第三章 统计语言模型
自然语言从它产生开始,正逐渐演变成一种上下文相关的信息表达和传递的方式,因此让计算机处理自然语言,一个基本的问题就是为自然语言这种上下文相关的特性建立数学模型。
1 用数学的方法描述语言规律普遍描述:假定S表示某一个有意义的句子,由一连串特定顺序排列的词w1,w2,…,wn组成,(这里应该是特征列表)这里n是句子的长度。现在,我们想知道S在文本中出现的可能性,也就是数学熵上所说的S的概率P(S)。

马尔可夫假设
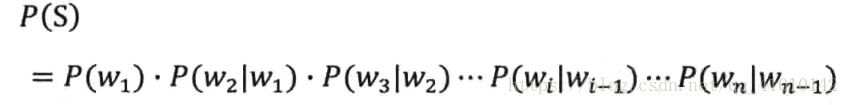
2 延伸阅读:统计语言模型的工程诀窍
当前词wi的概率值取决于前面N-1个词,

上面的假设被称为N-1阶马尔可夫假设,对应的语言模型称为N元模型。N=2就是前面的二元模型。N=1的一元模型实际上是一个上下文无关的模型,N=3在实际中应用最多。
N为什么一般取值都很小?这里主要有两个原因。首先,N元模型的大小(空间复杂度)几乎是N的指数函数,即0(丨V丨N),这里丨V丨是一种语言词典的词汇量,一般在几万到几十万个。②而使用N元模型的速度(时间复杂度)也几乎是一个指数函数,0(丨V丨N-1)。因此,N不能很大。当N从1到2,再从2到3,效果显著;从3到4,提升就不是很显著了,资源的耗费缺相反。