文章目录
- 1 基于 VMware workstations 的CentOS7安装
- 2 Linux系统配置
- 3 hadoop 配置部署
- 3.1 解压Hadoop安装包
- 3.2 修改配置文件
- 3.2.1 hadoop-env.sh
- 3.2.2 yarn-env.sh
- 3.2.3 core-site.xml
- 3.2.4 hdfs-site.xml
- 3.2.5 yarn-site.xml
- 3.2.6 marpred-site.xml
- 3.2.7 slaves文件
- 3.3 复制主从点
- 4 启动Hadoop集群
| OS | Hadoop版本 | 节点个数 |
|---|---|---|
| CentOS7 | Hadoop-2.7.7 | 2(master,slave) |
1 基于 VMware workstations 的CentOS7安装
1.1 安装虚拟机
1.打开VMware,文件->新建虚拟机,出现如下界面,
选择“自定义(高级)”选项,下一步
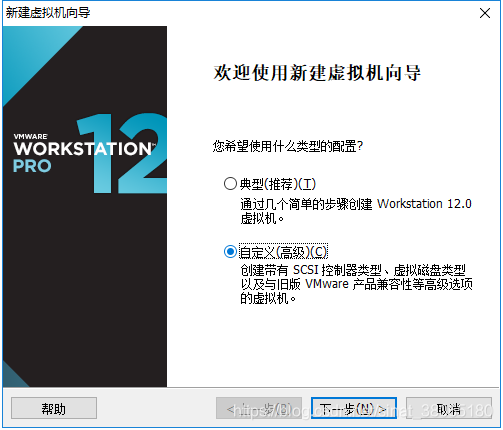
2.此步骤默认,下一步继续:

3.在出现下面界面,选中“稍后安装操作系统”选项,下一步继续:

4.在出现如下界面,客户机操作系统选择“Linux”,版本选择“CentOS 64位”,下一步继续:
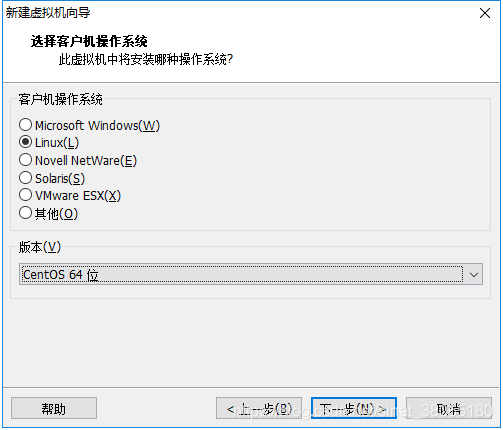
5.出现如下界面,输入自定义虚拟机名称,这里是“node1”,指定虚拟机位置,这里是“E:\VirtualMachines\CentOS 64位\node1“,然后下一步继续:
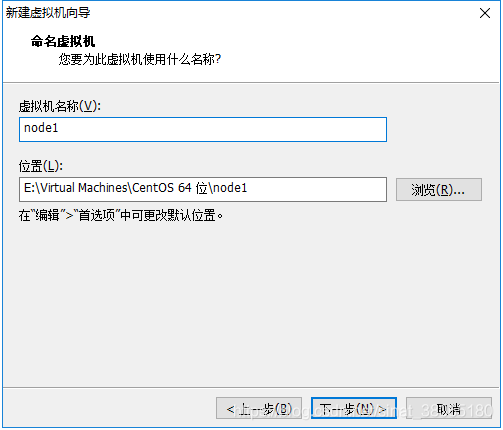
6.出现下面界面,选择处理器数量和每个处理器核心数量,这里分别是2和2,下一步继续:
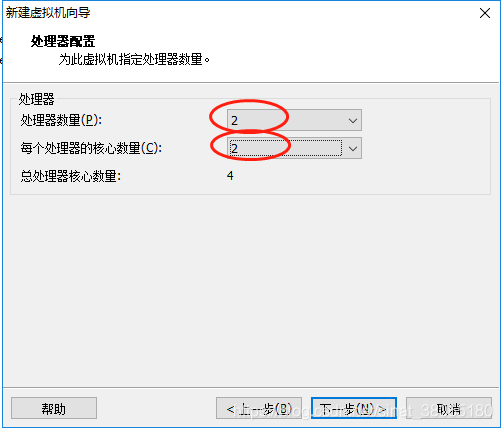
7.出现如下界面,指定虚拟机占用内存大小,这里是2048M,下一步继续:

8.出现如下界面,选择网络连接类型,这里选择“使用NAT模式”,各位安装虚拟机过程根据需要自行选择,安装向导中已经针对各种模式进行了比较规范的说明,这里补充说明如下:
- 使用桥接网络:虚拟机ip与本机在同一网段,本机与虚拟机可以通过ip互通,本机联网状态下虚拟机即可联网,同时虚拟机与本网段内其他主机可以互通,这种模式常用于服务器环境架构中。
- 使用网络地址转换(NAT):虚拟机可以联网,与本机互通,与本机网段内其他主机不通。
- 使用仅主机模式网络:虚拟机不能联网,与本机互通,与本机网段内其他主机不通。下一步继续:
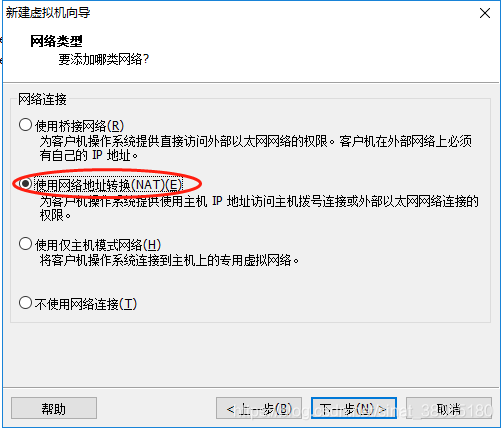
9.默认,下一步继续:

10.默认、下一步继续:
11.默认,下一步继续:

12.出现下面界面,输入虚拟机磁盘大小,这里设置虚拟机磁盘大小为30G,下一步继续:
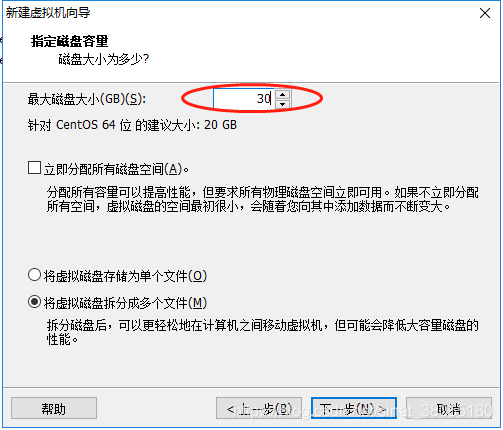
13.默认,下一步继续:
14.默认、点击“完成”结束虚拟机创建:

退出安装向导后,我们可以在虚拟机管理界面左侧栏看到刚刚创建的虚拟机,右侧栏可以看到虚拟机详细配置信息:
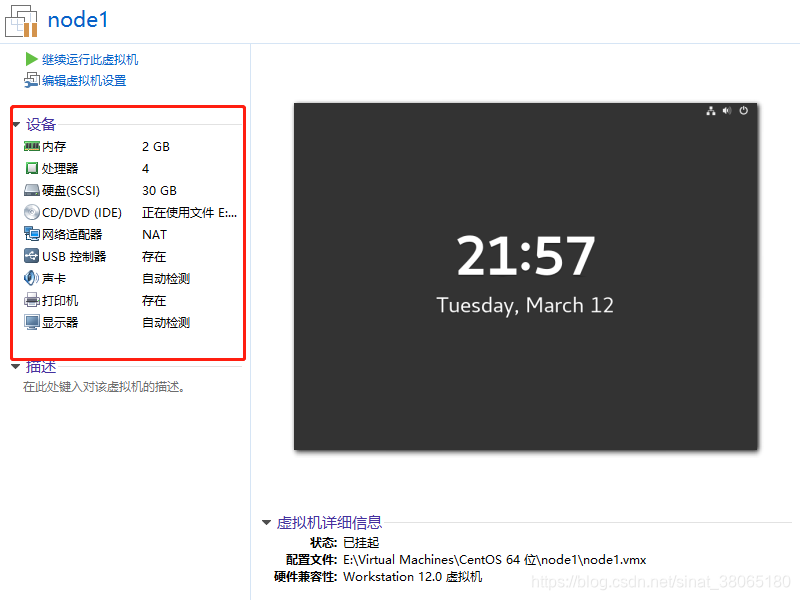
15.上图界面中点击“编辑虚拟机设置”选项,出现如下界面:

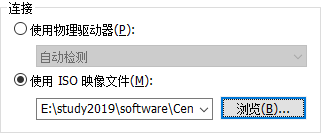
16.挂载光盘,然后点击确定,按照上述设置后界面如下图所示:
1.2 安装CentOS7操作系统
点击开启虚拟机进入CentOS7操作系统安装过程。
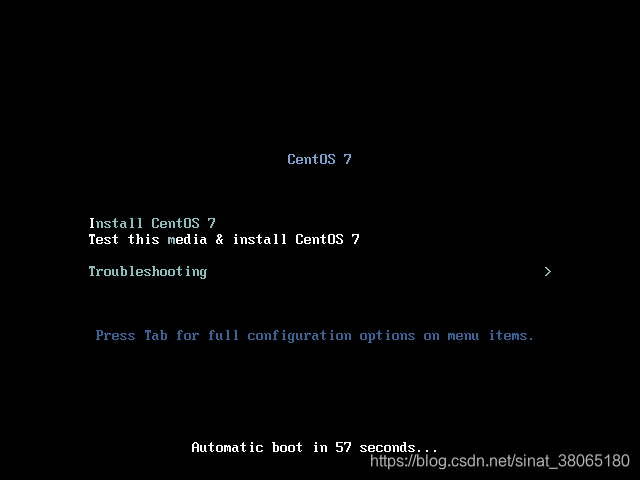
1.虚拟机控制台出现界面,选择Install CentOS Linux 7,点击回车键继续:
2.根据提示点击回车键继续:

3.如下界面默认选择English,点击Continue继续:

3.CentOS7安装配置主要界面如下图所示,根据界面展示,这里对以下3个部分配置进行说明:

Localization和software部分不需要进行任何设置,其中需要注意的是software selection选项,这里本次采用安装含图形界面安装,至于其他组件,待后期使用通过yum安装即可。

4.点击“Installation Destination”,进入如下界面,选中30g硬盘,点击左上角done进行磁盘分区规划:

5.点击“DATE&TIME”配置时间

6.完成磁盘规划后,点击network & host name选项中修改主机名(默认主机名为 localhost.localdomain),这里 node1修改为master,node2修改为slave,然后点击done完成主机名配置,返回主配置界面:
- master:

- slave

7.右下角“Begin Installation”按钮已经从原本的灰色变成蓝色,这说明已经可以进行操作系统安装工作了,点击“Begin Installation”进行操作系统安装过程。

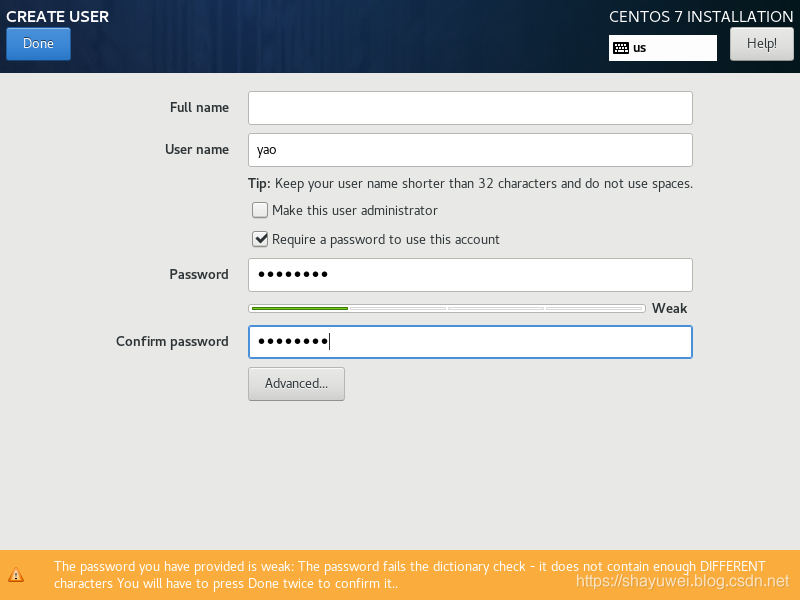
8.在用户设置中需要做的是修改root用户密码和创建普通用户。

点击“root password”,设置密码,如果密码安全度不高,比如我这里的密码为“rootroot”,那么可能需要点击2次确定才可以。

分别在node1和node2创建普通用户yao
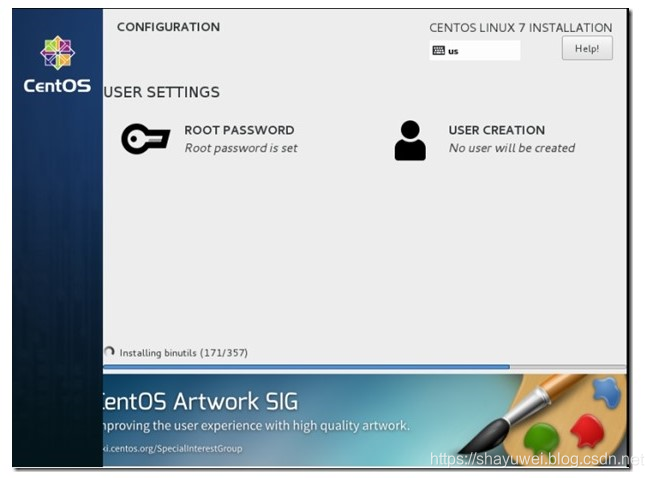
9.在下图,操作系统安装已经完成,点击reboot重启操作系统。

安装完成,通过普通用户yao登录:


2 Linux系统配置
2.1 上传安装包
1.将jdk-8u144-linux-x64.tar.gz分别上传到两台虚拟机的/soft目录下
sftp> pwd
/soft
sftp> put E:/study2019/software/jdk-8u144-linux-x64.tar.gz
master:

slave:

2.将hadoop-2.7.7.tar.gz上传到master:
sftp> put E:/study2019/software/hadoop-2.7.7.tar.gz
3.查看是否上传成功
master:

slave:
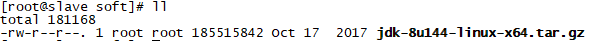
2.2 配置时钟同步
2.2.1 查看时间


2.2.2 时间不一致的解决办法
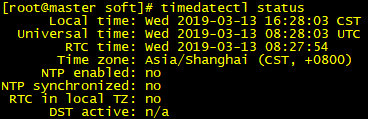
方法一:通过timedatectl命令修改

使用指南 timedatectl -h
查看当前系统时间 timedatectl status
设置当前时间
timedatectl set-time "YYYY-MM-DD HH:MM:SS"
timedatectl set-time "YYYY-MM-DD"
timedatectl set-time "HH:MM:SS"
查看所有可用的时区
timedatectl list-timezones
timedatectl list-timezones | grep -E "Asia/S.*"
设置时区
timedatectl set-timezone Asia/Shanghai
设置硬件时间
timedatectl set-local-rtc 1 // 默认UTC
启动自动同步时间
timedatectl set-ntp yes //yes或no,1或0
方法二:同步网络时间
1.同步mater
[root@master ~]# ntpdate time.nuri.net
13 Mar 17:32:29 ntpdate[26372]: adjust time server 211.115.194.21 offset -0.263924 sec
2.同步slave
[root@master ~]# ntpdate time.nuri.net
13 Mar 17:32:41 ntpdate[26372]: adjust time server 211.115.194.21 offset -0.263924 sec
2.3 配置主机名
2.3.1 命令设置主机名永久有效
[root@master ~]# hostnamectl set-hostname master
2.3.2 配置文件
[root@master ~]# vim /etc/hostname


2.4 关闭防火墙
2.4.1 关闭防火墙
[root@master ~]# systemctl stop firewalld.service
2.4.2 禁止firewall开机启动
[root@master ~]# systemctl disable firewalld.service
2.4.3 查看状态
[root@master ~]# systemctl status firewalld

2.5 配置网络
查看IP
| 虚拟机名称 | 主机名 | IP Address |
|---|---|---|
| node1 | master | 192.168.16.199 |
| node2 | slave | 192.168.16.200 |
master:

slave:
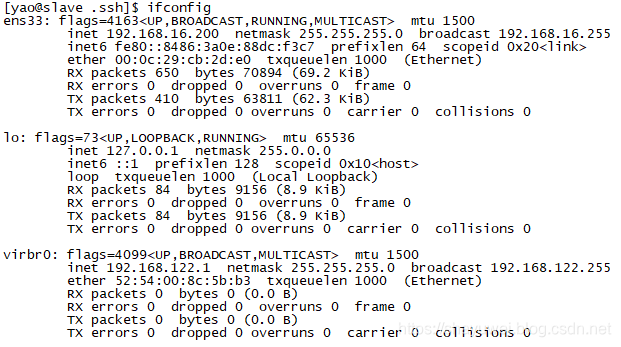
如果没有显示IP使用setup设置
[root@master ~]# setup
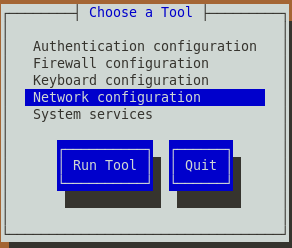
1.选择“Network configuration”,回车进入该项
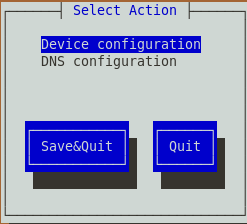
2.选择Device configuration
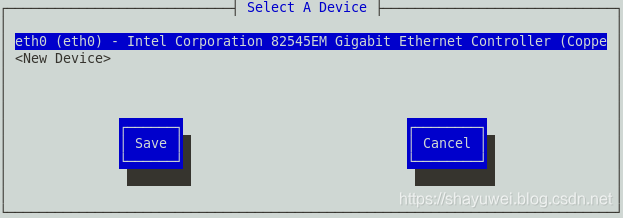
3.使用光标键移动选择eth0,回车进入该项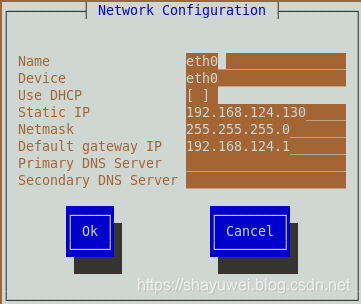
4.重启网络服务
[root@master ~]# service network restart
5.检查是否修改成功
[root@master ~]# ifconfig
2.6 配置hosts
注意,要同时在两个节点配置


2.7 安装jdk
在master上操作
2.7.1 新建目录
[root@master ~]# mkdir /usr/java/
2.7.2 解压安装包
将JDK文件解压,放到/usr/java目录下
[root@master java]# tar zxvf jdk-8u144-linux-x64.tar.gz

解压后:

2.7.3 配置环境变量
切换到普通用户
[root@master ~]# su yao
[yao@master root]$ cd ~
[yao@master ~]$ vi .bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
export JAVA_HOME=/usr/java/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
2.7.4 测试


注意,如果主机名是后更改的的,以上操作完成以后需要重启:
[root@slave java]# reboot
2.8 免密钥登陆配置
切换到普通用户下操作。
2.8.1 master节点
1.在终端生成密钥
[yao@master root]$ ssh-keygen -t rsa

2.复制公钥文件
[yao@master .ssh]$ cat ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
3.修改authorized_keys文件的权限
[yao@master .ssh]$ chmod 600 ~/.ssh/authorized_keys

4.将authorized_keys复制到slave节点
[yao@master .ssh]$ scp ~/.ssh/authorized_keys yao@slave:~/

2.8.2 slave节点
1.在终端生成密钥
[yao@slave root]$ ssh-keygen -t rsa
2.将authorized_keys文件移动到.ssh目录
[yao@slave ~]$ mv authorized_keys ~/.ssh/

2.8.3验证免密钥登录
在master机器上执行
[yao@master .ssh]$ ssh slave

3 hadoop 配置部署
Hadoop配置部署要在普通用户下操作:
3.1 解压Hadoop安装包
[yao@master ~]$ tar -xzvf hadoop-2.7.7.tar.gz

3.2 修改配置文件
3.2.1 hadoop-env.sh
[yao@master hadoop]$ vim hadoop-env.sh

3.2.2 yarn-env.sh
[yao@master hadoop]$ vim yarn-env.sh

3.2.3 core-site.xml
[yao@master hadoop]$ vim core-site.xml
修改内容:
<configuration>
<property> //修改项
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/yao/hadoopdata</value> //hadoop的数据存放目录
</property>
</configuration>
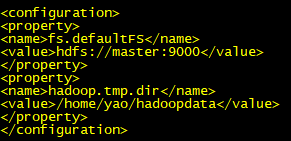
3.2.4 hdfs-site.xml
[yao@master hadoop]$ vim hdfs-site.xml
修改内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.2.5 yarn-site.xml
[yao@master hadoop]$ vim yarn-site.xml
修改内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>

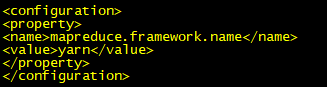
3.2.6 marpred-site.xml
[yao@master hadoop]$ cp mapred-site.xml.template mapred-site.xml
[yao@master hadoop]$ vim mapred-site.xml
修改内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.2.7 slaves文件
[yao@master hadoop]$ vi slaves

注意,因为此次搭建的是2个节点,如果要搭建3个或以上,这里就要把所有从节点的主机名写在里面,一行写一个
3.3 复制主从点
[yao@master hadoop]$ cd ~
[yao@master ~]$ scp -r hadoop-2.7.7 yao@slave:~/
4 启动Hadoop集群
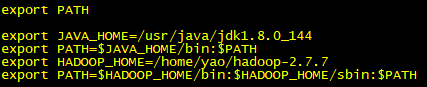
4.1 配置环境变量
[yao@master ~]$ vi .bash_profile
export HADOOP_HOME=/home/yao/Hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$ HADOOP_HOME/sbin:$PATH
[yao@master ~]$ source .bash_profile
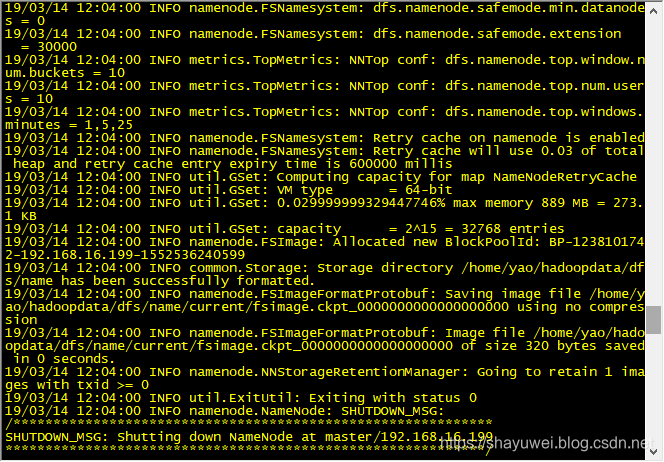
4.2 格式化文件系统
[yao@master ~]$ hdfs namenode –format

此处有一个报错,原因是配置文件core-site.xml中的一个路径出错了,更改后,需要手动将slave中的core-site.xml也一并修改为正确版。删掉/home/yao/hadoop-2.7.7/logs下的全部文件,因为格式化的过程中,它已经记录日志了。再删掉/home/yao/hadoopdata目录。重新格式化。
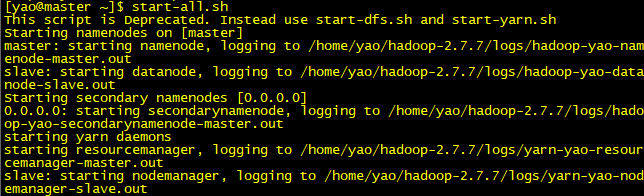
4.3 启动hadoop集群
[yao@master ~]$ start-all.sh
4.4 验证Hadoop集群是否成功
4.4.1 jps
jps的一个打印启动的进程的命令,可以用来测试Hadoop集群是否连接成功。
在master节点上有4个进程:
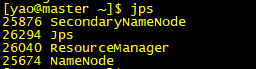
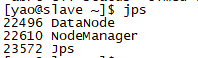
在slave节点上有3个进程:
4.4.2 通过web页面
1.在地址栏输入master:18088

2.在地址栏输入master:50070

4.4.3 Pi
这是hadoop自带的一个小例子,pi是一个参数,可以用来验证Hadoop集群是否成功。
[yao@master ~]$ hadoop jar hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 5 5
