文章目录
关于知识图谱
知识图谱的概念
首先我们来明确知识的概念,知识对于人类来说很抽象,随便人脑中一条有用的信息就可以认为是知识,例如:中国的首都是北京,这便是知识。
在人类发明文字之前,知识都是通过语言世代相传。而当人类发明文字之后,壁画、陶器、书本都是知识传递和传播的载体。到了现在,知识可以存储在硬盘里,存储在数据库中。
但这些方式都存在着或多或少的问题,一是它们对于人类来说不直观,不能一目了然的展现知识的结构与含义,帮助人类快速理解知识;二是,这些知识的存储方式不便于计算机进行有效的使用,非结构化的数据使用低效。现有的知识存储方式很难完美的同时做到这两点。
于是知识图谱便应运而生,研究学者将哲学中本体概念引入到人工智能领域,并用本体来表示知识,使用语义网络作为翻译的中介语言。同时对语义网络中的边进行约束。它建立了客观事件事物的字符串描述到结构化语义描述的映射。
同时,使用资源描述框架(RDF)来规定知识图谱的基本结构,用基本的三元组来表示知识,例如<北京,是首都,中国>,(头实体,关系,尾实体)该三元组便结构化的表示了上面我举例的知识,并且,该三元组也很好画成形象的网络,让我们一目了然的明确,奥~,北京是中国的首都。
(也就是说,知识图谱中知识的基本单元是三元组,这是结构化的数据格式,同时,三元组能够表示图or网络中的节点和有向边,所以其能够轻松画成如下图所示的形象的网络,从而直观的展示出来)
总的来说,知识图谱将我们脑海中抽象的知识给结构化、形象化的存储与展示出来,我更愿意把它理解成一个具有丰富结构信息、语义信息、与属性信息的数据库。它本身并不能够做什么,它只是数据的存储、结构化、与形象化展示的工具,它能够做什么最终还是取决于我们如何理解与使用它。(个人拙见,非官方理解)
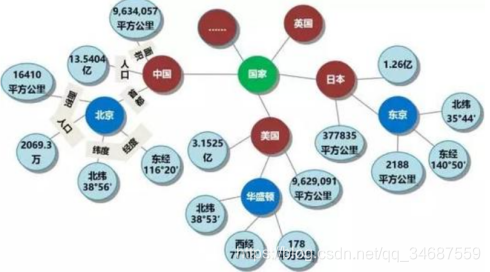
知识图谱与异质网络
可能有些读者分不清楚异质网络与知识图谱的区别。我之前也是纠结过一段时间,后来经过和老师沟通,并读了石川的异质信息网络分析与应用综述一文,弄清的二者的区别。
一般来说,知识图谱和异质网络可以认作是一个东西,在石川的文章中,石川将知识图谱定义为丰富模式的异质网络,即其网络模式过于复杂过于丰富。
而从复杂网络的角度来说,知识图谱和异质网络是有着区别的。
- 复杂网络中的异质网络更加关注于结构信息
- 知识图谱更加关注语义知识
从拓扑结构来说,知识图谱可以被视为异质网络。
本质上,知识图谱就属于异质网络的范畴。
所以我们在理解知识图谱的时候,可以用网络的概念去理解。
不过其中有些名词与定义不太一样,比如本体和网络模式(此处个人拙见,非官方)是一样的,但是叫法不一样。
知识图谱与知识库
在许多知识图谱的文章中,认为知识图谱是一个经过清洗的知识库,知识库由本体约束下的实例组成。那么就可以认为 知识图谱=本体+知识库。
知识图谱构建研究背景
目前的开源知识图谱还是不少的,国内外都有,例如Metaweb公司开发的freebase,维基媒体基金会开发的wikidata微软开发的concept graph,谷歌开发的knowledge graph,普林斯顿大学的wordnet,马克斯普朗克研究所的yago,国内知识图谱项目有openKG,百度的知识图谱项目。
其中的freebase是一个常识性的知识图谱,而wordnet是个词语知识图谱。这两个是我平时进行异质网络分析所经常使用的,当然,这里的每个知识图谱都很大,我一般都使用FB-15K或者WN-18,它们是上述两个知识图谱的子集,规模要小很多,便于处理。
在知识图谱研究的早期,知识图谱的构建主要依托于领域专家,那时是以专家为主的知识图谱阶段,知识来源都来自于领域专家,这种构建方式准确性很高,但是缺点也显然,效率低下,成本高,且知识数量实在有限。
而如今,知识图谱的构建已经过度到了机器学习方法自动获取知识的自动化阶段。可以由专家定义好实体的类别,来从海量的数据中获取实体,以及实体之间的关系(知识)。其能够适应数据和知识爆炸性增长的现状。
知识图谱的数据源现在多来自关系数据库、维基百科、基于语义网页标准的网页。
知识图谱构建
知识图谱的构建流程
关于知识图谱的构建,主要根据其类别方向有所不同。
通用知识图谱的话一般采用自底向上的构建方法,即利用一定的技术手段取得可能为目标实体或关系的内容,通过专家审核鉴定其置信度是否达标后,加入知识图谱中。
领域知识图谱的构建通常先指定一个范围和目标,即预定义好实体的类别属性和关系的类别集合,将数据遵照定义好的类别提取出其中包含的数据加入知识库。
知识图谱本体构建
不去过多的讨论本体的概念,构建本体的目的是为知识图谱构建一个骨架,它是知识图谱构建的基础,它能够指导知识图谱的构建。
在我看来,知识图谱的本体和异质网络的网络模式就是一个东西,都是指导知识图谱和异质网络构成的规则,或者说是准则。
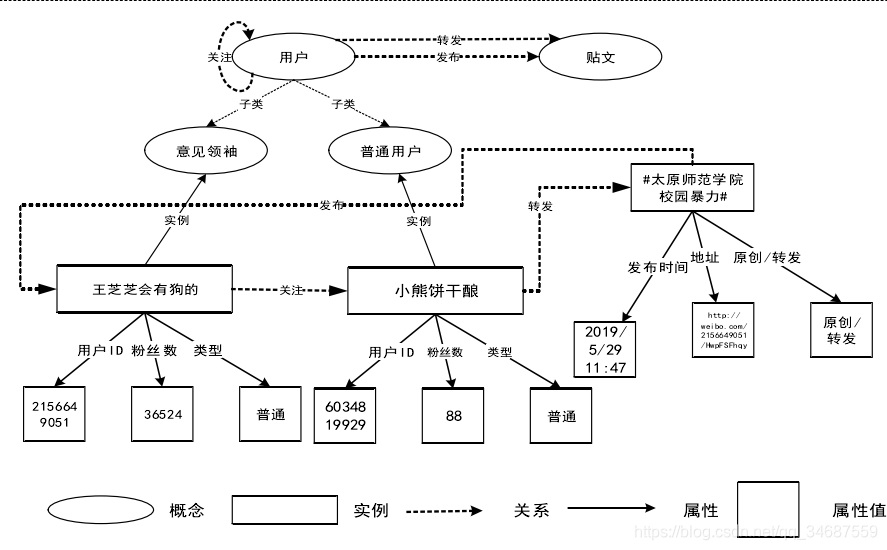
例如上图的最上面便是本体,下面是本体下的具体实例。
知识图谱构建核心步骤
上面我们也介绍了知识图谱大概的概念,其是基于RDF协议框架的,数据单元是三元组<头实体,关系,尾实体>,例如下图是我从WN-18数据集中截图出来的。

我们要构建知识图谱,就是可以视作构建这些三元组。也就是三元组中的实体与关系。
(上面我们提到了知识图谱本质上就是异质网络,所以我们可以认为实体就是网络中的节点,而关系就是边)
于是,我们确定了实体和关系就是知识图谱中最基础的元素。
则我们的主要目标转变成从海量数据中提取实体与关系。
针对这俩个目标,有对应的技术或者说是步骤:命名实体识别与关系抽取。在知识图谱构建流程中,命名实体识别是为了抽取实体和实体属性,而关系抽取是为了得到实体间预定义好的关系。
命名实体识别的目的简单来说就是识别实体,具体来说,是对预先给定的目标命名实体实体的定义和类别,鉴别出这些目标实体在文本中的具体位置,并进行类别判定。
命名实体识别是偏向于nlp的概念。一般来说命名实体识别的研究主体分为实体类、时间类与数字类,其还可以往下细分。主要方法:
- 有基于规则和字典的实体识别方法:手工定义规则,根据语言特征加以指定,怨言特征包括句子的句法信息,单词的词性、大小写、前后缀等。此外还会考虑利用已经构建好的相关词典。
- 基于机器学习得到实体识别方法。
- 基于深度学习的实体识别方法。
关系抽取目的简单来说就是抽取关系,具体来说是根据给出的自然语言文本和文本中出现的实体,利用句子的语义信息推测出两个实体之间是否存在关系并对关系进行分类。
举个例子:给定一个句子,天安门坐落于北京,以及实体天安门和北京,此时根据语义得到 位于 的关系。
主要方法:
- 基于规则模板的关系提取方法
- 基于统计学习的关系抽取方法
- 基于深度学习的关系抽取方法
实体消岐
实体消岐:命名实体的歧义指的是一个实体指称项可对应到多个真实世界实体确定一个实体指称项所指向的真实世界实体。
出现场景:多个数据源中提取的关系融合中,会遇到一些歧义的实体,需要对歧义的实体概念、实例进行消岐。
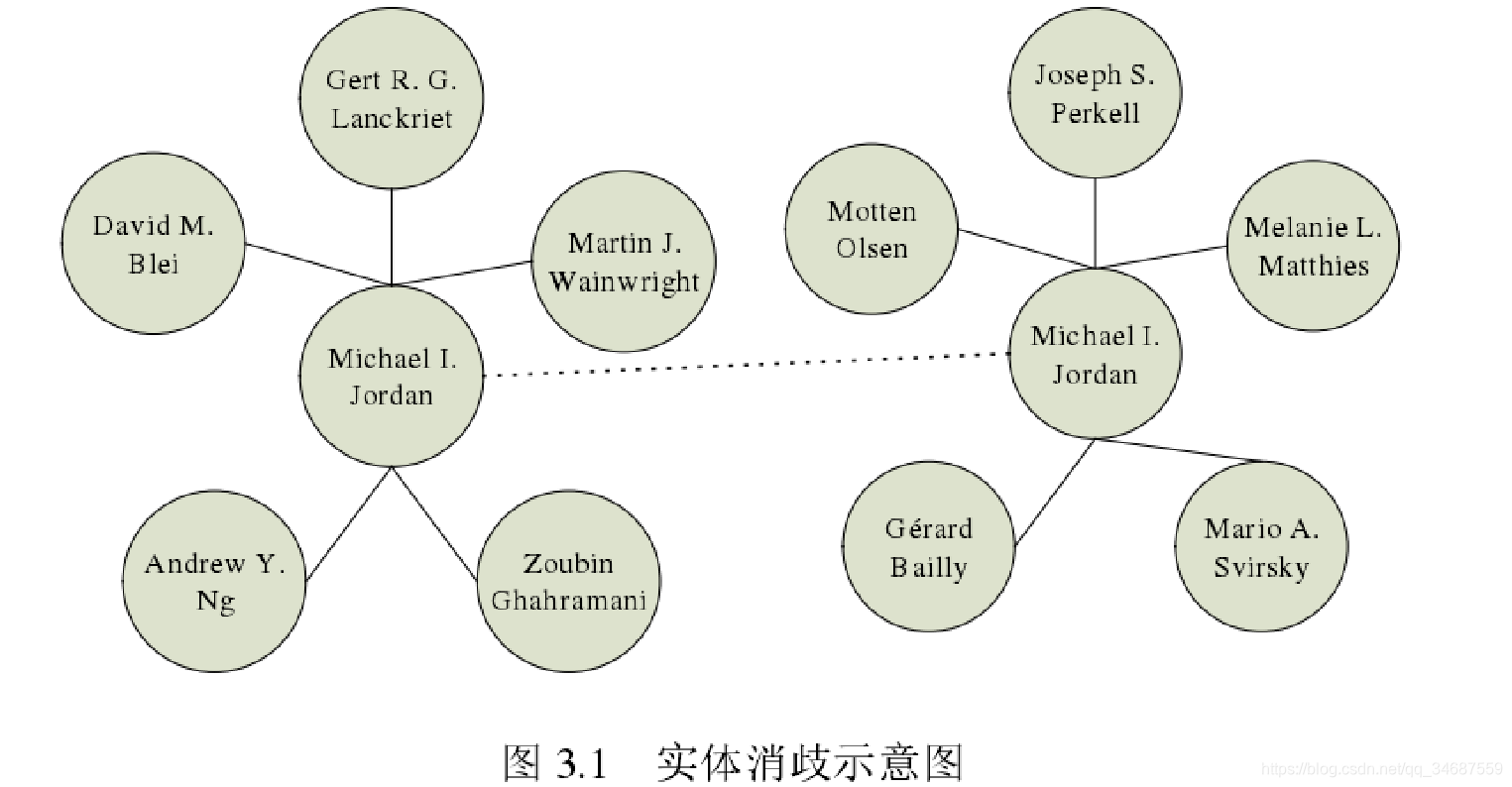
如图所示,同样一个jordan(名字),在不同的数据源中是不一样的人,左边是人工智能专家的论文合作图谱,而右边是声学研究专家的论文合作图谱。在从多个数据源中提取知识时,我们不能因为两个jordan名字一样,就认为他们是一个人,就把两者的信息融合在一起,这明显是错误的。
知识图谱构建中会出现重名实体的情况,需要进行消岐。现有的消岐方法仅适用于文本中的实体消岐或小型知识库的实体消岐,需要大量的领域专家知识,人力成本很高,需要设计自动的面向大规模的知识图谱的实体消岐方法。
现有解决方法:实体转换成语义实体嵌入向量,使用基于图的方法,根据实体嵌入向量相似度将文档中的实体连接到知识库实体上。
知识图谱关系补全
由于我们的数据不可能是绝对完整的,总会有些信息缺失,也就是知识缺失。
此时需要根据现有的知识来挖掘出实体之间存在的潜在关系。
知识补全也称作链接预测。
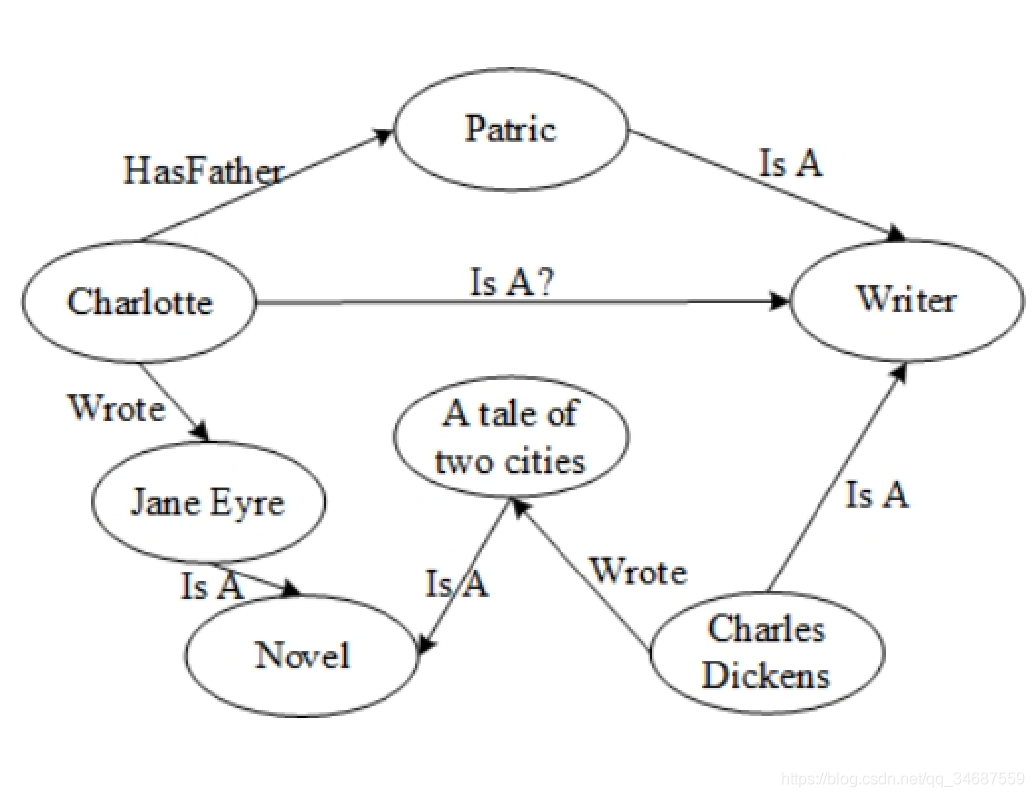
如图所示,根据现有的知识,我们可以推测出Charlotte是一个作家。
关于现有的知识补全的方法,张量分解方法,语义嵌入方法,基于路径。
其中我接触过的,也是十分经典的方法就是Trans家族了,我接触了其中最基础的TransE,这在我的博客中也有写过,有兴趣可以去读一下。TransE入口
知识图谱关系推理
知识推理是通过关系推理的方法来获得实体间的新知识。
根据已知的实体之间关系推测实体之间的潜在关系给知识图谱增加新的事实。
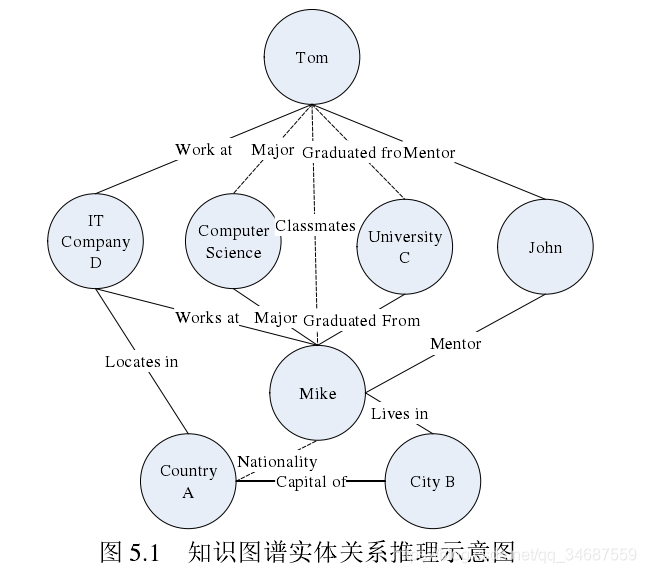
如图所示,我们可以根据Tom和Mike是同一个公司,同一个导师,来判断出虚线部分的 他们是同学。
这属于统计关系学习的子领域,其方法包括基于马尔科夫逻辑网络的推理、基于归纳逻辑变成的推理
总的来说知识图谱的关系补全与知识图谱的关系推理,都算是知识补全或者知识推理的范畴。
知识冲突解决
随着时间,知识图谱不断演化,之前知识图谱中的某些事实是错误的。或者因为知识具有时效性,所以知识随时间变化,有时候会错误,甚至产生冲突,所以需要解决知识冲突问题。
关于这一块,我不是太了解,所以不过多阐述了。
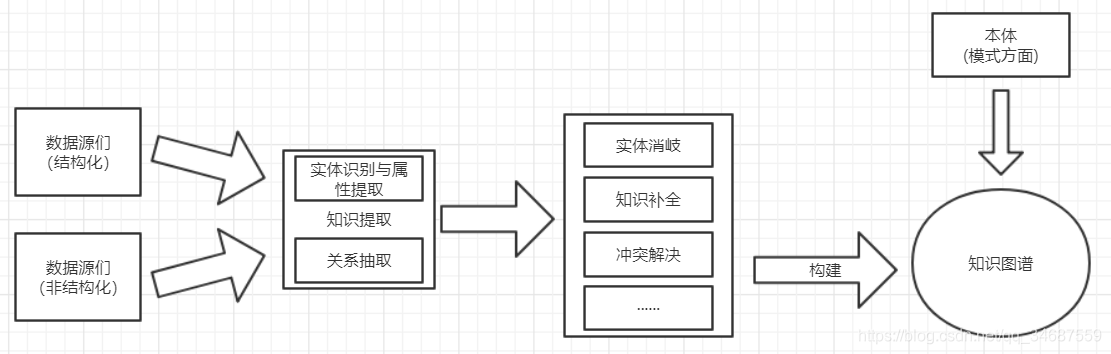
知识图谱构建总流程
参考文献
马江涛. 基于社交网络的知识图谱构建技术研究[D].战略支援部队信息工程大学,2018.
许多. 社交网络中的情感知识图谱构建关键技术研究[D].上海师范大学,2020.
王瑞. 网络舆情事件知识图谱构建技术及应用研究[D].华侨大学,2020.
Ji S, Pan S, Cambria E, et al. A survey on knowledge graphs: Representation, acquisition and applications[J]. arXiv preprint arXiv:2002.00388, 2020.