版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011195398/article/details/87361854
前言
上一篇文章《从0开始学大数据(2):hadoop安装》我们对hadoop工具进行了安装,这章我们对hadoop的官网案例进行讲解,让我们对hadoop进行初步入门。
Hadoop运行模式
Hadoop运行模式
- 本地模式(默认模式):不需要启用单独进程,直接可以运行,测试和开发使用
- 伪分布模式:等同于完全分布式,只有一个节点。
- 完全分布模式:多个节点一起运行
1.本地文件运行Hadoop案例
1.1 官方grep案例
- 拷贝hadoop的etc/hadoop下的xml文件到input目录下
[martin@hadoop101 hadoop-2.7.2]$ sudo cp etc/hadoop/*.xml input
- 执行share目录下的mapreduce程序
sudo bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
- 查看输入结果
将用例集合中的已dfs开头的文件过滤,从输入文件input到输出到output文件夹中,其中output文件夹不能创建。

我们通过观察part-r-00000文件,就找到了里面的结果集显示配置文件中的以dfs开头的文件dfsadmin。
1.2 官方wordcount案例
这次我就将步骤和命令分开,这样比较容易分析:
- 创建在hadoop-2.7.2文件下创建一个wcinput文件夹
- 在wcinput文件下创建一个wc.input文件
- 编辑wc.input文件
- 回到hadoop目录/opt/module/hadoop-2.7.2
- 执行程序
- 查看结果
[martin@hadoop101 hadoop-2.7.2]$ mkdir wcinput
[martin@hadoop101 hadoop-2.7.2]$ cd wcinput/
[martin@hadoop101 wcinput]$ ls
[martin@hadoop101 wcinput]$ touch wc.input
[martin@hadoop101 wcinput]$ vim wc.input
[martin@hadoop101 wcinput]$ cd ..
[martin@hadoop101 hadoop-2.7.2]$ ls
LICENSE.txt NOTICE.txt README.txt bin etc include input lib libexec output sbin share wcinput
[martin@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcoutput
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcoutput
[martin@hadoop101 hadoop-2.7.2]$ cd wcoutput/
[martin@hadoop101 wcoutput]$ ls
_SUCCESS part-r-00000
[martin@hadoop101 wcoutput]$ cat part-r-00000
date 1
david 1
franky 1
hadoop 1
jacky 1
java 1
jimmy 1
kafka 1
martin 1
sarah 1
whisly 1
2.伪分布式运行Hadoop案例
2.1 HDFS上运行MapReduce程
配置集群
- 1.修改
/hadoop-2.7.2/etc/hadoop/core-site.xml文件,如果是在Mac下我推荐在Sublime Text3 安装sftp的插件,我们将下面的内容复制到xml文件中。
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
</configuration>
在官网的core-default.xml中fs.defaultFS默认是本地文件,这里是将本地文件修改为我们制定的节点。
- 2.修改
hdfs-default.xml配置文件
数据需要备份,我们需要配置数据配置在地方,同样,我们可以在官网查看一下默认值。
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
集群中增加了节点,我们可以对数据再次进行备份。
启动集群
- 格式化namenode(第一次启动时格式化,以后就不要总格式化)
hdfs namenode -format
- 启动namenode
sbin/hadoop-daemon.sh start namenode
- 启动datanode
sbin/hadoop-daemon.sh start datanode
查看集群
- 查看是否启动成功
jps:查看java进程
[martin@hadoop101 sbin]$ jps
24519 Jps
24428 DataNode
23832 NameNode
- 查看产生的log日志
[martin@hadoop101 hadoop-2.7.2]$ cd logs
[martin@hadoop101 logs]$ ll
total 60
-rw-rw-r--. 1 martin martin 0 Feb 15 17:17 SecurityAuth-martin.audit
-rw-rw-r--. 1 martin martin 23678 Feb 15 17:20 hadoop-martin-datanode-hadoop101.log
-rw-rw-r--. 1 martin martin 716 Feb 15 17:20 hadoop-martin-datanode-hadoop101.out
-rw-rw-r--. 1 martin martin 27470 Feb 15 17:20 hadoop-martin-namenode-hadoop101.log
-rw-rw-r--. 1 martin martin 716 Feb 15 17:17 hadoop-martin-namenode-hadoop101.out
[martin@hadoop101 logs]$ cat hadoop-martin-namenode-hadoop101.log
- Web端查看HDFS文件系统
我们在宿主机浏览器中输入10.211.55.101:50070/就可以查看我们的HDFS了,提示一下有些原因不能访问,是虚拟机的防火墙没有关闭可以查看这篇文章《CentOS7查看和关闭防火墙》使用命令将防火墙关闭即可访问。
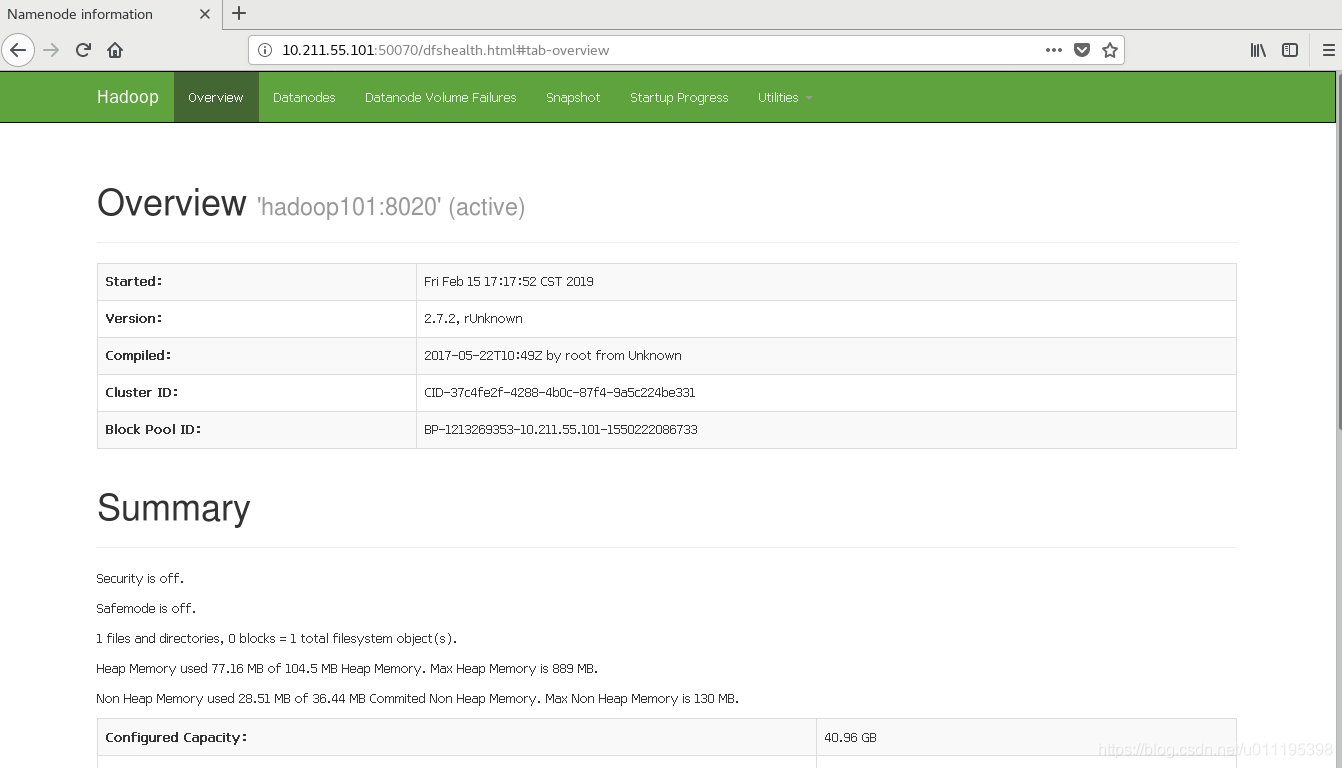
操作集群
- 创建目录
在HDFS文件系统中,根目录与Linux一样都是用\表示。
hadoop fs -mkdir -p /user/martin/input
PS:mkdir -p :表示创建多级目录
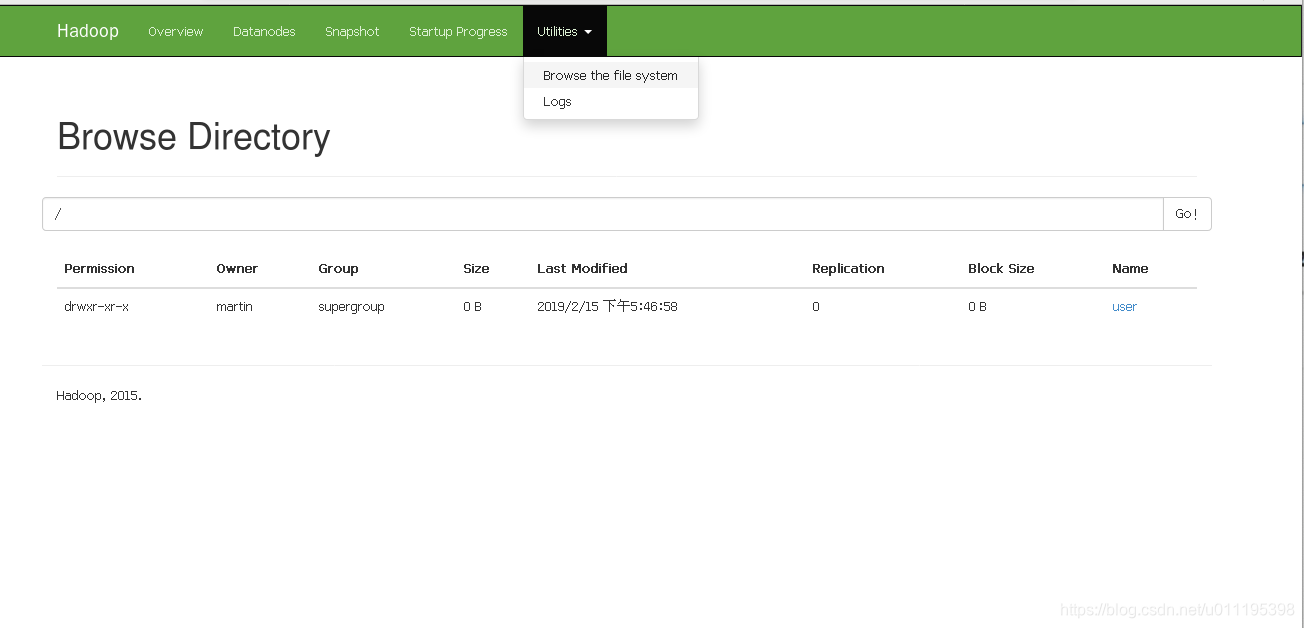
- 向文件夹中上传文件
hadoop fs -put wcinput/wc.input /user/martin/input

- 在HDFS上运行Mapreduce程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/martin/input/ /user/martin/output
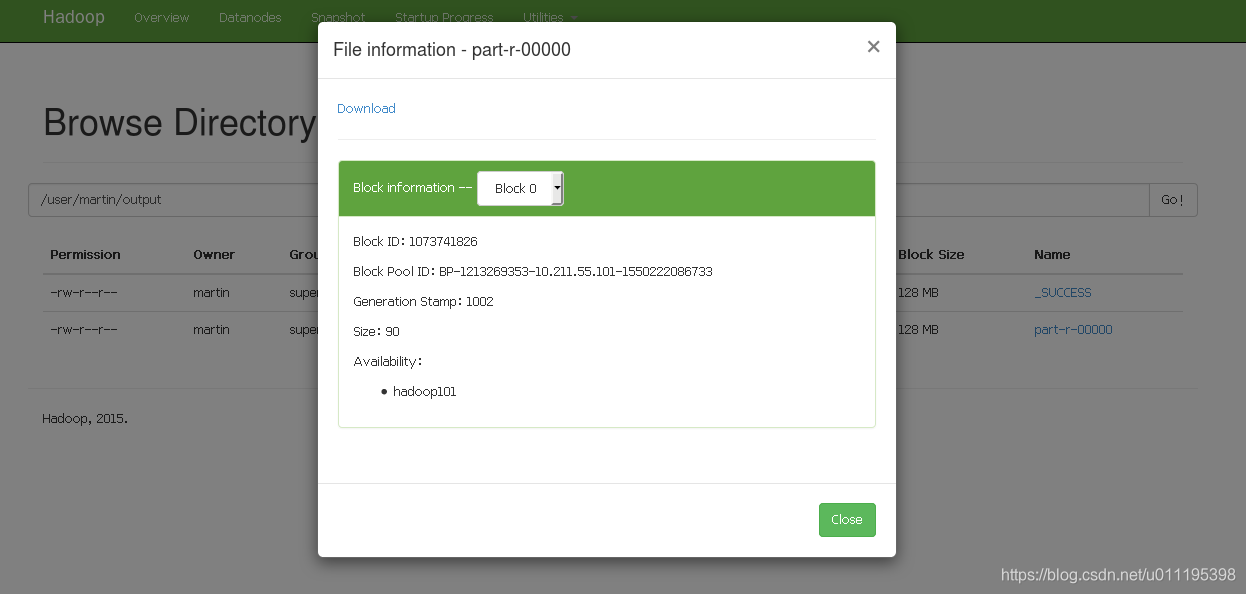
下载文件结果后即可查看。
- 删除输出结果
hadoop fs -rmr /user/martin/output
2.2 HDFS上运行MapReduce程序
配置集群
- 修改yarn-env.sh配置文件的Java_Home
$vi /opt/module/hadoop-2.7.2/etc/hadoop/yarn-env.sh

- 修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer the way of getting data -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManager address is sepecified on YARN -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
</configuration>
yarn.nodemanager.aux-services:是获取数据的方式
yarn.resourcemanager.hostname:资源管理所在的主机名称
- 修改
mapred-env.sh配置文件的Java_Home
$vi /opt/module/hadoop-2.7.2/etc/hadoop/mapred-env.sh

- 修改
mapred-site.xml配置文件
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
启动集群
- namenode:目录节点
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh start namenode
- datanode:数据节点
sbin/hadoop-daemon.sh stop datanode
sbin/hadoop-daemon.sh start datanode
- resourcemanager:资源管理器
sbin/yarn-daemon.sh start resourcemanager
- nodemanager:节点管理器
sbin/yarn-daemon.sh start nodemanager
- 查看结果
[martin@hadoop101 hadoop-2.7.2]$ jps
23733 ResourceManager
22940 NodeManager
20853 NameNode
23773 Jps
20982 DataNode
集群操作
- yarn的浏览器页面查看,输入网址
http://10.211.55.101:8088/cluster
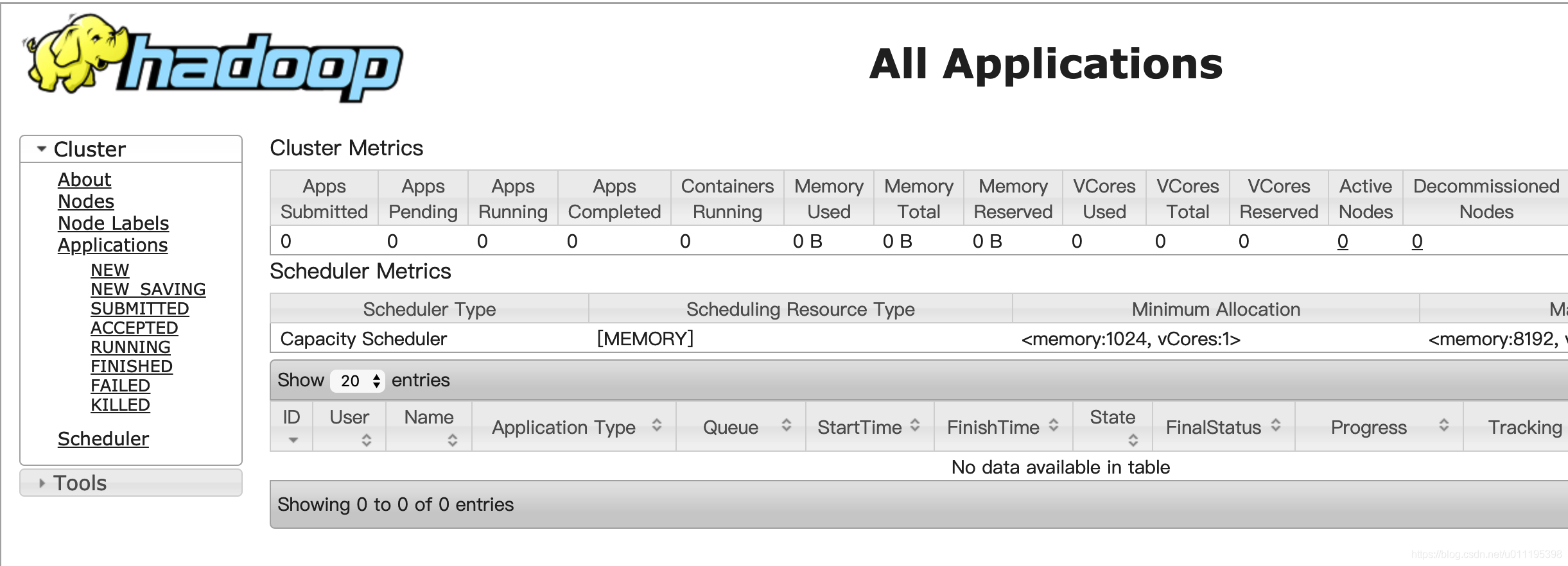
上图主要是查看MapReduce应用程序运行过程。 - 执行MapReduce应用程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/martin/input /user/martin/output
可以看结果就是,先Map完成后才会执行Reduce操作。
2.3 修改本地临时存储目录
默认情况下,在执行结果的时候会产生一些临时文件保存到/tmp

上面运行结果中的临时文件命名:hadoop-[当前用户],现在我们需要对这个临时目录修改到我们的制定的目录下。
- 创建临时目录
mkdir -p data/tmp
- 添加下面配置到core-site.xml
vi etc/hadoop/core-site.xml
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
修改好配置以后,读取配置文件是在服务启动的时候才会产生,所以,我们需要重启服务。
- 停止所有服务
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager
sbin/hadoop-daemon.sh stop datanode
sbin/hadoop-daemon.sh stop namenode
- 删除临时文件
rm -rf /tmp/hadoop-martin/
- 删除logs
rm -rf logs/
- 格式化namenode
bin/hdfs namenode -format
- 开启所有的服务。
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start namenode
- 查看所有服务
[martin@hadoop101 hadoop-2.7.2]$ jps
16678 ResourceManager
16263 NameNode
17024 Jps
16491 DataNode
16958 NodeManager
- 查看修改后临时文件夹

看见红框后代表修改成功。
小结
这篇文章我们学习到了Hadoop的运行模式:
- 本地模式
- 伪分布模式
- 完全分布模式
通过配置前两种模式,我们使用官网的wordcount案例对我们的单词数据进行了分析让我们对hadoop进行了入门学习,由于篇幅原因下篇我在讲解完全分布式部署。