1. 摘要
作者使用一个pose-sensitive-embddding,把姿态的粗糙、精细信息结合在一起应用到模型中。
用一个新的re-ranking方法,不需要重新计算新的ranking列表,是一种无监督、自动的方法。
这个新方法取得了state-of-the-art的效果。
2. 介绍
粗糙的信息作者使用view information来表示,通过估计front、back、side三种方向得分来表示;
精细的信息作者通过计算人体的14个关键点的位置来表示,然后把位置信息作为通道输入到模型
中,只设计一个简单的分类损失来训练模型。文章主要贡献:
(1)提出一种新的CNN embedding,结合粗糙、精细信息
(2)提出一种新的无监督、自动的re-ranking方法
3. 方法
论文的pipline
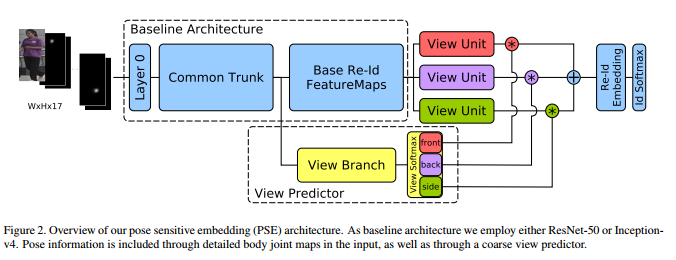
(1)Pose-Sensitive Embedding
view information:{front、back、side}网络在common trunk 之后脱离出一个view predictor ,这个分类器在独立数据集RAP上
训练学习好,对{front、back、side}分别估计出一个得分,作为主干view unit中的weight。
而view unit 接在feature map后面,复制前面的网络层。同weight 加权后接一个softmax 分类器。
训练过程 :
先训练好view predictor ;然后训练view units 同最后一层softmax;最后训练第一层跟最后一层;在上述的所有训练过程中,其他的
都固定不变。其实,不太明白这样训练的理由,文章中也没有给出详细的训练依据,姑且认为效果好吧。
(2)re-ranking 方法
定义一个新的expanded cross neighborhood ,然后基于ECN距离计算。
计算probe与gallery的距离,通过计算p的M个近邻同g的距离与g的M个近邻同p的距离之和,然后求平均
还使用了一种top-k gallery相似性的损失。
4. 实验
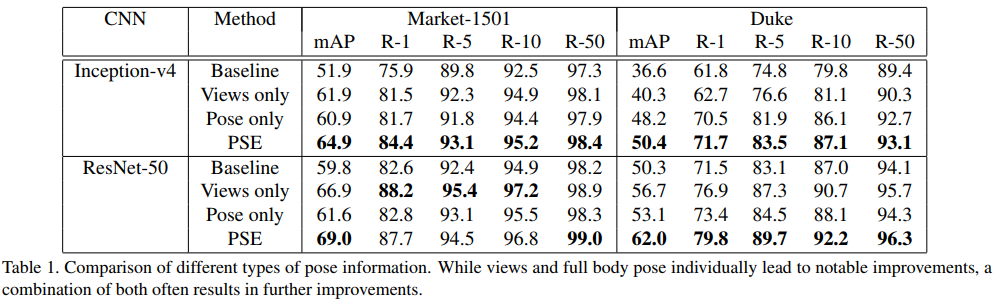
上述实验证明了粗糙、精细姿态信息对Reid的作用,进而说明了它们的结合将取得更好的结果。
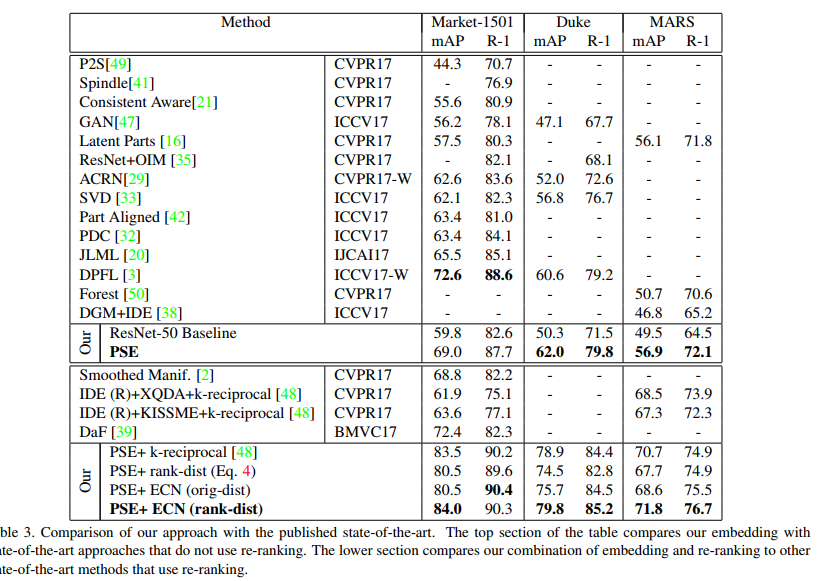
5. 结论
PSE证明了粗糙、精细的信息对Reid都是很有用的。PSE利用一个外在的view predictor 把coarse and fine-grained信息整合在一起。
提高了行人再识别的准确率。而新提出的基于ECN距离的re-ranking 方法也取到了state-of-the-art的效果。
6. 评价
PSE利用人体姿态关键点的估计,把关键点的位置作为新的通道输入网络;结合view information让Reid 的准确率提高了很多。
fine-grained information作为新的通道这倒是一个新的思路。不过这个还要依赖一个外在独立的view predictor,稍微显得有点臃肿。
新的re-ranking 方法感觉计算量还是蛮大的,不过效果不错,这个无监督、自动的re-ranking方法还取得了state-of-the-art。
7. 参考
A Pose-Sensitive Embedding for Person Re-Identification
with Expanded Cross Neighborhood Re-Ranking