2.模型评估与选择
2.1经验误差和过拟合
不同学习算法及其不同参数产生的不同模型,涉及到模型选择的问题,关系到两个指标性,就是经验误差和过拟合。
1)经验误差
错误率(errorrate):分类错误的样本数占样本总数的比例。如果在m个样本中有a个样本分类错误,则错误率E=a/m,相应的,1-a/m称为精度(accuracy),即精度=1-错误率。
误差(error):学习器的实际预测输出和样本的真实输出之间的差异。训练误差或经验误差:学习器在训练集上的误差;泛化误差:学习器在新样本上的误差。
自然,理想情况下,泛化误差越小的学习器越好,但现实中,新样本是怎样的并不知情,能做的就是针对训练集的经验误差最小化。
那么,在训练集上误差最小、甚至精度可到100%的分类器,是否在新样本预测是最优的吗?
我们可以针对已知训练集设计一个完美的分类器,但新样本却是未知,因此同样的学习器(模型)在训练集上表现很好,但却未必在新样本上同样优秀。
2)过拟合
学习器首先是在训练样本中学出适用于所有潜在样本的普遍规律,用于正确预测新样本的类别。这会出现两种情况,导致训练集上表现很好的学习器未必在新样本上表现很好。
过拟合(overfitting):学习器将训练样本的个体特点上升到所有样本的一般特点,导致泛化性能下降。
欠拟合(underfitting):学习器未能从训练样本中学习到所有样本的一般特点。
通俗地说,过拟合就是把训练样本中的个体一般化,而欠拟合则是没学习到一般特点。一个是过犹不及;一个是差之毫厘。过拟合是学习能力太强,欠拟合是学习能力太弱。
欠拟合通过调整模型参数可以克服,但过拟合确实无法彻底避免。机器学习的问题是NP难,有效的学习算法可在多项式时间内完成,如能彻底避免过拟合,则通过经验误差最小化就能获得最优解,这样构造性证明P=NP,但实际P≠NP,过拟合不可避免。
总结,在模型选择中,理想的是对候选模型的泛化误差进行评估,选择泛化误差最小的模型,但实际上无法直接获得泛化误差,需要通过训练误差来评估,但训练误差存在过拟合现象也不适合作为评估标准,如此,如何进行模型评估和选择呢?
2.2评估方法
评估模型既然不能选择泛化误差,也不能选择训练误差,可以选择测试误差。所谓测试误差,就是建立测试样本集,用来测试学习器对新样本的预测能力,作为泛化误差的近似。
测试集,也是从真实样本分布中独立同分布采样而得,和训练集互斥。通过测试集的测试误差来评估模型,作为泛化误差的近似,是一个合理的方法。对数据集D={(x1,y1), (x2,y2),…, (xm,ym)}进行分隔,产生训练集S和测试集T,通过训练集生成模型,并应用测试集评估模型。文中有个很好的例子,就是训练集相当于测试题、而测试集相当于考试题。
现在我们将问题集中在测试集的测试误差上,用以评估模型。那重要的是,对数据集D如何划分成训练集和测试集从而获得测试误差?
1)留出法
留出法(hold-out)将数据集D划分为两个互斥的集合,其中一个集合用作训练集S,另一个作为测试集T,即D=SUT,S∩T=∅。在S上训练出的模型,用T来评估其测试误差,作为对泛化误差的近似估计。
以二分类任务为例。假定D包含1000个样本,将其划分为700个样本的训练集S和300个样本的测试集T。用S训练后,模型在T上有90个样本分类错误,那么测试误差就是90/300=30%,相应地,精度为1-30%=70%。
留出法就是把数据集一分为不同比例的二,这里面就有两个关键点,一个就是如何分?另一个就是分的比例是多少?
如何分呢?训练集和测试集的划分要保持数据分布的一致性。何意?分层采样,保持样本的类别比例相似,就是说样本中的各类别在S和T上的分布要接近,比如A类别的样本的比例是S:T=7:3,那么B类别也应该接近7:3这个分布。
在分层采样之上,也存在不同的划分策略,导致不同的训练集和测试集。显然,单次使用留出法所得到的估计结果不够稳定可靠,一般情况下采用若干次随机划分、重复进行试验评估后取平均值作为评估结果。
S和T各自分多少呢?若训练集S过多而测试集T过小,S越大越接近D,则训练出的模型更接近于D训练出的模型,但T小,评估结果可能不够稳定准确;若训练集S偏小而测试集T偏多,S和D差距过大,S训练的模型将用于评估,该模型和D训练出的模型可能有较大差别,从而降低评估结果的保证性(fidelity)。S和T各自分多少,没有完美解决方法,通常做法是二八开。
2)交叉验证法
交叉验证法(crossvalidation)将数据集D划分为k个大小相似的互斥子集,即D=D1UD2U…UDk,Di∩Dj=∅(i≠j);每个子集Di都尽可能保持数据分布的一致性,即从D中通过分层采样所得。训练时,每次用k-1个子集的并集作为训练集,余下的一个子集作为测试集;如此,可获得k组训练集和测试集,从而进行k次训练和测试,最终返回k次测试结果的均值。k值决定了交叉验证法评估结果的稳定性和保真性,因此也称为k折交叉验证或k倍交叉验证,k常取值10、5、20,10折交叉验证示意图如下:
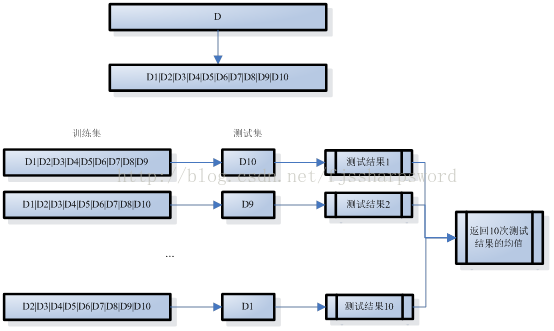
和留出法一样,将数据集D划分为k个子集也是多样划分方式,为减小样本划分不同而发生的差别,k折交叉验证通常随机使用不同的划分重复p次,最后评估结果是这p次k折交叉验证结果的均值,如10次10折交叉验证。
典型的划分特例留一法(Leave-One-Out,LOO),假设数据集D中包含m个样本,令k=m,就是每个子集只包含一个样本。这个特例,不受随机样本划分方式的影响,且训练集S只比数据集D少一个样本,其实际训练出的模型和期望评估的用D训练出的模型相似,其评估结果比较准备。当然,问题就是一个样本一个子集,一旦样本过大,训练的模型所需开销也是极其庞大,且其评估结果也未必比其他方法准确。
实际,所有算法都是如此,有其优点有其缺点,各有适用场合,符合性价比原则。比如留一法,为了提升理论上的准确性,而牺牲相对明确庞大的开销,效益上是否可取,那要看场合了。
3)自助法
在留出法和交叉验证法中,训练集S的样本数是小于数据集D,因样本规模不同会导致所训练的模型及评估结果偏差。留一法虽然S只少一个样本,但计算规模庞大。那么有没办法避免样本规模影响且能高效计算呢?
自助法,基于自助采样获取训练集和测试集。给定包含m个样本的数据集 ,如何通过自助采样(可重复采样或有放回采样)产生数据集D’呢?自助采样基本过程是:每次随机从D中选一个样本,放入D’,然后将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行m次后,就得到了包含m个样本的数据集D’,规模和D一样,不同的是,D’中部分样本可能重复也有部分样本可能不出现。一个样本在m次自助采样中都没有被采到的概率是(1-1/m)m,取极限得到:
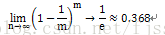
即通过自助采样,初始数据集D中约有36.8%的样本未出现在采样数据集D’中。自助采样后 ,将样本规模和数据集D一样的采样数据集D’作为训练集S=D’,将T=D-D’作为测试集(不在D’中的样本作为测试集)。如此,实际评估的模型(训练集S训练出的)与期望评估的模型(数据集 D训练出的)使用了同样的样本规模(m个样本),同时又有大概36.8%的样本(未在采样数据集D’中)作为测试集T用于测试,产生的测试结果,称为包外估计(out-of-bag estimate)。
每个算法都有自己的使用场合,并不是万能性地好用高效。自助法自助采样产生的数据集D’也是改变了初始数据集D的分布,也会引入估计偏差。自助法适用于数据集较小、难以有效划分训练集和测试。在初始数据量足够时,留出法和交叉验证法更常用一些。
为更好地对模型(学习器)进行泛化性能评估,提出了近似的测试误差来评估泛化误差,也就衍生出了留出法、交叉验证法、自助法的数据集划分方法。实际上,算法还需要调参,不同的参数配置,模型的性能会有一定差别。在进行模型评估和选择时,除了选择算法还有数据集划分方法外,还需要对算法参数进行设定或说是调节。每一个算法都有参数设定空间,假定算法有3个参数,每个参数有5个可选值,对每一组训练集/测试集来说就有53=125个模型需要考察。
实际的学习过程中,对给定包含m个样本的数据集D,先选定学习算法及其参数,然后划分数据集训练和测试,直至选定算法和参数,再应用数据集D来重新训练模型。在研究对比不同算法的泛化性能时,用测试集上的判别效果来评估模型在实际使用中的泛化能力,而把训练数据另外划分为训练集和验证集,基于验证集上的性能进行模型选择和调参。
梳理下几个要点:1)将数据集划分为:训练集、验证集、测试集;2)训练集用于训练出模型,验证集用于模型选择和调参,测试集用于近似评估泛化误差;3)模型评估方法有留出法、交叉验证法、自助法,用于算法选择及参数设定。
2.3性能度量
通过在训练过程中的评估方法来判定学习器的泛化性能,还需要通过性能度量来考察。换句话来说,选什么模型,通过训练集、验证集、测试集来实验评估选定并输出;而所输出的模型,在测试集中实的泛化能力,需要通过性能度量工具来度量。这样理解,基于测试误差近似泛化误差的认定,通过划分数据集为训练集、验证集、测试集,并选择不同的评估方法和调整算法参数来输出的模型,需要通过性能度量的工具来量化评估。
不同的性能度量,在对比不同模型能力时,会导致不同评判结果,因为模型的好坏是相对的。实际模型的好坏,取决于算法和数据,取决于训练中调参和实验评估方法,也取决于当前任务的实际数据。
模型训练出来后,进行预测时,给定样例集D={(x1,y1), (x2,y2),…, (xm,ym)},其中yi是示例xi的真实标记,要评估学习器f的性能,把学习器预测结果f(x)与真实标记y进行比较。
预测回归任务最常用的性能度量是均方误差(mean squared error):


| 真实情况 |
预测结果 |
|
| 正例 |
反例 |
|
| 正例 |
TP(真正例) |
FN(假反例) |
| 反例 |
FP(假正例) |
TN(真反例) |
查准率P和查全率R分别定义为:
P=TP/(TP+FP)
R=TP/(TP+FN)
查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。在信息检索中,查准率就是检索出的信息有多少比例是用户感兴趣的;查全率则是用户感兴趣的信息有多少被检索出来。查准率分母中就包含了那些不是用户感兴趣的信息,但仍被预测为是用户感兴趣的而被检索出来;查全率分母中则包含了那些是用户感兴趣的信息,但为被预测为用户感兴趣而被抛弃未检索出来。
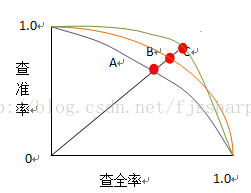
可根据学习器的预测结果对样例进行排序,排在前面的是学习器认为最可能是正例的样本,排在最后的则是学习器认为最不可能是正例的样本。按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的查全率、查准率,并以查准率为纵轴、查全率为横轴构造查准率-查全率曲线,简称P-R曲线。
P-R曲线是非单调、不平滑的。P-R曲线可用来评估学习器的优劣。若一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则后者的性能优于前者。如果两个学习器的曲线发生交叉,则通过二者面积的大小来比较,面积大的表示查全率和查准率双高比较优秀,但不太容易计算曲线(不平滑)的面积,因此通过平衡点(Break-Even Point,简称BEP)来度量。BEP是坐标上查准率等于查全率时的点,平衡点值越大,学习器越优秀。
用了简单的图来说明,红色的点就是三条P-R曲线的BEP点,学习器A的曲线被C包住,C比较优秀,而C和B交叉,用面积计算难以估算,但C的BEP值大于B,所以C比较优秀。
ERP过于简化,定义F1常量来比较学习器P-R曲线的性能:
F1=2*P*R/P+R=2*TP/(样例总数+TP-TN)
不同的应用场合,对查全率和查准率的侧重不同,如在商品推荐中,为尽可能少打扰用户,希望推荐的内容却是用户所感兴趣的,查准率更重要;在逃犯信息检索中,希望尽可能少漏掉逃犯,此时查全率更重要。对查准率和查全率的不同偏好,可用F1度量的一般形式Fβ,定义为:
Fβ=(1+β2)*P*R/((β2*P)+R)
其中β>0度量了查全率对查准率的相对重要性;β=1时就是标准的F1;β>1时偏好查全率;β<1时偏好查准率。
F1是基于查准率和查全率的调和平均(harmonic mean)定义:
1/F1=1/2*(1/P+1/R)
Fβ则是加权调和平均:
1/ Fβ=1/(1+β2)*(1/P+β2/R)
与算术平均(P+R)/2和几何平均 相比,调和平均更重视较小值。
几何平均数:N个数据的连乘积的开N次方根。
算术平均数:一组数据的代数和除以数据的项数所得的平均数.
调和平均数:一组数据的倒数和除数据的项数的倒数。
平方平均数:一组数据的平方和除以数据的项数的开方。
对同一数据,调和≤几何≤算术≤平方。
进行多次训练和测试、在多个数据集上进行训练和测试、执行多分类任务时每两两类别组合对应的混淆矩阵,这些情况系下产生的多个混淆矩阵,需要估计算法的全局性能,即在n个二分类混淆矩阵上考察查准率和查全率,从而评估模型性能。这个有两种做法,一个是求得P和R再平均;另一个是直接对TP、FP、TN、FN求取平均值后再得P和R值;分别为宏查全率和宏查准率、微查全率和微查准率。
3)ROC与AUC
很多学习期为测试样本产生一个实值或概率预测,然后将这个预测值和分类阈值进行比较,若大于阈值则分类正类,否则为反类。对测试样本的实值或概率预测结果进行排序,最可能是正例的排在最前面,最不可能是正例的排在最后面。分类过程就相当于在这个排序中以某个截断点将样本分为两部分,前一部分判为正例,后一部分则判为反例。
在不同的应用任务中,可根据任务需求来采用不同的截断点,选择排序中靠前的位置进行截断重视查准率;选择靠后的位置进行截断则重视查全率。排序本身的质量好坏,体现了学习器在不同任务下的期望泛化性能的好坏,或者说,一般情况下泛化性能的好坏。ROC曲线正是考量期望泛化性能的性能度量工具,适用于产生实值或概率预测结果的学习器评估。
ROC(ReceiverOperating Characteristic,受试者工作特征),根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别作为横、纵坐标,即得到ROC曲线。
ROC曲线的纵轴是真正例率(The Positive Rate,TPR),横轴是假正例率(FalsePositive Rate,FPR),分别定义为:
真正例率:TPR=TP/(TP+FN),预测的真正例数和实际的正例数比值,有多少真正的正例预测准确;
假正例率:FPR=FP/(TN+FP),预测的假正例数和实际的反例数比值,有多少反例被预测为正例;
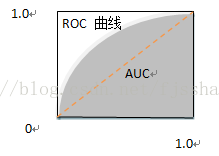
从图中可以看出ROC曲线的对角线对应于随机猜测模型,而点(0,1)则对应于将正例排在所有反例之前的理想模型,真正例率是100%。
在实际任务中,样本是有限的,所以不能产生光滑的ROC曲线,而是带有齿状的近似ROC曲线。有限个测试样例ROC图绘制方法:给定m+个正例和m-个反例,根据学习器预测结果对样例进行排序,开始把分类阈值设为最大(所有样例均预测为反例),此时真正例率和假正例率均为0,在坐标(0,0)处标记一个点;然后,依次将分类阈值设为每个样例的预测值(依次将每个样例划分为正例),并求解真正例率和假正例率,在相应的坐标处标记一个点。设前一个标记点坐标为(x,y),当前若为真正例,则对应比较点的坐标为(x,y+1/ m+);当前若为假正例,则对应标记的点的坐标为(x+1/ m-,y),最后用线段把相邻的点连接起来即得近似ROC曲线。
接着,自然是要说到用ROC曲线怎么比较学习器的优劣呢?和P-R曲线相似,若一个学习器的ROC曲线被另一个学习器的曲线完成包住,则后者的性能优于前者。若两个学习器的ROC曲线发生交叉,要进行比较的话,就需要比较ROC曲线下的面积,即AUC(AreaUnder ROC Curve)。
AUC可通过对ROC曲线下各部分的面积求和而得。假定ROC曲线是由坐标为{(x 1 ,y 1 ), (x 2 ,y 2 ),…, (x m ,y m )}的点按序链接而形成(x 1 =0,x m =1),则AUC估算为:

| 真实类别 |
预测类别 |
|
| 第0类 |
第1类 |
|
| 第0类 |
0 |
cost01 |
| 第1类 |
Cost10 |
0 |
如上表,整体学习器性能评估上,不是考虑最小化错误次数,而是最小化总体代价。假设上表的第0类为正类,第1类为反类,令D+和D-分别表示正、反例集合,则代价敏感(cost-sensitive)错误率为:

其中FPR是假正例率,FNR=1-TPR是假反例率。代价曲线的绘制:ROC曲线上的每一点对应了代价平面上的一条线段,设ROC曲线上点的坐标为(TPR,FPR),则可相应计算出FNR,然后在代价平面上绘制一条从(0,FPR)到(1,FNR)的线段,线段下的面积表示了该条件下的期望总体代价。如此,将ROC曲线上的每个点转化为代价平面上的一条线段,然后去所有线段的下界,围城的面积即为在所有条件下学习器的期望总体代价。
5)总结
对学习器的性能度量是选择学习器的参考,下面对几个性能度量指标进行分类:
| 类别 |
性能度量指标 |
||
| 均等代价 |
非均等代价 |
||
| 预测分类的学习器 |
P-R曲线和F1 |
代价敏感错误率 |
|
| 预测实值的学习器 |
ROC曲线和AUC |
代价曲线 |
|
对于常用的错误率和精度,也是用于预测分类的学习器性能度量。实际上,不同的任务需要采用不同的指标来度量,同时在指标上具体的侧重也不同。
2.4比较检验
对学习器的性能评估,基于测试集已经给出了评估方法和衡量模型泛化能力的性能度量工具,那么是否就可以通过对性能度量的值比较来评估学习器优劣呢?显然答案不是那么肯定,因为测试集上的性能评估方法和度量工具始终还是测试集上的,与测试集本身的选择有关系,且机器学习算法本身存在一定随机性。统计假设检验(hypothesis test)为学习器性能比较提供了重要依据。
基于假设检验结果可推断出,在测试集上观察到的学习器A优于B,则A的泛化性能是否在统计意义上好于B,以及这个判定的准确度。也就是说,在测试集上的评估和度量,放在统计意义上进一步检验。以错误率为性能度量工具,用e表示,介绍假设检验方法。
1)单个学习器的假设检验
假设检验中的假设是对学习器泛化错误率分布的某种判断或猜想。在统计意义上,对泛化错误率的分布进行假设检验。现实任务中,只知测试错误率,而不知泛化错误率,二者有差异,但从直观上,二者接近的可能性较大,而相差很远的可能性很小,因此可基于测试错误率推出泛化错误率的分布。
实际上,评估方法和性能度量,正式基于上面这一统计分布直观思维来开展,这里更是通过假设检验来进一步肯定测试错误率和泛化错误率二者接近。




| 数据集 |
算法A |
算法B |
算法C |
| D1 |
1 |
2 |
3 |
| D2 |
1 |
2.5 |
2.5 |
| D3 |
1 |
2 |
3 |
| D4 |
1 |
2 |
3 |
| 平均序值 |
1 |
2.125 |
2.875 |

2.5偏差与方差
通过实验方法估计的泛化性能,还需要解释其具有这样性能的原因,回答为什么具有这样的性能。偏差-方差分解是解释学习算法泛化性能的一种重要工具。
梳理下模型评估与选择的整个思路:首先模型评估面临经验误差和过拟合现象,因此引入测试集,通过测试误差率近似泛化误差率来评估模型,提出了评估方法,并量化度量性能,在此基础上通过假设检验为性能度量提供依据,最后解释性能,即偏差-方差分解。
偏差-方差分解对学习算法的期望泛化错误率进行拆解。算法在不同训练集上学得的结果很可能不同,即便这些训练集是来自同一分布。对测试样本x,令y D 为x在数据集中的标记,y为x的真实标记,f(x;D)为训练集D上学得模型f在x上的预测输出。以为回归任务为例,学习算法的期望预测为:

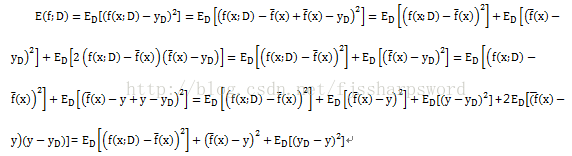
正好分解为:偏差、方差和噪声之和。
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同样大小的训练集的电动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声则表达了当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。偏差-分差分解说明,泛化性能是由算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务,为取得较好的泛化性能,需使偏差较小,即能否重复拟合数据,并使方差较小,即使数据扰动产生的影响小。
然而,偏差和方差是有冲突的,称为偏差-方差窘境(bias-variance dilemma)。给定学习任务并假定学习算法的训练程度,在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据所发生的扰动渐渐被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学到了,将发生过拟合。