前面我们已经分析过了HashMap的源码, 我们已经知道了HashMap的底层的数据组织就是一个可变长的数组加一个单向链表来实现的,元素储存在hash表中的位置由其hash值和数组大小来确定,如果发生了hash冲突是使用拉链法(也就是单向链表)来解决的。因此HashMap里面储存的元素是无序的,但是有时候我们需要一个有序的集合,JDK提供的集合包中就提供了这样的类来满足我们的要求。它们分别是TreeMap与LinkedHashMap。TreeMap实现了hash表中按键有序,遍历TreeMap可以得到按键(key)的从小到大输出,TreeMap的底层是使用红黑树来实现的,它的源码我们以后在来分析。LinkHashMap是HashMap的子类,它保持了元素按插入或者访问有序。插入有序比较好理解,就是put操作对应的顺序,更改key对应的value值不会改变插入顺序。那么什么是访问顺序呢?所谓访问就是指get/put操作,对一个键执行get/put操作后,其对应的键值对会移到链表末尾。所以最后面的是最近访问的,最开始的是最久没被访问的,这种顺序就是访问顺序。
为了方便下面的解释,我们先给出LinkedHashMap的底层数据组织形式:可变长数组+单向链表+双向链表。其中可变长数组+单向链表的功能和HashMap的功能是一样的,用来实现O(1)时间内元素的put/get操作。双向链表用来记录元素的插入顺序或者访问顺序。
先看下面一个关于访问顺序的例子:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<Character, Integer> lm = new LinkedHashMap<>(16,0.75f,true);
lm.put('a',1);
lm.put('b',2);
lm.put('c',3);
lm.get('b');
lm.get('a');
for(Map.Entry<Character, Integer> entry : lm.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
}
对应的输出:
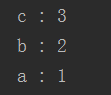
a是最后访问的,所以a输出在最后,b其次,c输出在最前面。通过这个例子,相信大家就明白什么是访问顺序了。
下面我们来看LinkedHashMap的源码:
先看构造函数:
// LinkedHashMap 继承自HashMap,并且实现了Map接口
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
{
private static final long serialVersionUID = 3801124242820219131L;
// 底层双向链表的头指针
private transient Entry<K,V> header;
// 是否维持访问顺序,accessOrder为true表示双向链表维持访问顺序,否则双向链表维持插入顺序
private final boolean accessOrder;
// 通过initialCapacity与loadFactor初始化,这两个参数是HashMap需要的,默认维持插入顺序
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 通过initialCapacity来初始化,默认维持插入顺序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 默认维持插入顺序
public LinkedHashMap() {
super();
accessOrder = false;
}
// 默认维持插入顺序
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// 唯一一个可以指定维持访问顺序的构造函数
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
// 这个函数在HashMap中的所有构造中都被调用了,但是在HashMap中该函数为空,这里重写了该函数,因此在new一个LinkedHashMap对象时,会反回来调用这个函数,这里是多态
@Override
void init() {
// 就是初始化了一个头结点 header.before指向双向链表的尾结点,header.after 指向双向链表的头结点,二者相等时,表示双向链表为空。这里就是一个带表头的双向链表。
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
}LinkedHashMap一共有5个构造函数,其中前四个与HashMap的构造函数一样,他们都默认维持插入顺序,只有一个构造函数可以指定双向链表维持访问顺序。
下面我们来看一下LinkedHashMap里面的Entry是怎么实现的:
// LinkedHashMap中的Entry继承自HashMap中的Entry
private static class Entry<K,V> extends HashMap.Entry<K,V> {
/*
HashMap中的Entry主要的成员变量是,key,value,hash,next.
现在LinkedHashMap中的Entry继承了HashMap中的Entry,并添加了before与after指针
当然也可以重新建立一个双向链表,里面复制一份key,value,这样做肯定比较浪费空间了。
不得不说这里的设计非常的巧妙,这样一个Entry里面就含有三个指针了:
next指针用于使用拉链法来解决hash冲突,before与after指针用来维持插入或者访问顺序,二者互不干扰。且共用了key,value
*/
// 双向链表的befor与after指针
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
// 在双向链表中删除本节点。双向链表的删除,比较简单
private void remove() {
before.after = after;
after.before = before;
}
// 将本节点插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
// 这个方法和init()方法一样,在HashMap中的Entry中为空。这里子类重写了,当父类HashMap调用时就是多态了。
// 这个方法,当父类HashMap中调用put且键存在时,HashMap会调用Entry的recordAccess方法,具体可以参见HashMap源码解析那一篇。
// 这里重写了recordAccess方法,主要的目的就是如果双向链表维持的是访问顺序的话,recordAccess将该键移到双向链表的末尾,如果是插入顺序这里什么也不做。
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove(); // 先删除
addBefore(lm.header); // 然后添加到链表的尾部
}
}
// 和recordAccess一样,在父类HashMap中的Entry中recordRemoval也为空,这里重写了这个方法。
// 这个方法当有键被删除时,HashMap会调用Entry的recordRemoval方法,这个方法的作用就是在双向链表中也删除这个键。
void recordRemoval(HashMap<K,V> m) {
remove();
}
}总结一下LinkedHashMap中Entry的实现方式:LinkedHashMap中的Entry继承自HashMap中的Entry,HashMap中的Entry就是一个单向链表,里面保存了键值对,LinkedHashMap在此基础上增加了后继指针after与前驱指针before,这个双向链表用于维持插入顺序或者访问顺序,这样设计的目的就是为了共用key与value,减少空间的使用。另外,LinkedHashMap还重写了recordAccess与recordRemoval方法,这两个方法在HashMap中的Entry中也有出现,只不过当时这两个方法是空的,因此实际运行时会多态的调用子类方法。recordAccess方法的作用就是当HashMap中执行put操作且值存在时,并且LinkedHashMap维持的是访问顺序的话,会见该节点移到链表的尾部,recordRemoval方法用于在HashMap删除结点时调用,因此在双向链表中该节点也被删除 。
如果维持的访问顺序的话,当get和put一个新值时,该节点也应该被移到链表尾部,下面我们再来看看get与put一个新值时在LinkedHashMap中是怎么实现的:
// LinkedHashMap中的get操作
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key); // 调用父类HashMap的方法
if (e == null)
return null;
e.recordAccess(this); // 调用子类重写的recordAccess方法(如果是维持访问顺序的话,就将该节点移到双向链表尾部)
return e.value;
}
// 向LinkedHashMap中添加一个新的键值对时的操作
void addEntry(int hash, K key, V value, int bucketIndex) {
super.addEntry(hash, key, value, bucketIndex); // 调用父类HashMap的addEntry方法,这个方法主要就是用来判断是否需要扩容的,实际将节点增加到HashMap中是createEntry函数
// header.after 是双向链表的首节点,如果双向链表维持的是访问顺序,那么该节点就是最久没有被访问的节点了。
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) { // 判断是否删除最久没被访问的结点,默认返回一直未false,也就是说一直都不会删除最久没被访问的结点。
removeEntryForKey(eldest.key); // 调用父类的删除函数,根据key删除结点,该函数中也会调用recordRemoval函数,因此在双向链表中该节点也会被删除。
}
}
// 默认的removeEldestEntry实现,一直返回false,该方法为protected,子类可以重写来实现自己的逻辑,比如LRU缓存。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
// 重写了createEntry方法,该方法用于向双向链表中添加一个新的健,重写的主要目的是将其加入到双向节点的尾部。
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header); // 将新节点加入到双向链表的尾部
size++;
}由于LInkedHashMap内里面有双向链表来组织数据,因此遍历LinkedHashMap可以使用双向链表来实现,这笔HashMap遍历整个hash表要高效,因此LinkedHashMap重写了HashMap中几个需要遍历的函数使得其在遍历整个hash表上比HashMap更加的高效,下面我们就来看一下这几个实现:
// 在rehash时被调用,这里使用双向链表来遍历整个hash表
@Override
void transfer(HashMap.Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e = header.after; e != header; e = e.after) {
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
}
}
// 使用双向链表来遍历这个hash表
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}还有一个重载的函数:clear
public void clear() {
super.clear();
header.before = header.after = header; // 清空双向链表
}另外,LinkedHashMap中还重写了HashMap中的迭代器方法,也是基于双向链表来实现的,代码也比较简单,这里就不在赘述了。
自此LinkedHashMap的源码就分析完了,我们发现LinkedHashMap的源码并不多,实现也不是很难。其在HashMap的基础上增加了一个双向链表用于维持插入顺序或者访问顺序。另外这里的双向链表的设计也很精髓,与hash表中的结点共用了key,value,从而节约了内存。在维持访问顺序时,每次get和put操作,都会将该节点移到双向链表的尾部。所以双向链表的尾部是最近访问的元素,首部是最久没有被访问的元素。还有一点需要注意的就是,虽然双向链表与hash表共用了key,value,但是它们两者之间的操作互不影响。