介绍
快速排序实现简单,适用于各种不同的输入数据且在一般应用中比其他排序算法都要快得多。快速排序的特点是它是原地排序,且将长度为N的数组排序的时间和NlgN成正比。它的主要缺点是非常脆弱,在实现时要非常小心才能避免低劣的性能。
基本算法
快速排序是一种分治的排序算法。它将一个数组分成两个子数组,将两部分独立地排序。当两个子数组都有序时整个数组就有序了。在快速排序中,切分的位置取决于数组的内容。算法流程大致如下:

public static void sort(Comparable[] a){
Arrays.sort(a, new Comparator<Comparable>() {
@Override
public int compare(Comparable o1, Comparable o2) {
return Math.random() >= 0.5 ? 1 : -1;
}
});
sort(a, 0, a.length - 1);
}
private static void sort(Comparable[] a, int low, int high){
if(high <= low) return;
int k = partition(a, low, high);
sort(a, low, k - 1);
sort(a, k + 1, high);
}切分过程
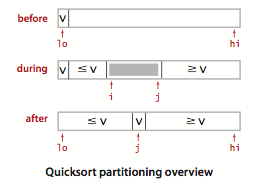
快速排序的关键在于切分,这个过程使得数组满足下面三个条件:
- 对于某个j,a[j]已经排定。
- a[lo]到a[j - 1]中的所有元素都不大于a[j]。
- a[j+1]到a[high]中的所有元素都不小于a[j]。
一般策略是先随意地取a[low]作为切分元素,即那个将会被排定的元素,然后我们从数组的左端开始向右扫描直到找到一个小于等于它的元素,再从数组的右端开始向左扫描直到找到一个大于等于它的元素。这两个元素显示是没有排定的,因此交换它们的位置。如此继续,我们就可以保证左指针i的左侧元素都不大于切分元素,右指针j的右侧元素都不小于切分元素。当两个指针相遇时,我们只需要将切分元素a[low]和左子数组最右侧的元素(a[j])交换然后返回j即可。
private static int partition(Comparable[] a, int low, int high){
int i = low, j = high + 1;
Comparable v = a[low];
while (true){
while (less(a[++i], v)){
if(i == high) break;
}
while (less(v, a[--j])){
if(j == low) break;
}
if(i >= j) break;
exchange(a, i, j);
}
exchange(a, j, low);
return j;
}性能特点
快速排序切分方法的内循环会用一个递增的索引将数组元素和一个定值进行比较。这种简洁性也是快速排序的一个优点。很难想象排序算法中还能有比这更短小的内循环了。例如,归并排序和希尔排序一般都比快速排序慢,其原因就是它们还在内循环中移动数据。
快速排序另一个速度优势在于它的比较次数很少。排序效率最终还是依赖切分数组的效果,而这依赖于切分元素的值。切分将一个较大的随机数组分成两个随机子数组。而实际上这种分割可能发生在数组的任意位置(对于元素不重复的数组而言)。
其他定理证明:
- 长度为N的无重复数组排序,快速排序平均需要~2NlnN次比较(以及1/6的交换)。
- 快速排序最多需要约
次比较,但随机打乱数组能够预防这种情况。
算法改进
- 切换到插入排序:对于小数组,快速排序比插入排序慢。因为递归,快速排序的sort()方法在小数组中也会调用自己。当hight <= low + M时切换到插入排序,转换参数M的最佳值是和系统相关的,但是5~15之间的任意值在大多数情况下都能令人满意。
- 三取样切分:使用子数组的一小部分元素的中位数来切分数组。这样做得到的切分更好,但代价是需要计算中位数。人们发现将取样大小设为3并用大小居中的元素切分的效果最好。
- 去掉partition()中的数组边界测试:将取样元素放在数组末尾作为“哨兵”。
private static int partition(Comparable[] a, int low, int high){
int i = low, j = high + 1;
exchange(a, low, medium3(a, low, (low + high) / 2, high));
Comparable v = a[low];
while (less(a[++i], v)){
if(i == high) return high;
}
while (less(v, a[--j])){
if(j == low + 1) return low;
}
while (i < j){
exchange(a, i, j);
while (less(a[++i], v));
while (less(v, a[--j]));
}
exchange(a, j, low);
return j;
}三向切分的快速排序
在有大量重复元素的情况下,快速排序的递归性会使元素全部重复的子数组经常出现,这就有很大的改进潜力。三向切分是指将数组切分为三部分,分别对应小于、等于和大于切分元素的数组元素。
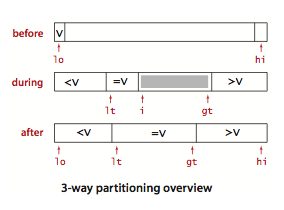

在数组中重复元素不多的普通情况下三向切分比标准的二分法多使用了很多次交换。
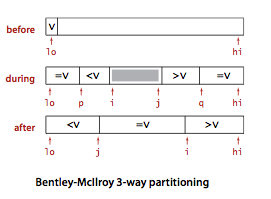
BentlyMcIIroy三向切分
用将重复元素放置于子数组两端的方式实现一个信息量最优的排序算法。使用两个索引p和q,使得a[low..p-1]和a[q+1..hi]的元素都和a[lo]相等。使用另外两个索引i和j,使得a[p...i-1]小于a[low],a[j+1...q]大于a[low]。在内循环中加入代码,在a[i]和v相当时将其与a[p]交换(并将p+1),在a[j]和v相等且a[i]和a[j]尚未和v进行比较之前将其与a[q]交换。