https://arxiv.org/pdf/1705.02801.pdf
这篇论文列举了目前graph embedding算法,将其分为“因式分解”、“随机游走”、“深度学习”三类,在不同的任务上评估其效果,最后提了点发展方向
前言
- 图在生物蛋白质结构、社交网络、词共现网络中应用
- 图分析任务可以分为:
- 节点分类(随机游走、提特征)
- 链路预测(相似性方法、最大似然法、概率模型)
- 聚类(基于距离)
- 可视化 - 模型通常作用于:原始图邻接矩阵,或一个生成的向量空间内
- 获取结点的向量表达的挑战:
- 选择一个属性。结点的向量表示应表达图结构或者结点关系
- 伸缩性。需要适应大型图结构的计算需求
- embedding的维度。大维度信息更全,小维度关系表达更好 - 论文的贡献:
- 对现有算法分四类,并描述其研究方向和挑战等
- 系统分析不同算法对应不同问题的效果,测试其效果,综合比较。。。以及鲁棒性、超参等
- 做了个python包,GEM
定义
- 图(Graph):图 ;结点 ;边 ;邻接矩阵S,
- 第一相似度(First-order proximity): 是 和 的第一相似度
- 第二相似度(Second-order proximity): 表达第一 与邻居的相似度集合,第二相似度为 和 的相似度
- Graph Embedding:给定一个图 ,graph embedding是一个映射: ,且映射f保留了图的一些相似性度量
- embedding会保留图的某一方面特性,如保留结点的第一相似度,则映射后直连接点距离要小于间接连接的点
算法分类
研究现状
列举发展中的算法。
Laplacian Eigenmaps->Locally Linear Embedding(LLE)->Graph Factorization->LINE->HOPE->SDNE
分成三类:因式分解、随机游走、深度学习
基于因式分解的方法
用于分解的矩阵包括:结点邻接矩阵、拉普拉斯矩阵、结点转移概率矩阵、ketz相似矩阵
局部线性嵌入(LLE,Locally Linear Embedding)
LLE假定每个结点与邻居在embedding空间中是线性关系。
是
和
之间的权重,则有如下定义
则最小化下式得到嵌入 :
约束 和 ,通过求解稀疏矩阵 的d+1个特征向量,实现降维
拉普拉斯特征映射(Laplacian Eigenmaps)
拉普拉斯特征映射旨在使结点间权重较大的点在嵌入空间中更近。最小化
柯西图嵌入(Cauchy Graph Embedding)
拉普拉斯特征映射使用二次惩罚函数,使得更强调“不相似性”,不利于局部特征表达。最大化:
结构保存嵌入(SPE,Structure Preserving Embedding)
拉普拉斯映射的扩展,看不懂,大概就是表达图的结构信息的
图因式分解(GF,Graph Factorization)
首次达到O(|E|)的时间复杂度,最小化
GraRep
定义结点转移概率为 ,通过最小化 来保持第k相似性
HOPE
通过最小化 来保持高维的相似性矩阵,用SVD来获取嵌入
其他的变种
PCA、LDA、ISOMAP、MDS、LPP、Kernel Eigenmaps等;ARE、TADW、HNE等
基于随机游走的方法
DeepWalk
DeepWalk通过游走的方式获取第k相似度,每次获得2k+1个结点作为路径。最大化
node2vec
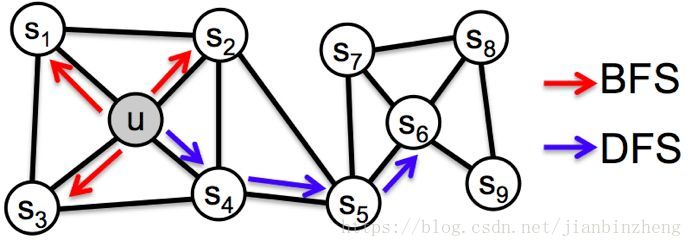
node2vec和deepwalk类似,是有权的游走,结合了BFS、DFS两种搜索
网络分级表示学习(HARP,Hierarchical Representation Learning for Networks)
DeepWalk和node2vec的目标函数非凸,可能会陷入局部最优解。HARP通过改进权重初始化来避免局部最优,对node分级聚合,将在粗糙级别的embedding用于初始化精细graph,具体embedding方式与DeepWalk、node2vec类似
Walklets
DeepWalk和node2vec更注重高阶相似关系表达,而因式分解注重结点间距离表达。Walklets综合二者,通过游走中跳过一些因式分解方法筛除的结点。
其他的变种
GenVector、DDRW(Discriminative Deep Random Walk)、TriDNR(Tri-party Deep Network Representation)
基于深度学习的方法
其实就是自编码器的扩展。。。
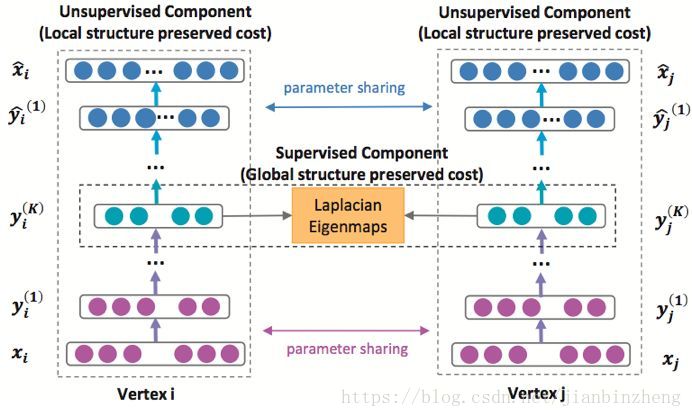
结构深度网络嵌入(SDNE,Structural Deep Network Embedding)
一种自编码器,保留了一阶、二阶的网络相似性。网络由监督部分和非监督部分组成,非监督部分即自编码器用于产生结点embedding,监督部分通过拉普拉斯特征映射使相邻结点映射空间中相近
DNGR(Deep Neural Networks for Learning Graph Representations)
没看懂,大概就是要用共现概率矩阵做点什么。。。
图卷积网络(GCN,Graph Convolutional Networks)
SDNE和DNGR将全局邻接点输入,很费计算。GCN通过在图结构上做卷积处理这个问题,通过对各个节点迭代聚合,每次计算发生在局部区域,也更可伸缩。
VGAE(Variatioinal Graph Auto-Encoders)
在图上做自编码器,用GCN来编码。
LINE方法
结合一阶相似性和二阶相似性,最小化邻接矩阵和权重概率分布的KL散度
应用
网络对比
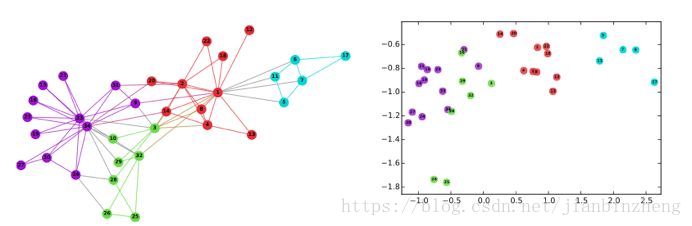
可视化
聚类
路段预测
结点分类
补几张图: