今天我们利用波士顿房价进行简单分析,快速熟悉数据挖掘和分析的一般流程。
1.导入数据。

2.查看数据维度,从结果可以出,该数据一共有506条记录,14个特征,然后再输出特征的名字和数据类型。

3.然后用.head()函数输出前面5条数据,初步查看数据的基本内容。

4.接着用.describe()函数进行数据的描述性分析,查看每一列(也就是每一个特征的数据)的条数、平均值、最大值、最小值、中位数等等,比较全面地了解数据。也可以初步从这里排查异常值的情况。

5.接着,我们可以查看数据的相关性,值越接近1,说明相关性越强。

6.也可以把相关性信息进行可视化,颜色越接近黄色相关性越高,越接近紫色相关性越低。

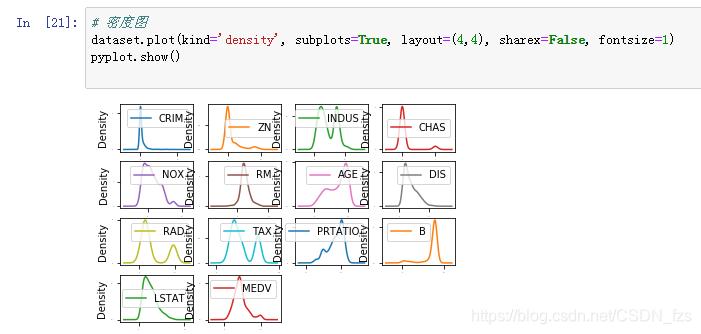
7.也可以用kind='density'查看数据的密度图,其中符合正态分布的特征有:CRIM、ZN、CHAS、NOX、RM、DIS、B、LSTAT、MEDV。
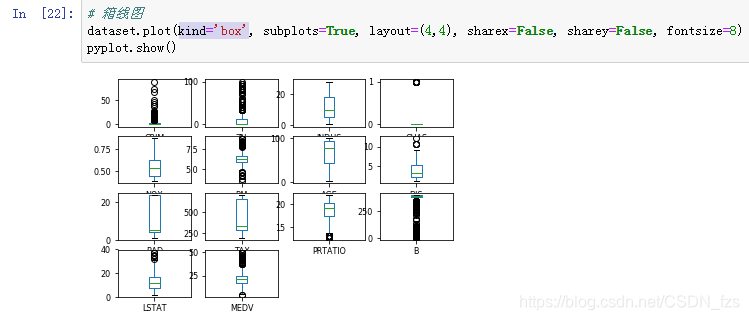
8.kind='box'为我们直观地展示了每个特征的箱图,可以可视化地看到每个特征的最大最小值、中位数、大小25%和75%的值。
9.scatter_matrix()函数帮助我们了解到每个特征的数据分布情况。

10.为了方便做训练和预测,我们在这里对数据进行分离,用80%的数据进行训练,用剩下的20%做预测。

11.到这一步,我们导入3个模型,分别是逻辑回归、SVN支持向量机和KNN。

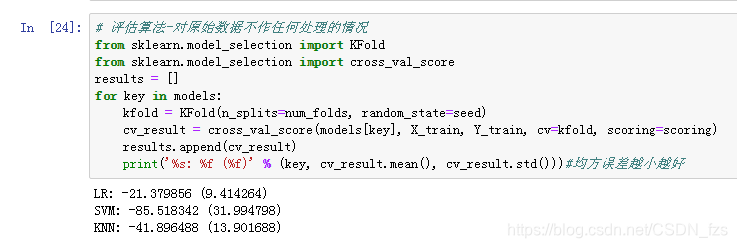
12.开始训练数据,这是我们的原始数据,没有做处理。从得到的结果中可以看到,LR的误差最小,接着是KNN,然后是SVN,我们认为误差越小越好。

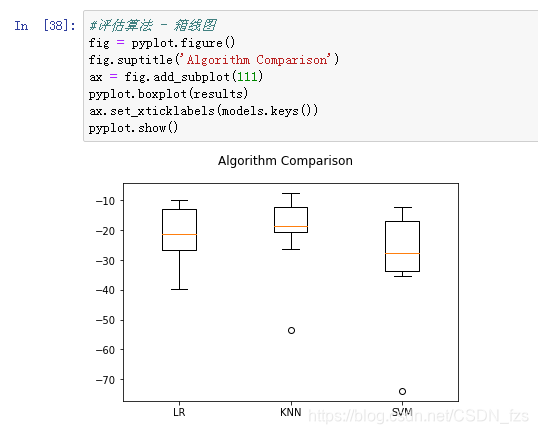
13.在对数据进行正态化之后,我们发现结果就完全不一样了,这一次我们发现LR模型误差最小,接着是KNN,然后是SVN。

14.为什么要讲数据进行正态化呢?
数据正态化,目的是稳定方差,直线化,使数据分布正态或者接近正态
最后,源码已在图片中给出,需要数据的同学,可以关注公众号回复“房价数据”获取。

专注于专注于大数据、微服务架构