酷我音乐
本篇博客旨在提供一个能够利用代码下载酷我音乐上免费音乐,并不能下载付费音乐哦!!!
老铁,让我们开始今天的博客之旅吧!!!
搜索框的url如下,
https://www.kuwo.cn/search/list?key=%E5%BC%A0%E9%9F%B6%E6%B6%B5
对该网站进行抓包分析,我们发现一个包含音乐基本信息的包,具体内容如下,

其对应url如下,

注意,请求该url伪造头必须带上cookie与csrf字段(这两个字段具有时效性),否则爬不到数据。
对该url进行请求,得到的数据是json类型,

对该json数据进行分析提取,获取到关键数据(歌曲id)以及其他描述信息

然后我们继续抓包分析,发现包含歌曲真正url的数据包:

其对应url如下,

对该url请求参数进行分析,
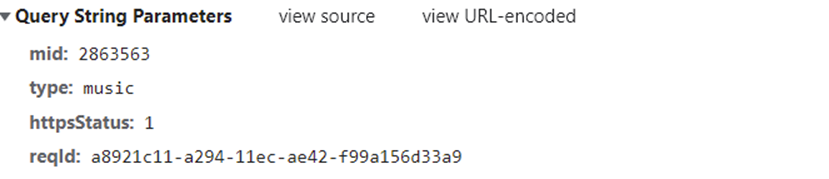
发现不同音乐的请求参数,仅仅只有mid不同而已(reqid参数略有不同,但不影响)。而mid我们前面也已经得到了,因此可以构造获得音乐真正url的url地址。

然后对该网址进行请求,并使用正则表达式对该网址进行提取,

最后下载相应音乐,

最终执行结果如下,

至此,大功告成!
下面是具体代码实现:
import urllib.parse
import re
import requests
headers_1 = {
'cookie': '_ga=GA1.2.1350961281.1642257590; _gid=GA1.2.312608794.1647150956; _gat=1; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1646828749,1647150956,1647185710; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1647185710; kw_token=XEA9HSGTRS',
'Host': 'www.kuwo.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'csrf': 'XEA9HSGTRS'
}
headers_2 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
}
class KuwoSpider():
def __init__(self):
self.__name = ''
self.__index = 0
self.__flag = 1
self.__song_urls = ''
self.song_infos = []
def get_music_infos(self, name):
self.__flag -= 1
if self.__flag < 0:
self.song_infos.clear()
self.__flag = 0
self.__name = name
music_name = urllib.parse.quote(self.__name)
search_url = f'https://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={music_name}&pn=1&rn=30&httpsStatus=1&reqId=5bf43991-9fb2-11ec-9893-736ed75cec4b'
refer = {
'Referer': f'http://www.kuwo.cn/search/list?key={music_name}'} # 伪造头部的一个参数,动态变化
headers_1.update(refer)
res_1 = requests.get(url=search_url, headers=headers_1)
json_data = res_1.json()
i = 1
lists = json_data["data"]["list"]
for list_ in lists:
rid = list_["rid"]
name = list_["name"]
artist = list_["artist"]
self.song_infos.append((i, name, artist, rid))
i += 1
def print_music(self):
for num, name_, artist, _ in self.song_infos:
print(num, name_, artist)
def donwnload(self, index):
self.__index = index
_, name_, _, music_id = self.song_infos[self.__index - 1]
music_url = f'https://www.kuwo.cn/api/v1/www/music/playUrl?' \
f'mid={music_id}&type=music&httpsStatus=1&reqId=7cba4520-9fb2-11ec-a798-f980ededc0dc'
res = requests.get(music_url, headers=headers_1).text
self.__song_urls = re.findall('"url":"(.*?)"', res)[0]
# print(self.__song_urls)
content = requests.get(url=self.__song_urls, headers=headers_2).content
with open(f'{name_}.mp3', 'wb') as f:
print('正在下载中...')
f.write(content)
print(f'{name_} 下载成功 ')
if __name__ == '__main__':
kuwo = KuwoSpider()
print('请输入歌曲或歌手名字:', end='')
name = input()
kuwo.get_music_infos(name)
kuwo.print_music()
print('请输入下载的歌曲序号: ', end='')
index = int(input())
kuwo.donwnload(index)
声明,本篇博客仅供参考学习,不支持其他任何用途。