Scrapy:学习笔记(2)——Scrapy项目
1、创建项目
创建一个Scrapy项目,并将其命名为“demo”
scrapy startproject demo cd demo
稍等片刻后,Scrapy为我们生成了一个目录结构:

其中,我们目前需要重点关注三个文件:
- items.py:设置数据存储模板,用于结构化数据,如:Django的Model。
- pipelines.py: 定义数据处理行为,如:一般结构化的数据持久化
- settings.py:配置文件,如:递归的层数、并发数,延迟下载等
1.1、明确爬虫开发的四个步骤
项目已经创建完成了,为了指导接下来的开发,我们必须明确Scrapy爬虫的四个步骤:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
所以,接下来我们需要明确目标。
2、明确目标
以我的博客网站为例,爬取文章的关键信息(标题、摘要、上传时间、阅读数量)

2.1、编写items.py文件
-
打开 demo 目录下的 items.py。
-
Item 定义结构化数据字段,用来保存爬取到的数据,有点像 Python 中的 dict,但是提供了一些额外的保护来减少错误。
-
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个 Item(可以理解成类似于 ORM 的映射关系)。
正如下面这样:
import scrapy
class DemoItem(scrapy.Item):
# define the fields for your item here like:
postTitle = scrapy.Field()
postDate = scrapy.Field()
postDesc = scrapy.Field()
postNumber = scrapy.Field()
3、制作爬虫
3.1、快速生成爬虫
Scrapy提供了相关命令来帮助我们快速生成爬虫结构,执行下面语句,来生成名为basic的爬虫:
scrapy genspider basic web
它的结构如下:
import scrapy
class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['web']
start_urls = ['website']
def parse(self, response):
pass
它确定了三个强制属性和方法:
- name = "basic" :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
- allow_domains = [] :是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
- start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
- parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
3.2、取数据
我们在前面已经讲解了XPath的基本使用,此处不在赘述。
这一过程,我们需要观察网页源代码。首先每一页的博客是根据日期可以分为几大块,然后每一块内依次排列这每一篇文章的各项信息。
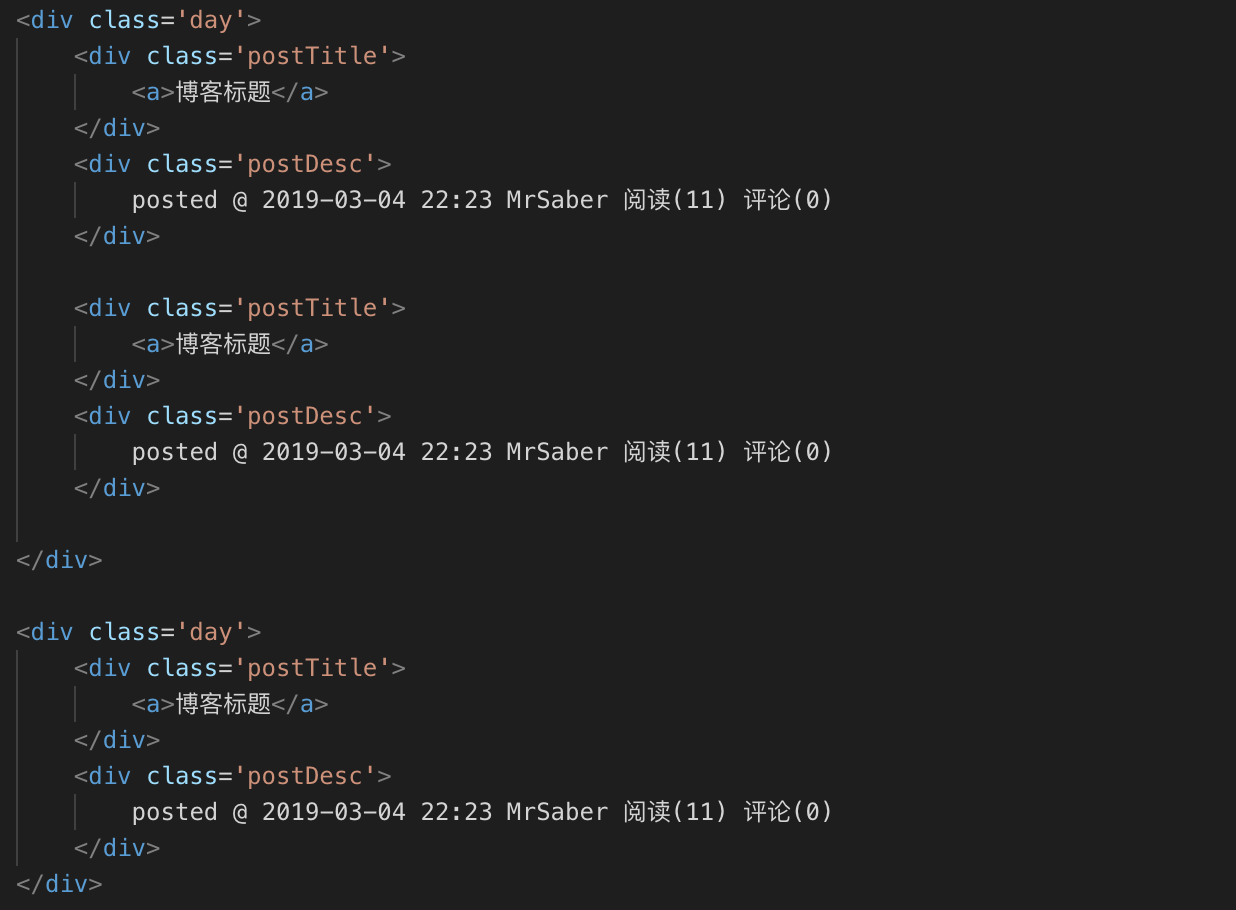
根据抽象出的结构,我们取出数据要爬出的数据。
import scrapy
from demo.items import DemoItem
class BasicSpider(scrapy.Spider):
name = 'basic'
allowed_domains = ['web']
start_urls = ['https://www.cnblogs.com/MrSaver/default.html?page=1']
def parse(self, response):
posts = response.xpath('//div[@class="day"]')
result = []
for each_day_post in posts:
day_postTitles = each_day_post.xpath('./div[@class="postTitle"]/a[@class="postTitle2"]/text()').extract();
day_postDescs = each_day_post.xpath('./div[@class="postDesc"]/text()').extract();
if isinstance(day_postTitles, list):
if (len(day_postTitles) == 1):
tmp = DemoItem()
tmp['postTitle'] = day_postTitles
tmp['postDesc'] = day_postDesc
result.append(tmp);
else:
for i in range(len(day_postTitles)):
tmp = DemoItem()
tmp['postTitle'] = day_postTitles[i]
tmp['postDesc'] = day_postDesc[i]
result.append(tmp);
return result
4、保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,命令如下:
scrapy crawl basic -o items.json
json lines格式,默认为Unicode编码
scrapy crawl basic -o items.jsonl
csv 逗号表达式,可用Excel打开
scrapy crawl basic -o items.csv
xml格式
scrapy crawl basic -o items.xml