1.爬虫原理:
向网站发起请求,获取资源后分析并提取有用数据的程序;
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
2.爬虫开发过程:
(1)、 浏览器工作原理:
浏览器工作原理的实质就是实现http协议的通讯,具体过程如下:
连接 服务器通过一个ServerSocket类对象对8000端口进行监听,监听到之后建立连接,打开一个socket虚拟文件。
请求 创建与建立socket连接相关的流对象后,浏览器获取请求,为GET请求,则从请求信息中获取所访问的HTML文件名,向服务器发送请求。
应答 服务收到请求后,搜索相关目录文件,若不存在,返回错误信息。若存在,则想html文件,进行加HTTP头等处理后响应给浏览器,浏览器解析html文件,若其中还包含图片,视频等请求,则浏览器再次访问web服务器,异常获取图片视频等,并对其进行组装显示出来。
(2)、使用 requests 库抓取网站数据:
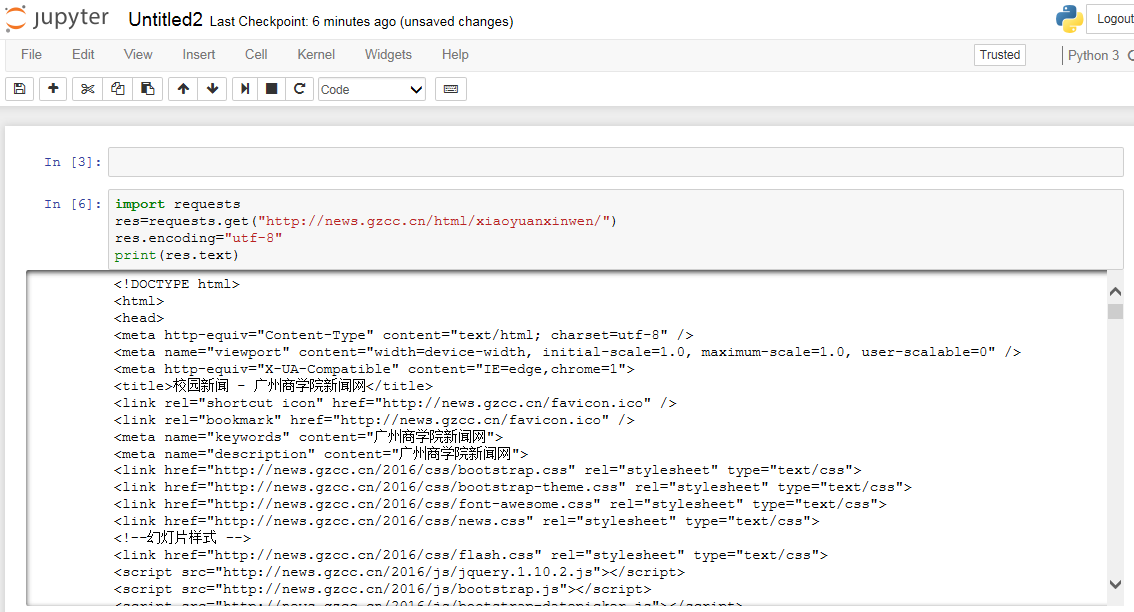
(3)、了解网页,写一个简单的HTML代码:
<!DOCTYPE html> <html> <head> <title>这个是标题</title> </head> <body> <h1 class="title-article">这是一个一个简单的HTML <p>Hello World!</p> </h1> <h2>这是一个h2</h2> <h3>这是一个h3</h3> <h4>这是一个h4</h4> <h5>这是一个h5 <p id="title">Hello World!</p> <p>Hello World!</p> <h6>这是一个h6</h6> <p>Hello World!</p> </h5> </body> </html>
(4)、使用 Beautiful Soup 解析网页:
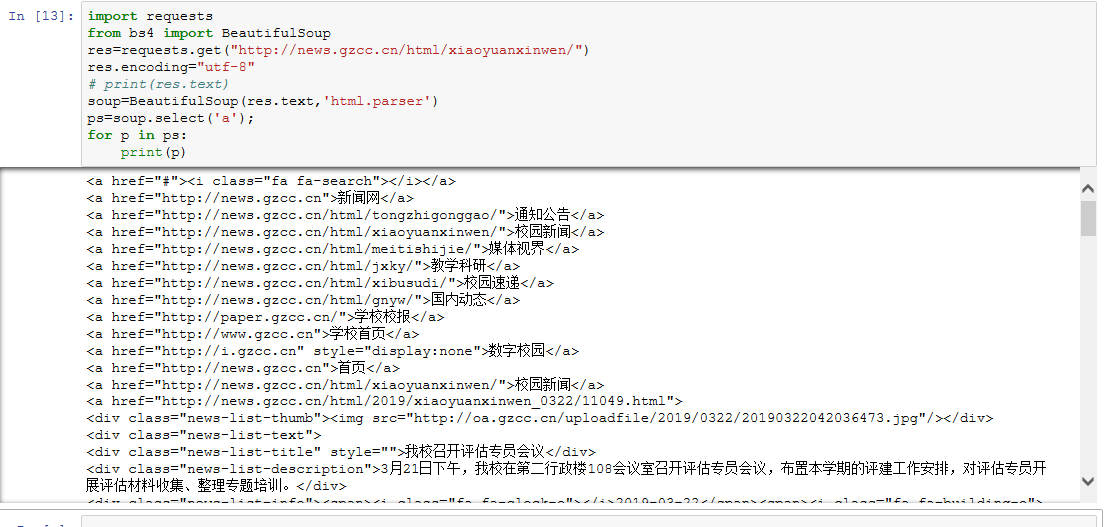
输出该网页中所有的a标签。
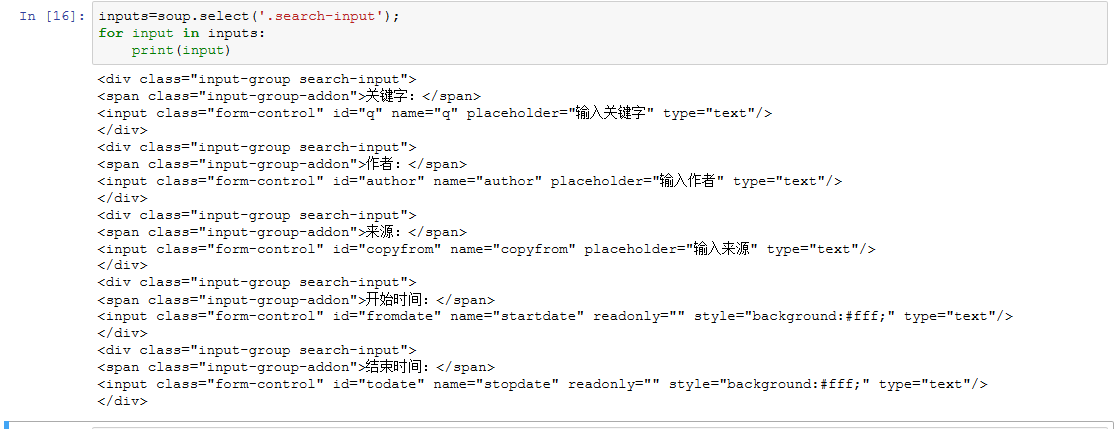
找出类名为search-input的标签。
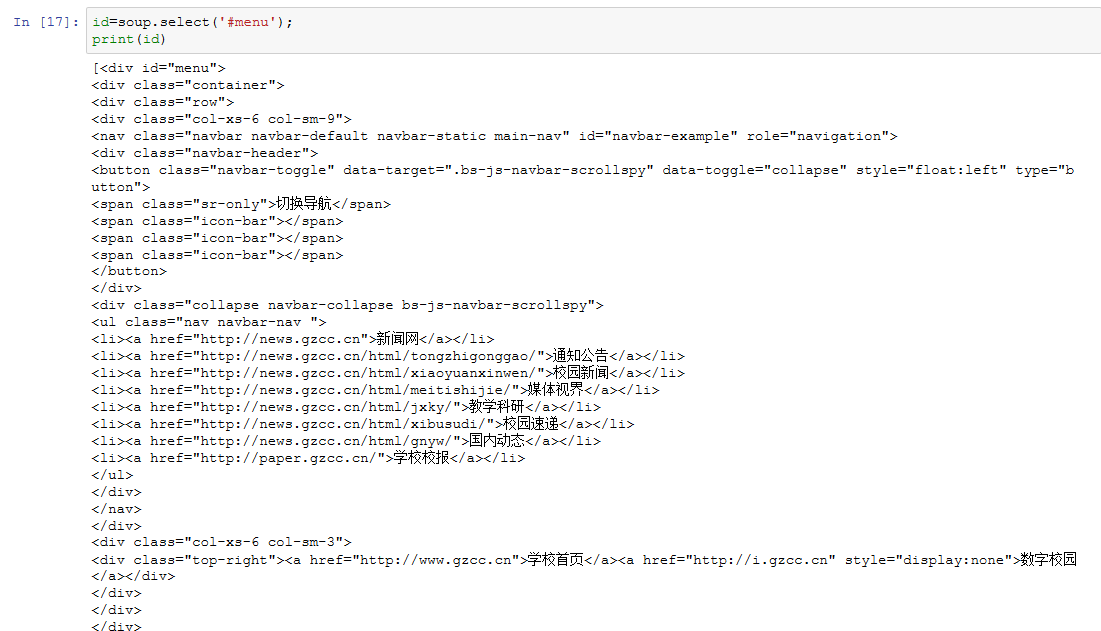
找出id名为menu的标签。
3.提取一篇校园新闻的标题、发布时间、发布单位
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
