一、Scrapy简介
Scrapy,Python开发的一个快速(基于异步处理框架Twisted)、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
二、Scrapy的构成
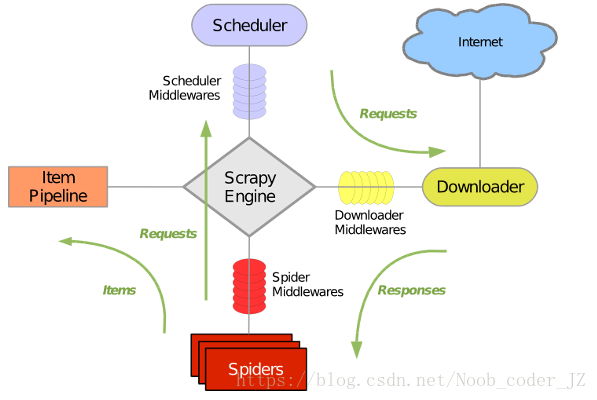
Scrapy主要由以下组件组成:
Scheduler:url调度器,接收来自Scrapy Engine的请求,并压入队列,在Scrapy Engine需要的时候返回。即在调度器里面由个url队列,按照某种优先级存放着许多url,新来的url放在队尾,引擎发出请求则将第一个url出队。
Spiders:即爬虫,对下载器下载好的网页进行爬取,爬取好的数据填充到item里。
Downloader:即下载器,根据引擎包装好的Requests对互联网上的服务器发出请求,并将返回的Responses交给爬虫进行数据的爬取。
Scrapy Engine:整个爬虫框架的引擎,为其他几个组建的纽带。
Item Pipeline:对爬虫爬取到的数据进行处理,有点像Django里的Models.
另外还有三个中间件:
Scheduler Middlewares:处于引擎与调度器间,处理引擎与调度器之间的请求与响应。
Spiders Middlewares:处于Spider与引擎之间,处理引擎与爬虫之间的请求与响应。
Downloader Middlewares:处于下载器与引擎之间,处理引擎与下载器之间的请求与响应。
Scrapy的运行大概流程为:
1.Scrapy Engine向调度器发出请求,得到一个url后封装成request发送给下载器
2.下载器将request进行请求,然后将得到的response发送给爬虫
3.爬虫对收到的response进行数据的爬取。
4.爬虫将解析到的实体交给管道进行进一步处理,将解析到的url发送给调度器等待请求。
三、Scrapy的安装
直接命令行安装
pip3 install scrapy
如果出现某个依赖下载错误可以再执行上面的命令一次,如果不成功则pip3 install 缺少的包。