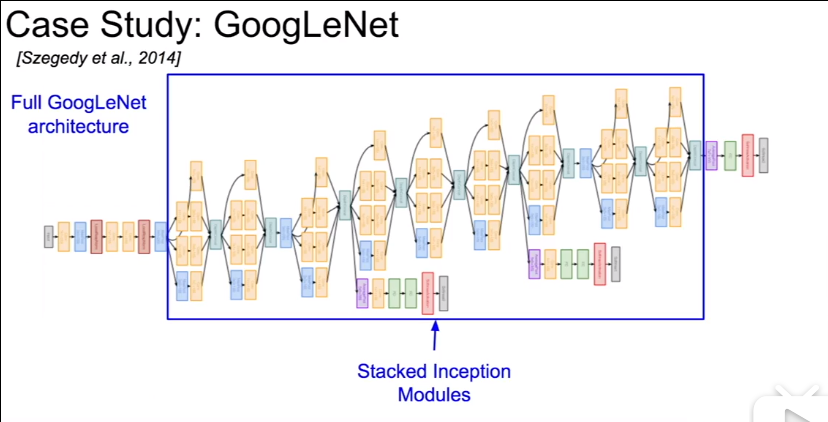
其中除了最终的分类输出外,还有两个辅助的分类部分
ResNet
非常深的网络,使用余量连接(residual connections)
- 152层
- ILSVRC’15 分类冠军
- Won everything (ISVRC’15 COCO’15)
问题:使用更深的网络并不能得到更好的效果,而这并不是因为过拟合
假设:这是因为更深的网络更难优化
- 更深的网络应该至少和浅的网络一样好
- 一个解决方法是将浅层模型的学习结果和一些恒等映射结合成更深的模型
解决方法:让网络拟合余量映射F(x)=H(x)-x(residual mapping)而不是直接映射H(x)(underlying mapping)
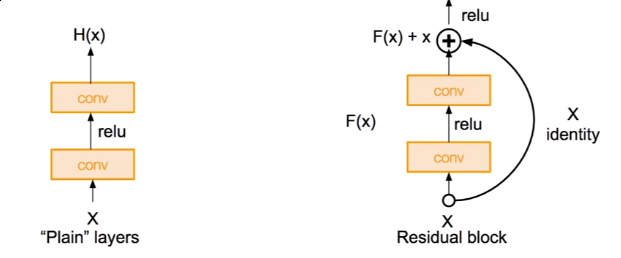
ResNet也使用了bottleneck的技术
值得注意的是:如果我们将ResNet的权值设置为0,那么就得到了一个恒等映射,这使得L2正则化有了另外的意义(让模型取向学习到恒等映射)
训练细节
- 每个CONV层后有Batch Normalization
- Xavier/2初始化
- SGD + Momentum(0.9)
- 学习率0.1,当验证误差不动时除以10
- Mini-batch size 256
- Weight decay 1e-5
- 没有Dropout
Summary:CNN Architectures
Case Studies
- AlexNet
- VGG
- GoogLeNet
- ResNet
Also…
- NiN(Network in Network)
- Wide REsNet
- ResNeXT
- Stochastic Depth
- DenseNet
- FractalNet
- SqueezeNet
Recurrent Neural Networks
RNN处理序列的网络,可以实现one to one,one to many(e.g. Image Captioning),many to one(e.g Sentiment Classification),many to many(e.g. Machine Translation)
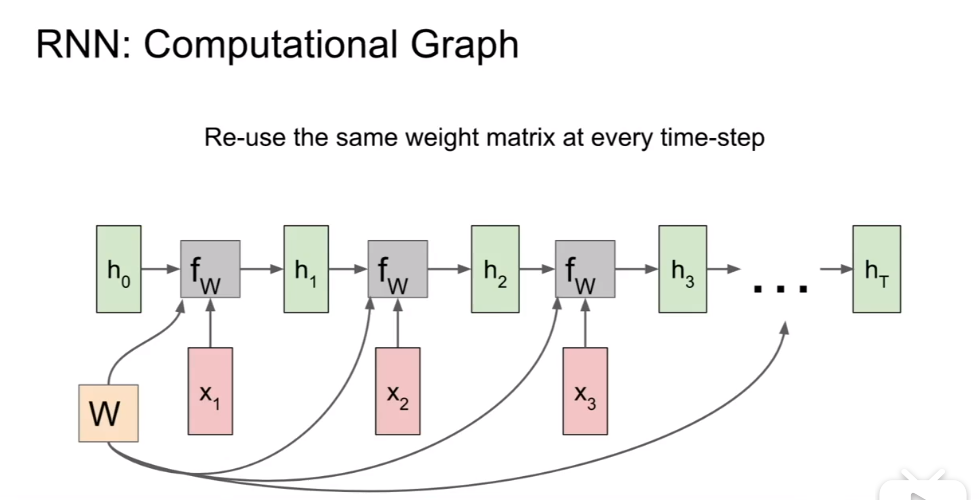
前向传播
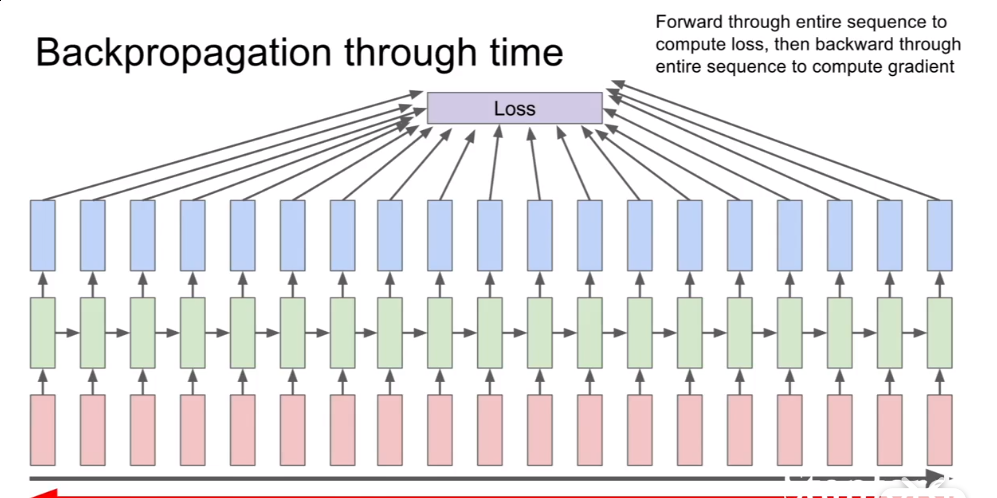
反向传播
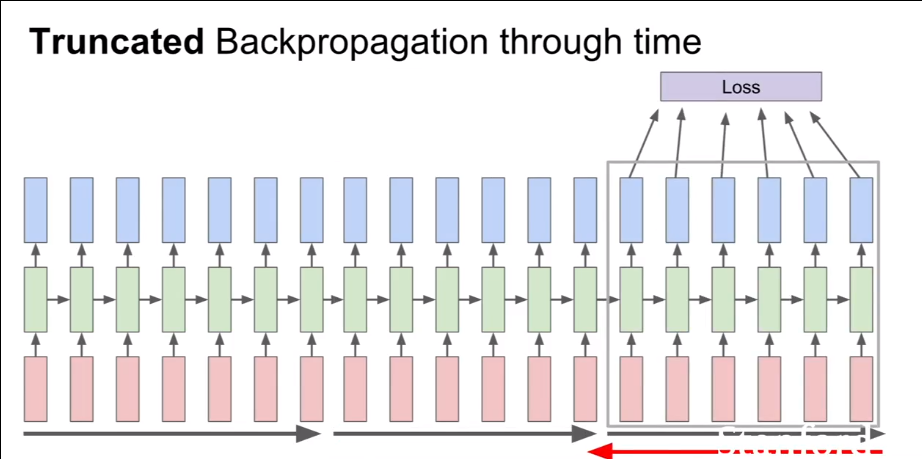
当序列太长的时候,使用Truncated Backpropagation
Vanilla RNN Gradient FLow
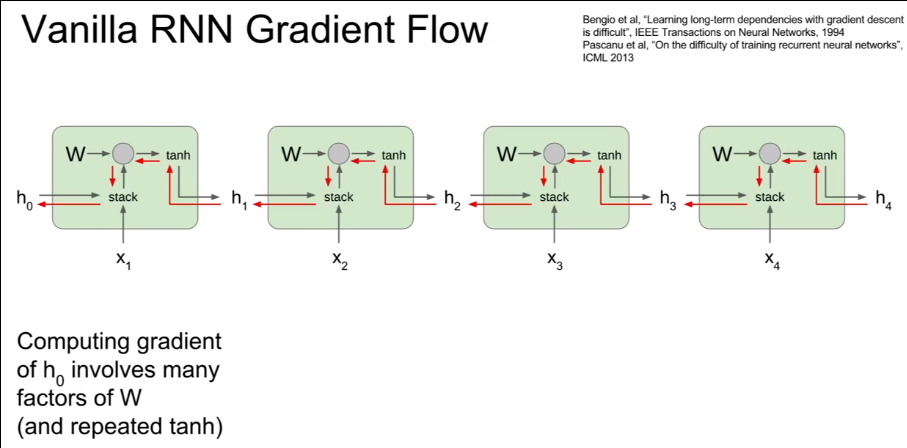
反向传播时需要W反复作为因子乘进梯度中,如果W的最大的特征值大于0会导致梯度爆炸,反过来,会导致梯度消失。对于梯度爆炸,使用Gradient clipping处理,对于梯度消失时,使用不同的RNN结构LSTM
Long Short Term Memory(LSTM)
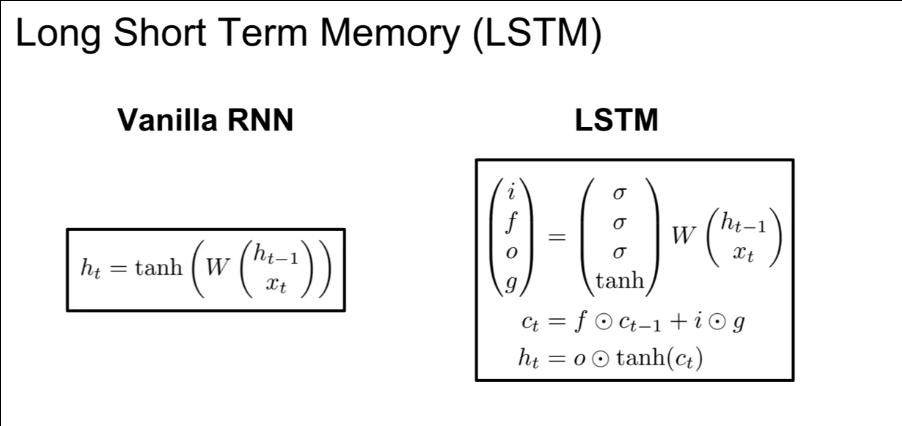
与传统的RNN不同,LSTM除了维持ht外,还维持了细胞状态(ct),通常会计算四个门:
- f:Forget gate,whether to erase cell
- i: input gate,whether to write to cell
- g: Gate gate(?), How much to write to cell
- o: Output gate,How much to reveal cell
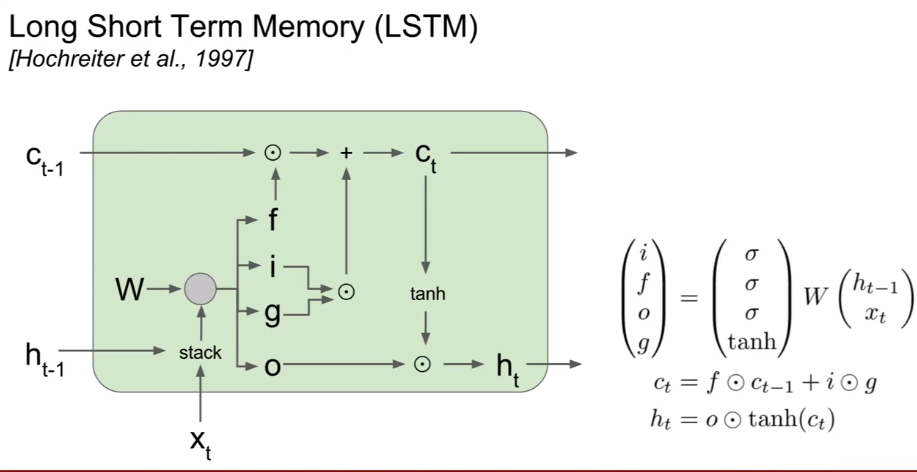
使用这样的结构时,反向传播不会再出现梯度消失和爆炸的问题。
总结
- RNNs使得深度神经网络的结构更加灵活
- 朴素的RNNs很简单但是效果不好
- 通常使用LSTM或GRU,它们提升了梯度流向的表现
- RNN的反向传播可能导致梯度爆炸或消失,爆炸通过梯度截断处理(gradient clipping),消失需要通过LSTM处理
- 更好的结构仍然在研究中
- 需要更好的理解(理论上和经验上的)
Detection and Segmentation
Semantic Segmentation
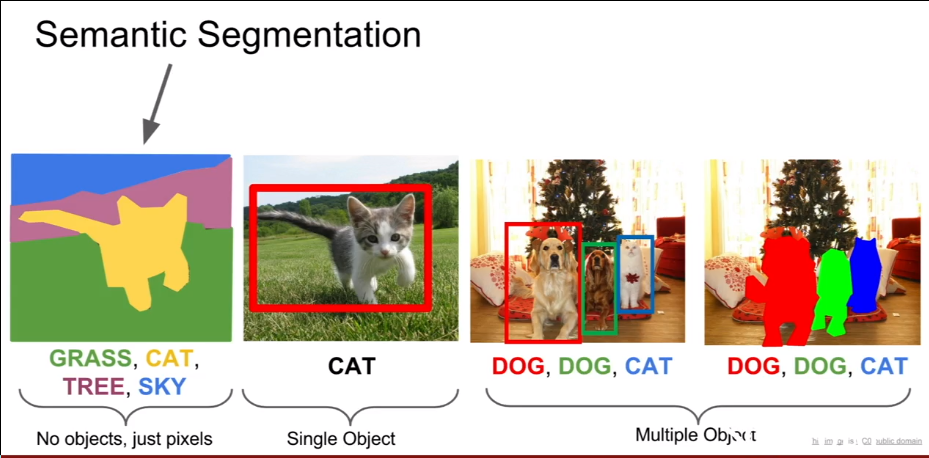
IDEA:Design a network as a bunch of convolutional layers to make predictions for pixels all at once(Fully Convolutional),这个过程涉及下采样和上采样
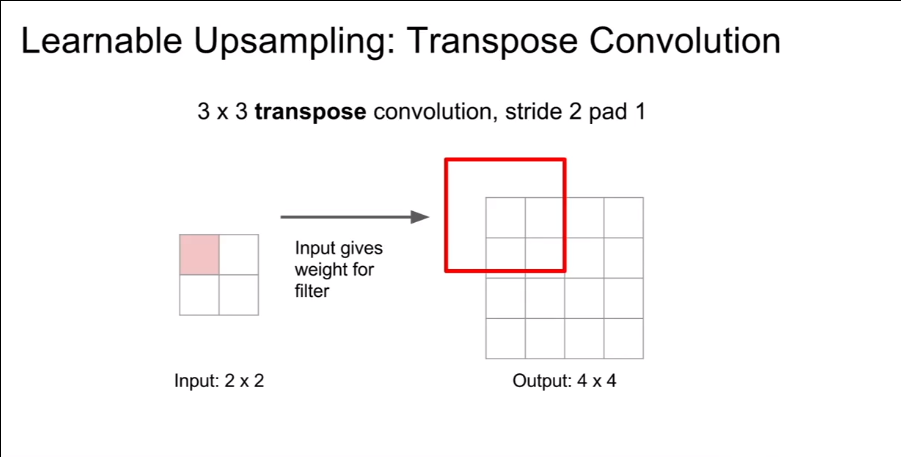
Learnable Upsampling: Transpose Convolution

Classification + Localization

通过两个子网络实现classification和localization,一个通过传统的分类网络得到类别得分实现classification,另一个网络回归预测Box coordinates来实现localization

Object Detection

与上一个任务不同,这里的输出是变化的
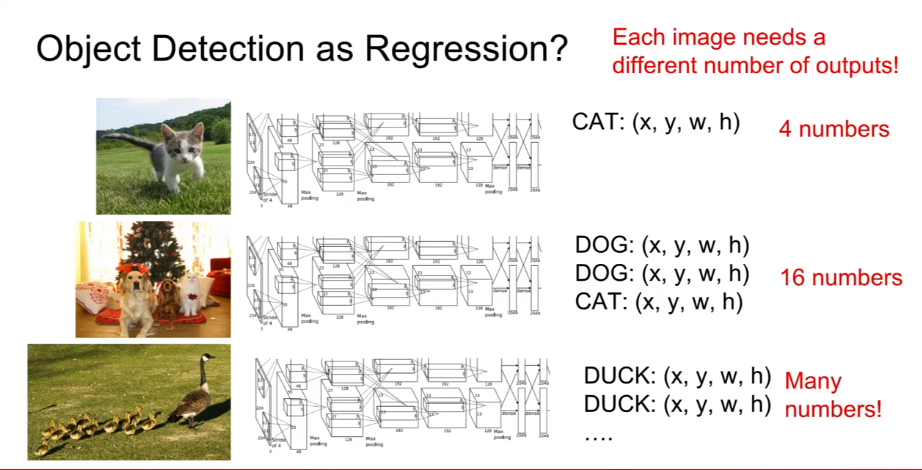
一个解决方法是使用滑动窗口,将一个CNN应用在图片上的different crops上,但因为目标位置大小的位置性,需要列举很多不同的窗口,计算极其复杂,实践中不常使用,另一种方法是Region Proposals:
- 找到水滴状的可能包含目标的区域
- 相对更快
RCNN

问题
- 训练很慢,占用空间很大
- 接口很慢
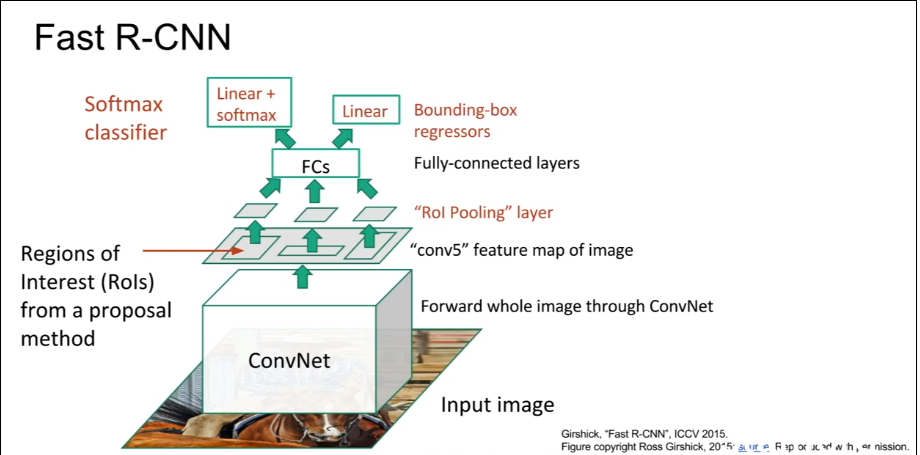
Fast R-CNN
与在原图上提出regions of interest不同,在feature map上给出Regions of interest

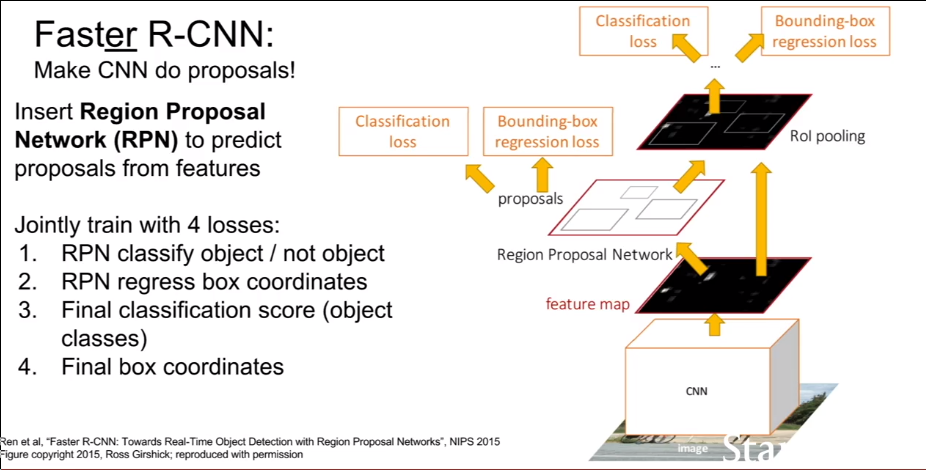
Faster R-CNN
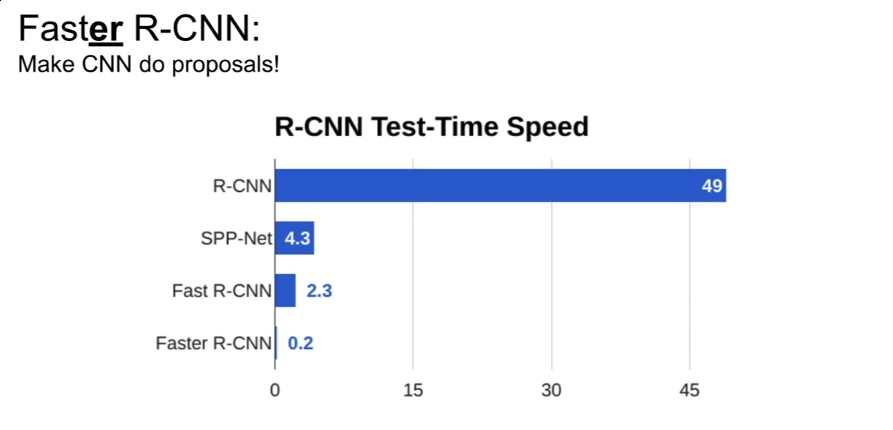

Instance Segmentation




本周反思
阅读resnet的论文,未完成
继续完成cs231n的学习进度到75%,完成
学习opencv上册到50%,未完成
下周目标
完成cs231n的学习
阅读resnet的论文
学习opencv上册到50%