文本多标签分类是指对文本进行分类,一个文本可以被分到多个标签中。这种任务通常用于处理一个文本包含多种主题或者多种情感的情况。与单标签分类不同,其输出结果为多个二元分类结果。
通常采用的方法有基于传统机器学习的算法和深度学习算法。在深度学习算法中,常见的模型包括卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)和注意力机制(Attention)。数据预处理方面,通常需要将文本转换为词向量表示,并进行一些特征工程,如TF-IDF、word2vec等。
在评估多标签分类模型性能时,通常使用Precision、Recall、F1 Score等指标来评估模型的准确性和召回率。另外,在多标签分类任务中还可以使用Hamming Loss、Exact Match Ratio等指标来评估模型的整体性能。
本文的主要目的是基于CNN来开发构建文本多标签分类识别系统,首先看下对应的效果图:

接下来我们介绍一下项目整体的建模流程,如下所示:

首先从网络源采集所需要的文本数据,可以使用原始的标签数据,也可以采集下来后自行标注都是可以的,之后对文本数据进行预处理、清洗、去除停用词以及分词处理,得到干净的分词结果数据,之后我们开发构建专用的词向量模型实现原始语料数据的词向量化,同时基于TFIDF算法实现语料数据的权重计算,在后续的实验中,设计了三种特征向量融合生成算法,用于分析不同算法的优劣,模型方面主要分为两大类,深度学习模型主要是基于CNN、LSTM、GRU以及不同模型的融合、Attention融合等;机器学习模型主要是基于MLP、RF和DT这几种,完成模型的开发构建后,会基于多标签分类任务常用的几种指标如:准确率、精确率、召回率和F1值对不同模型的预测结果进行评估计算分析对比与可视化展示。
为了直观呈现语料数据,这里绘制了词云图,如下:

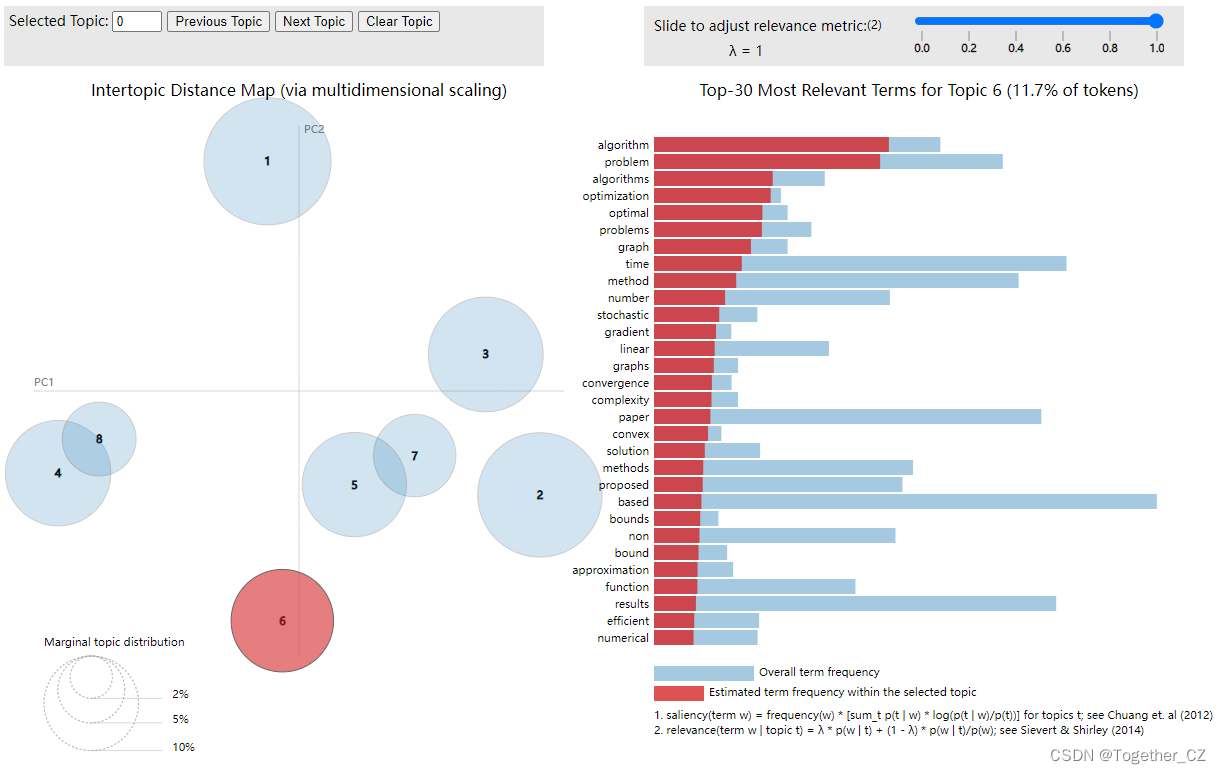
为了进一步挖掘分析语料数据,这里基于LDA主题算法实现了主题分析与挖掘计算,如下:
主题1

主题8

主题6
模型结构可视化如下:

我们这里搭建的模型是很轻量化的模型,推理速度会更快一些。
默认都是100次的迭代计算,训练可视化如下:

在同样的参数下进行了三组实验,结果对比如下:

可以看到:这里我们所设计的方法效果是最优的。
当然了这里也对机器学习的各组模型进行了实验分析,如下所示:
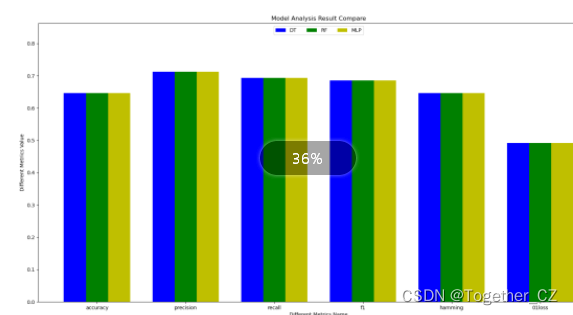
从整体效果来看,深度学习模型效果更优。
为了整合方便使用不同模型,这里开发了专用的可视化界面将所有的功能进行了整合集成,如下所示:
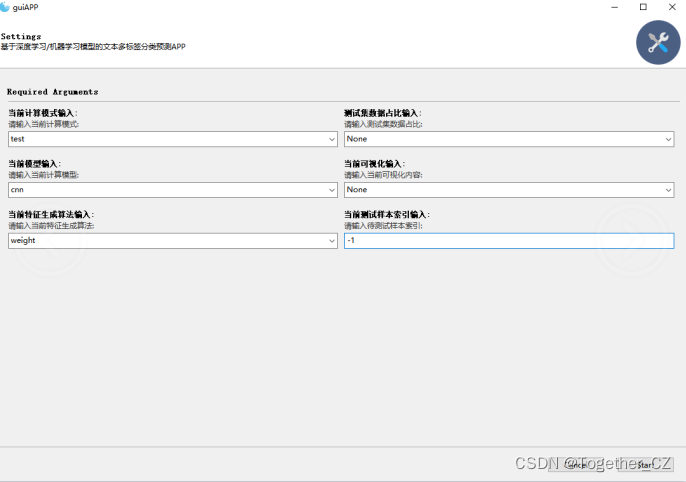
可以指定训练/测试模式:

可以选择测试集比例:
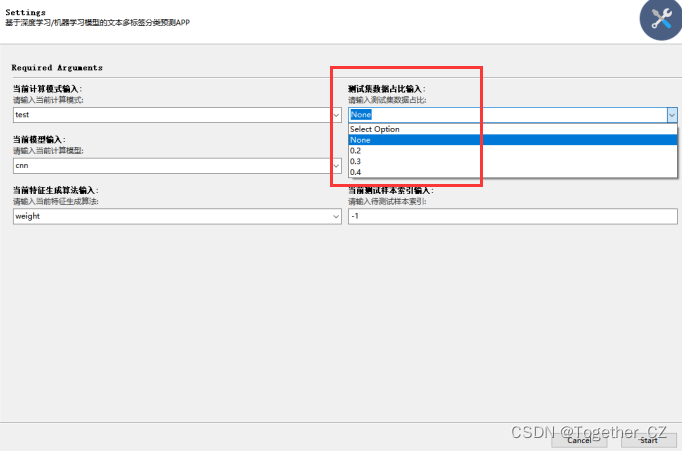
可以自由随意切换模型:

可以自由定义可视化:

可以自由选择特征算法:

可以方便进行推理预测:
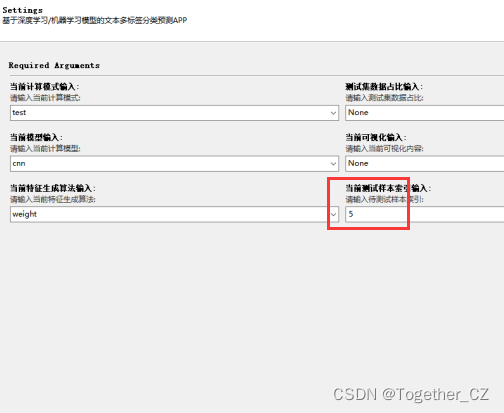
计算实例如下:
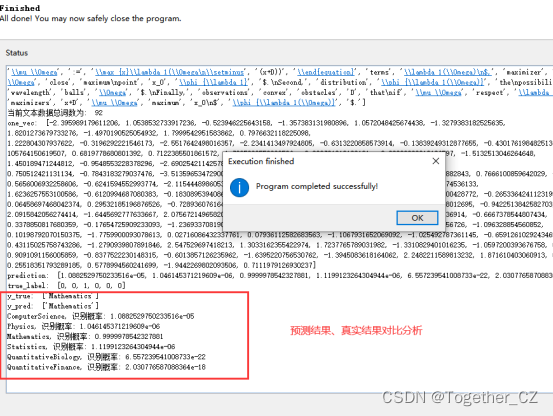

开发了整整一周的时间终于结束了,记录一下!