AUC(area under the curve)是ROC曲线的面积,那么ROC曲线是横坐标为FPR(假正率)纵坐标TPR(真正率)组合,随着样本阈值的不断变化,(FPR,TPR)不断变化形成的曲线。FPR和TPR是通过混淆矩阵下求得。
所以简单回顾一下上一篇,ROC曲线并不是光滑的,因为阈值的变化并不一定影响到样本的变化,所以应该是阶梯型的。
AUC值的意义
我们首先看一下下面的图:

纵坐标为样本数,横坐标为预测为正例概率。红颜色的为正样本概率分布,蓝颜色的为负样本概率分布。所以红色的部分越趋向于1,蓝色部分越趋向于0越好。
判断分类器的好坏,需要设置阈值来计算

当阈值设置为0.5的时候,准确率(TP/(TP+FP))为90%。引入ROC

阈值为0.8的时候,对应箭头的点。


阈值为0.5时,对应箭头的点。不同的阈值对应不同的点,炼成线就是ROC曲线。

从图形中可以看出,因为红色蓝色区域重叠的部分不多,ROC距离左上角非常近。

当红蓝区域重叠后,ROC曲线接近y=x
从上面几个图中可以看出,我们可以根据ROC曲线的面积来判断分类器的好坏。这个就是AUC。AUC表示是正例排在负例前面的概率。
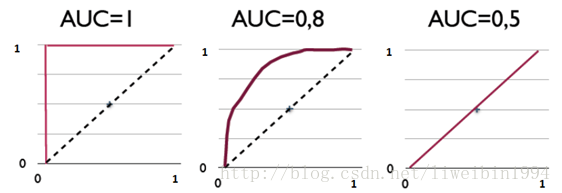
第一个坐标系的AUC值表示,所有的正例都排在负例的前面。第二个AUC值,表示有百分之八十的正例排在负例的前面。
AUC评估考虑到阈值的变动,所以评估效果更好。

(a)和©为ROC曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,©和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线则变化较大。
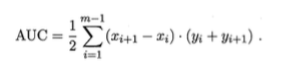
AUC = 1,代表完美分类器
0.5 < AUC < 1,优于随机分类器
0 < AUC < 0.5,差于随机分类器
AUC如何求解
步骤如下:
1.得到结果数据,数据结构为:(输出概率,标签真值)
2.对结果数据按输出概率进行分组,得到(输出概率,该输出概率下真实正样本数,该输出概率下真实负样本数)。这样做的好处是方便后面的分组统计、阈值划分统计等
3.对结果数据按输出概率进行从大到小排序
4.从大到小,把每一个输出概率作为分类阈值,统计该分类阈值下的TPR和FPR
5.微元法计算ROC曲线面积、绘制ROC曲线
总结
1.ROC曲线反映了分类器的分类能力,结合考虑了分类器输出概率的准确性
2.AUC量化了ROC曲线的分类能力,越大分类效果越好,输出概率越合理
3.AUC常用作CTR的离线评价,AUC越大,CTR的排序能力越强
准确率,又称查准率(Precision,P):
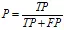
召回率,又称查全率(Recall,R):
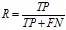
F1值:
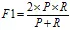
F1的一般形式
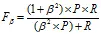
Β>0度量了查全率对查准率的相对重要性;β=1退化为F1;β>1查全率有更大影响;β<1查准率有更大影响。
回归模型评估指标
回归是对连续的实数值进行预测,即输出值是连续的实数值,而分类中是离散值。对于回归模型的评价指标主要有以下几种:
RMSE(root mean square error,平方根误差),其又被称为RMSD(root mean square deviation),RMSE对异常点(outliers)较敏感,如果回归器对某个点的回归值很不理性,那么它的误差则较大,从而会对RMSE的值有较大影响,即平均值是非鲁棒的。其定义如下:
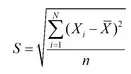
Quantiles of Errors 为了改进RMSE的缺点,提高评价指标的鲁棒性,使用误差的分位数来代替,如中位数来代替平均数。假设100个数,最大的数再怎么改变,中位数也不会变,因此其对异常点具有鲁棒性。
参考:
https://www.jianshu.com/p/498ea0d8017d
https://blog.csdn.net/mingyuli/article/details/81184674
https://blog.csdn.net/liweibin1994/article/details/79462554