多类分类与多标签分类
- 多类分类(multi-class classification):有多个类别需要分类,但一个样本只属于一个类别
- 多标签分类(multi-label classificaton):每个样本有多个标签
区别:
对于多类分类,最后一层使用softmax函数进行预测,训练阶段使用categorical_crossentropy作为损失函数
对于多标签分类,最后一层使用sigmoid函数进行预测,训练阶段使用binary_crossentropy作为损失函数
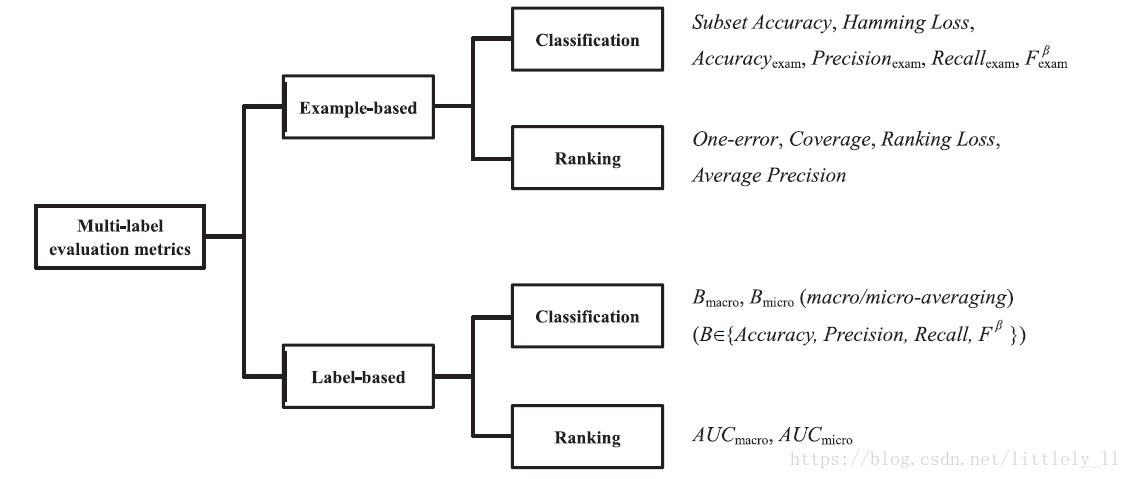
性能度量方法
主要分为基于样例(Example-based)的方法和基于标签(Label-based)的方法
假设多标签分类器为 ; 为样例的真实标签; 为样例个数; 为实值函数,返回x的标签y的置信度; 返回由 推导的按降序排列的标签y的秩
基于样例的度量方法
subset Accuracy:
它测量的是完全正确的标签的比例
Accuracy:
它衡量的是每个样例中正确标签占总标记的比例
Precision:
它衡量的是每个样例中正确标签占预测的标记的比例
Recall:
它衡量的是每个样例中正确标签占真正标签的比例
度量:
是Precision和Accuracy的综合度量,一般选择
One-error:
它衡量的是置信度最大的标签不在该样例的标签中比率
Coverage:
Ranking loss:
average Precision:
对于one-error, coverage, ranking loss,度量指标越小越好,对coverage来说,最优值为 ,对于one-error和ranking来说,最优值为0。对于基于样例的其他度量方法,值越大越好,最大值为1。
基于标签的度量方法
基于标签的度量方法类似两类分类度量问题
分别表示true positive, false positive, true nagtive, false nagtive。 。
表示具体的二分类度量如 .
Macro-average:
其中, 为标签空间
Micro-average:
对基于标签的多标签度量,度量指标越大越好,最大值为1.
深度学习的应用
在使用深度学习之前,一般使用传统的机器学习方法来进行多标签分类,其中,Zhang总结了多种分析方法。
一般深度学习应用在多标签分类中,整体的深度学习结构没有太大的差异,也就是我们常用的CNN, RNN等一些结构,多标签分类与多类分类的主要差异就是在最后输出时多类分类只要找出概率最大的那一个标签值就行了,而多标签分类是找到前几个概率最大的标签值,也就是说要设定一个阈值(threshold),这个阈值可以人为设定或根据性能度量值设定。
Berger使用了两个模型,一个是CNN,另一个是GRU模型,使用的模型结构还是普通的深度学习结构,他就是在最后模型输出时根据阈值t来确定是否给这个样本打标签i,阈值的是定是由micro-F1得分度量的。
Kurata在研究多标签分类时仍然使用了经典的CNN结构,如下图:
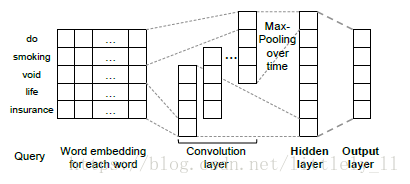
不过在最后的全连接层的参数系数有些特别,也就是上图中Hidden layer到output layer的系数是经过特别设置的。
假设你总共有标签的个数为5个,其分别是
,假设共有两个样本一个样本可能有标签为[
],另一个样本标签为[
],Hidden layer的单元个数假设为10个,
Kurata把每个样本的标签作为一个标签共现模式(label co-occurrence pattern)有多少种不同的样本标签就有多少种不同的标签共现模式,然后对Hidden layer到output layer的权重参数进行设置,如下图:
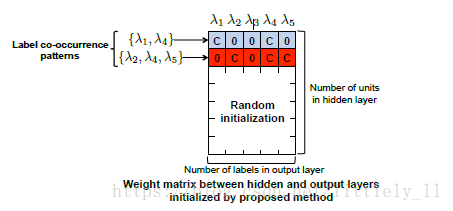

把共现的标签在系数中用一个常数C表示,其他的为0,对于这个例子,这样有2中不同的模式,因此只设定两行,系数中其他的行使用随机初始化,因此,前两行也被称为“专用神经单元”,这样经过后向传播进行训练。。
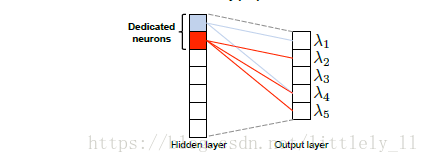
在设置那个系数时,其取常数值C可以改为正则初始化的上界
,
和
分别代表隐藏层和输出层单元的个数。
作者没说,但是这里需要注意一点,那就是隐藏层单元的个数至少为不同标签共现模式的个数。
Chen在多标签分类中使用的是CNN与RNN的结合体,在而RNN层使用的类似机器翻译的结构,如下图:
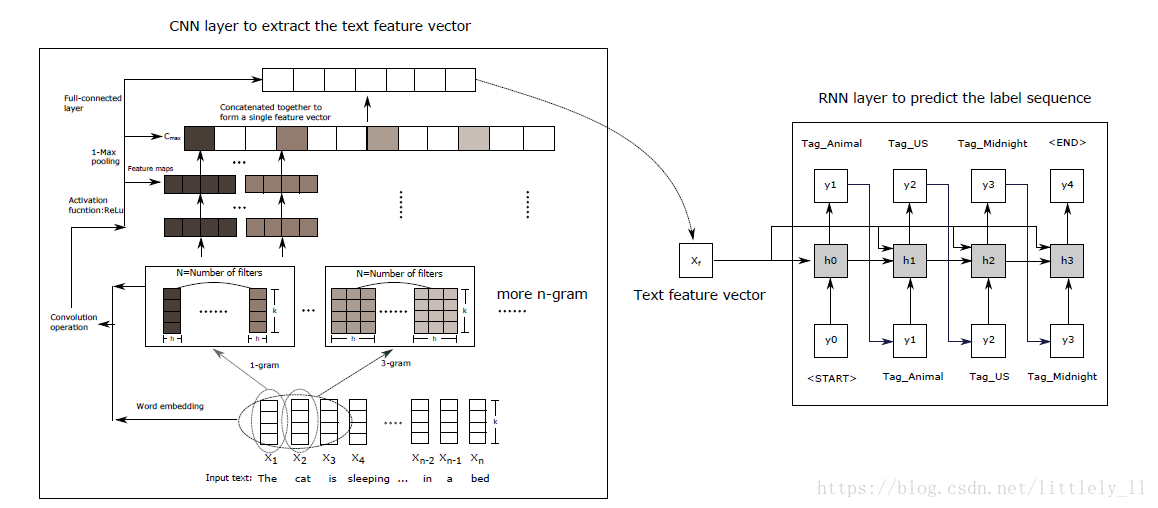
不过他最后使用的RNN这层结构我不敢认同,不同类别的标签可能完全不相关,例如上图中的多标签animal, US和midnight,而机器翻译的RNN结构前后标签是有一定的联系的,所以他直接使用机器翻译的RNN结构不太恰当。总体上结构上的改进不大。
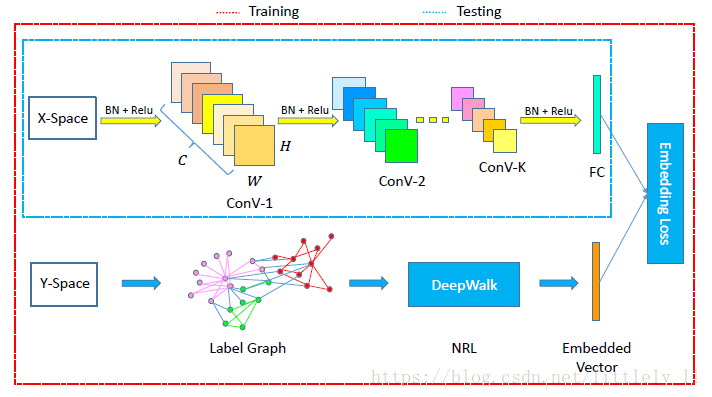
Zhang使用CNN结合deepwalk方法进行多标签的分类,并产生了很好的分类效果,结构如下图。deepwalk方法是借鉴了word2vec的原理进行空间的降维及相似性比较,得到嵌入表达,它本意是把嵌入表达学习引入到社交表达图中,而在此处使用其结构进行多标签分类,这里结合的CNN与deepwalk得到嵌入表达后运用KNN算法得到最终的多标签分类。
参考文献
【Min-Ling Zhang, Zhi-Hua Zhou】A Review on Multi-Label Learning Algorithms
【Berger】Large Scale Multi-label Text Classification with SemanticWord Vectors
【Gakuto Kurata, Bing Xiang, Bowen Zhou】Improved Neural Network-based Multi-label Classification with Better Initialization Leveraging Label Co-occurrence
【Guibin Chen, Deheng Ye, Zhenchang Xing, Jieshan Chen, Erik Cambria】Ensemble Application of Convolutional and Recurrent Neural Networks for Multi-label Text Categorization
【Wenjie Zhang, Junchi Yan, Xiangfeng Wang and Hongyuan Zha】Deep Extreme Multi-label Learning
【Bryan Perozzi,Rami Al-Rfou,Steven Skiena】DeepWalk: Online Learning of Social Representations