1.我选取的是中国网时事评论员王涛的一篇关于建国70周年阅兵的一篇评论
2.源代码:
import requests
from bs4 import BeautifulSoup
import re
url="https://politics.gmw.cn/2019-10/03/content_33207376.htm"
r=requests.get(url)
try:
r.raise_for_status()
r.encoding=r.apparent_encoding
message=r.text
except:
print("ERROR")
soup=BeautifulSoup(message,"html.parser")
songlist=soup.find_all("p")
for i in range(0,40):
print(songlist[i].get_text())
运行结果: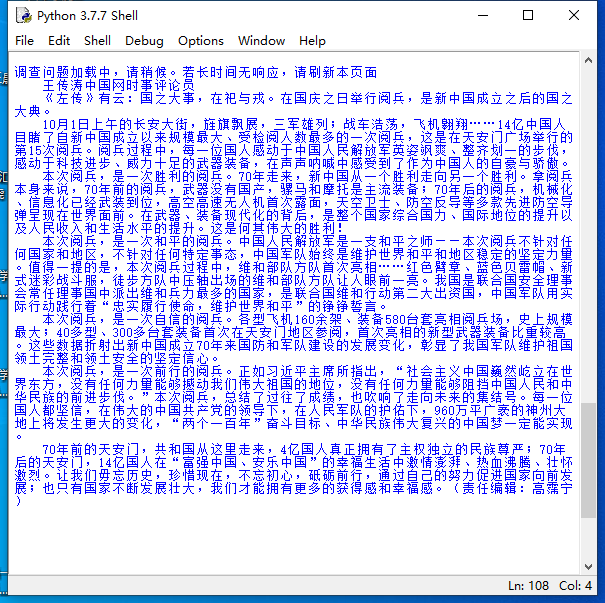
然后我用这数据建立了一个文本文档“爬虫.txt"以此文档进行数据分析,建立一个词云
词云源代码:
import jieba
import wordcloud
from imageio import imread
from wordcloud import WordCloud
mask=imread('E:\\哈哈.jpg')
f=open('E:\\爬虫.txt','r',encoding='utf-8')
t=f.read()
f.close()
j=jieba.lcut(t)
txt=' '.join(j)
W=WordCloud(background_color='white',width=800,height=600,\
max_words=150,max_font_size=80,mask=mask,\
scale=4,font_path='msyh.ttc').generate(txt)
W.to_file('E:\\爬虫作业.png')
我选取了中国地图的剪影作为背景图片

运行结果:
