空洞卷积, 从图中可以看出,对于一个3*3的卷积,可以通过使用增加卷积的空洞的个数,来获得较大的感受眼, 从第一幅图中可以看出3*3的卷积,可以通过补零的方式,变成7*7的感受眼,这里补零的个数为1,即dilated等于2
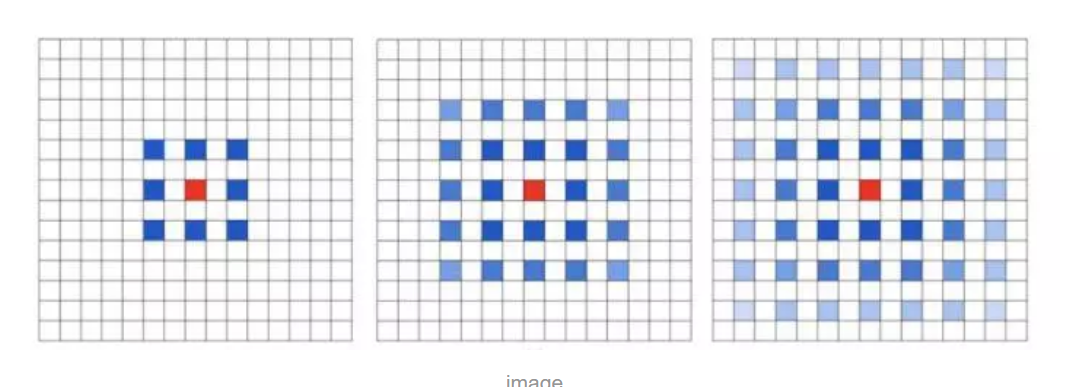
空洞卷积在语义分割中的使用较多,因为涉及到向下卷积和向上卷积,为了不使用padding降低图片的维度,造成feature_map的信息损失,同时又可以在一定程度上增加感受眼。使用了这种空洞卷积的方式,增加感受眼,在语义分割中的使用方法是:使用多个不同尺度的空洞卷积,将最后的结果做一个拼接。
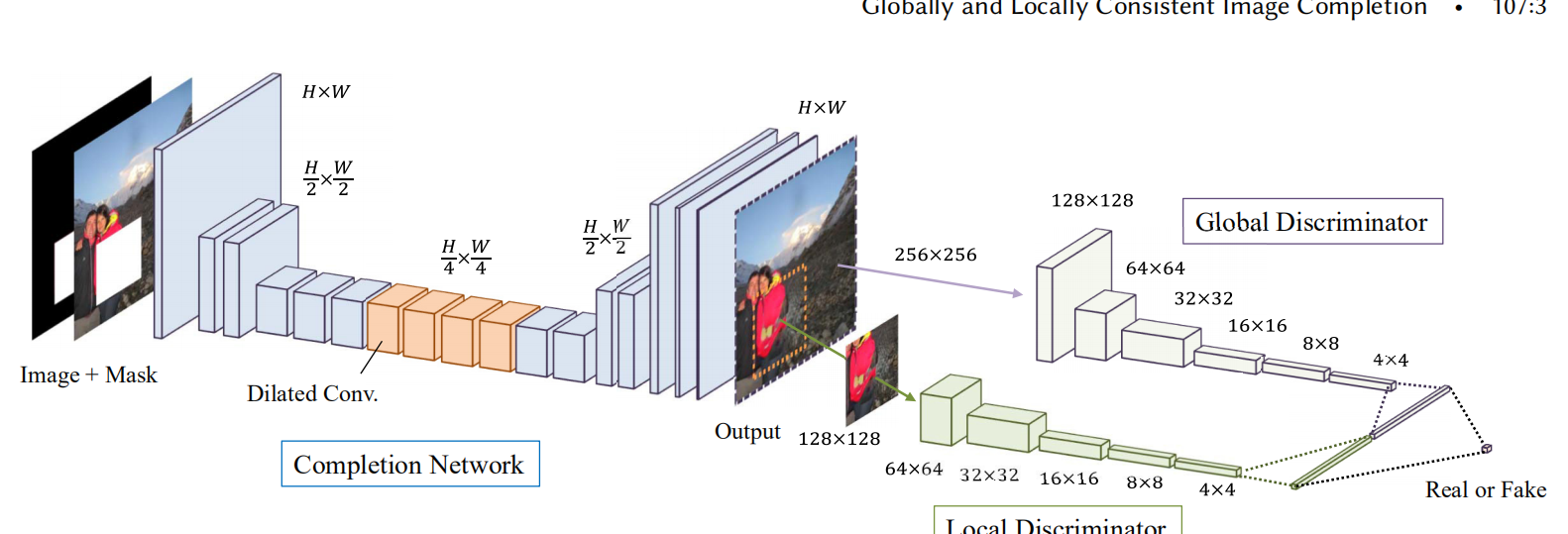
而这里使用的空洞卷积的场景是用于进行图像补全操作, 中间橙色部分为空洞卷积,dilated的大小分别为2, 4, 8, 16,用来获得更高的感受野
代码:主函数
with tf.variable_scope('dilated4'):
# [3, 3, 256, 256] 表示卷积核的大小,16表示dilated即补零的大小 x = dilated_conv_layer(x, [3, 3, 256, 256], 16) x = batch_normalize(x, is_training) x = tf.nn.relu(x)
代码:调用函数dilated_conv_layer
def dilated_conv_layer(x, shape, dilation): # filter表示卷积核的构造 filters = tf.get_variable('filters', shape=shape, dtype=tf.float32, initializer=tf.contrib.layers.xavier_initializer(), trainable=True) # 进行空洞卷积,dilation表示卷积核补零的大小 return tf.nn.atrous_conv2d(x, filters, dilation, padding='SAME')