《知识图谱技术综述》整理
知识图谱基本概念
前言
本文内容整理自文献1。
“Web 1.0”时代:以文档互联为主要特征
“Web 2.0”时代:以数据互联为主要特征
“Web 3.0时代”:基于知识互联(尚未到来)
知识图谱的定义和架构
知识图谱的定义
本质上,知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。
知识图谱的架构
知识图谱的逻辑结构
知识图谱在逻辑上可分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。
知识图谱的体系架构
知识图谱主要有自顶向下(top-down)与自底向上(bottom-up)两种构建方式。
知识图谱的关键技术
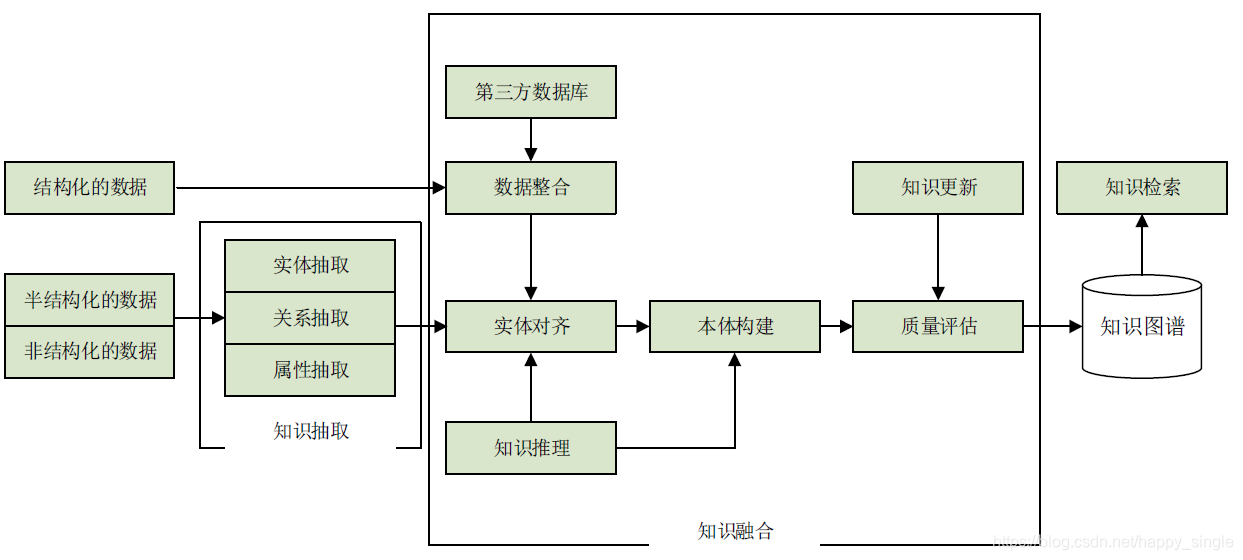
知识抽取技术:从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。
知识融合:消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。
知识推理:在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。
分布式的知识表示形成的综合向量:对知识库的构建、推理、融合以及应用均具有重要的意义。
先提一下知识存储
知识比数据的结构更加复杂,知识的存储需要综合考虑图的特点、复杂的知识结构存储、索引和查询(支持推理)的优化等问题、
典型的知识存储引擎分为基于关系数据库的存储和基于原生图的存储。
在实践中,多为混合存储结构,图存储并非必须。
知识抽取
知识抽取包括实体抽取、关系抽取和属性抽取三个部分。
实体抽取是指从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确率、召回率等将直接影响到知识库的质量。实体抽取的方法可以分为基于规则与词典的方法、基于统计机器学习的方法以及面向开放域的抽取方法。
关系抽取的目标是解决实体间语义链接的问题。关系抽取的方法:开放式实体关系抽取和基于联合推理的实体关系抽取。
属性抽取主要是针对实体而言的,通过属性可以形成对实体的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可以将实体属性的抽取问题转换为关系抽取问题。
知识表示
知识表示学习的代表模型主要包括距离模型、双线性模型、神经张量模型、矩阵分解模型、翻译模型等。
复杂关系模型指的是1-to-N、N-to-1、N-to-N的3种关系类型。1-to-1模型不属于复杂关系模型。
TransH模型尝试通过不同的形式表示不同关系中的实体结构,对于同一个实体而言,它在不同的关系下也扮演着不同的角色。
TransR模型首先将知识库中的每个三元组(h, r, t)的头实体与尾实体向关系空间中投影,然后希望满足
的关系,最后计算损失函数。
TransD模型分别定义了头实体与尾实体在关系空间上的投影矩阵。
TransG模型考虑到了关系r 的不同语义,使用高斯混合模型来描述知识库中每个三元组(h, r,t)的头实体与尾实体之间的关系,具有较高的实体区分度。
KG2E模型考虑了知识库中的实体以及关系的不确定性,同样是用高斯分布来刻画实体与关系,但它使用高斯分布的均值表示实体或关系在语义空间中的中心位置,协方差则表示实体或关系的不确定度。
知识融合
实体对齐也称为实体匹配或实体解析,主要是用于消除异构数据中实体冲突、指向不明等不一致性问题,可以从顶层创建一个大规模的统一知识库,从而帮助机器理解多源异质的数据,形成高质量的知识。
知识加工:可以得到一系列的基本事实表达或初步的本体雏形,然而事实并不等于知识,它只是知识的基本单位。要形成高质量的知识,还需要经过知识加工的过程,从层次上形成一个大规模的知识体系,统一对知识进行管理。知识加工主要包括本体构建与质量评估两方面的内容。
知识更新:根据知识图谱的逻辑结构,其更新主要包括模式层的更新与数据层的更新。
知识推理
知识推理在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。知识推理方法主要可分为基于逻辑的推理与基于图的推理两种类别。
还看到这样的分类,不是来自文献1的。

上图来自“小象学院”,侵删歉。