概述
分析一下 LinkedHashMap 源码,看下内部结构,研究一下如何保证访问顺序。
继承关系
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>LinkedHashMap 继承自 HashMap,是HashMap的一个子类。
内部结构
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
private static final long serialVersionUID = 3801124242820219131L;
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;Entry 类继承自 HashMap.Node,增加了2个变量,before, after。来维护每个Node前面一个对象和后面一个对象。head, tail 变量维护链表头和尾。accessOrder 为true表示按访问顺序来遍历(访问过的元素放到链表的尾部),为false表示按插入顺序遍历。
其实主要的内部结构还是和 HashMap 一样的,只不过在HashMap的基础上每个Node都加上了前后2个对象的引用。它的大致结构是这样。
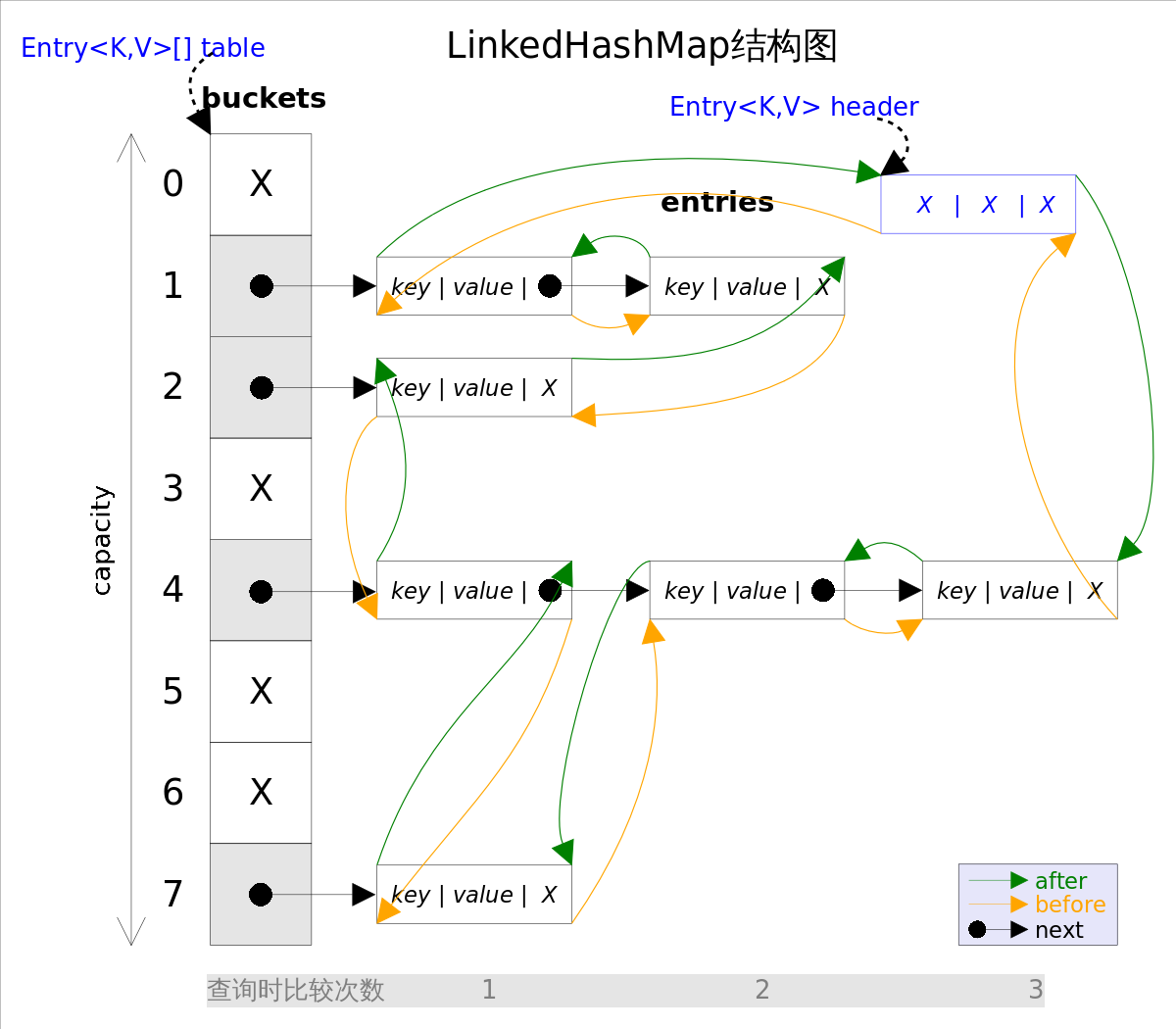
图片来自网络
遍历
遍历一个LinkedHashMap,默认按照插入顺序来显示。结合 这篇文章 HashIterator 的介绍,看下 LinkedHashMap 是怎么遍历的。
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount;
LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
}
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
...
}原理和HashMap差不多,但是 LinkedHashMap 的遍历(看nextNode方法)是从 head 开始遍历,直到 Entry 的 after 字段为空。
访问顺序
get 方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}get 方法和 HashMap 的基本一样,但是多了一个 afterNodeAccess 方法,当 accessOrder 为 true 的时候执行这个方法,将访问过的node放到链表的最后。
LinkedHashMap linkedHashMap = new LinkedHashMap(16, 0.75f , true);也就是像这样初始化一个 LinkedHashMap 之后,每次访问过一个对象之后这个对象就被放到了链表的最后。
put 方法
其实 LinkedHashMap 自己没有实现 put 方法,还是调用的是 HashMap 的 put 方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}这里有一个 newNode(hash, key, value, null),LinkedHashMap 重写了这个方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}由于Java多态的特性,put方法实际生成的是 LinkedHashMap.Entry 类,并且将这个node放到了整个链表的最后(linkNodeLast)。
remove 方法
LinkedHashMap 也是调用的 HashMap 的 remove 方法
final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}出方法前有一个 afterNodeRemoval(node) 方法,LinkedHashMap 重写了这个方法
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}因为内部有一个链表,所以删除的时候也要维护一下链表关系。
总结
LinkedHashMap 作为 HashMap 的子类,重写了其中一些方法,扩展了 Node 类,使其具有了按顺序遍历数据的功能。在内部维护了一个链表,在put/remove方法中,在数组中操作元素的同时,维护了一个链表。