前言
上一篇文章《从0开始学大数据(1):Parallels Desktop下CentOS系统的安装和静态IP地址配置》前面使用虚拟机安装了centos系统和配置虚拟机的IP静态地址。今天这章内容主要是对大数据的知识体系有个了解并且对Hadoop的运行环境的搭建。
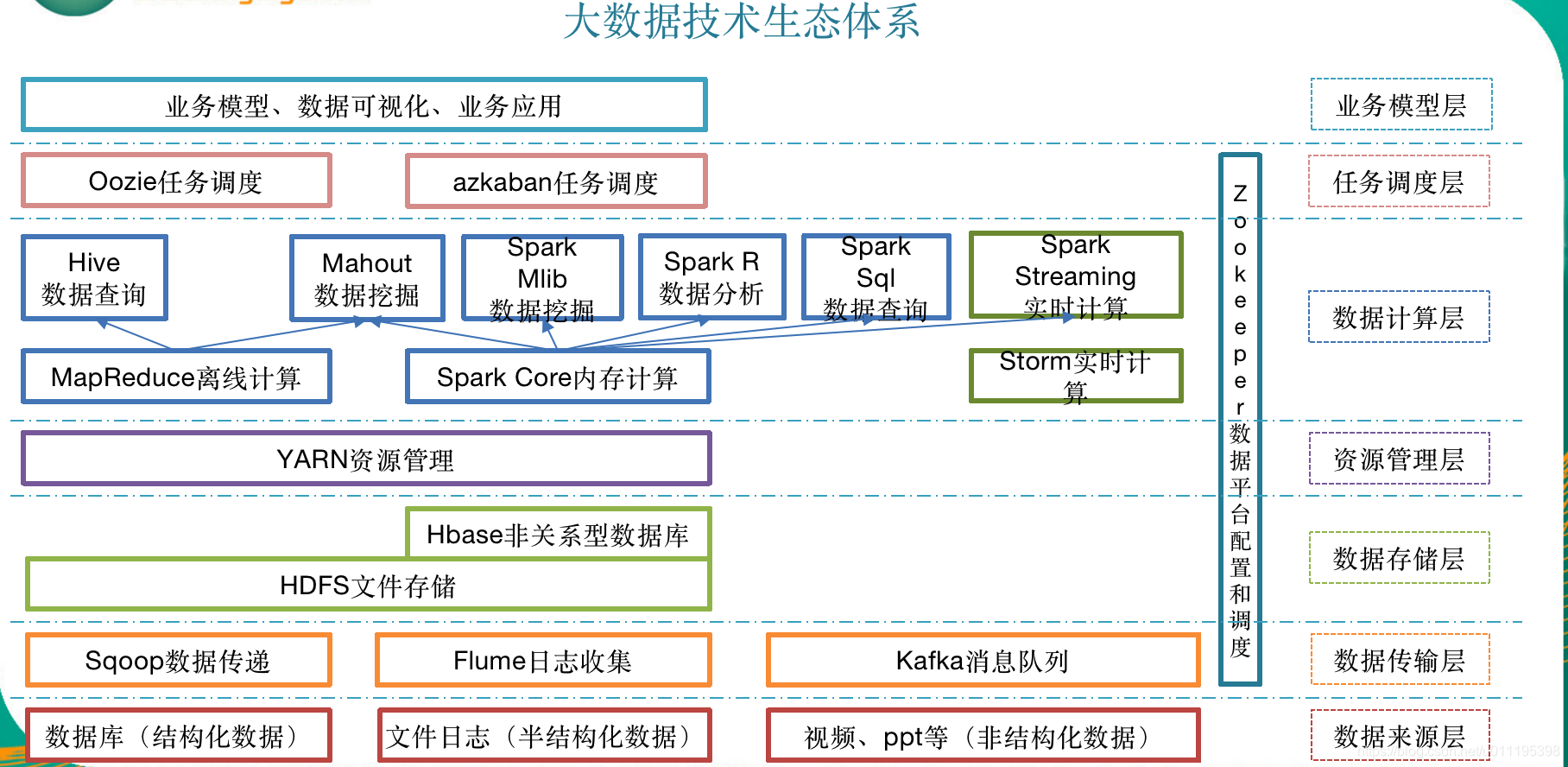
- 大数据生态体系
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
- 推荐系统框架图
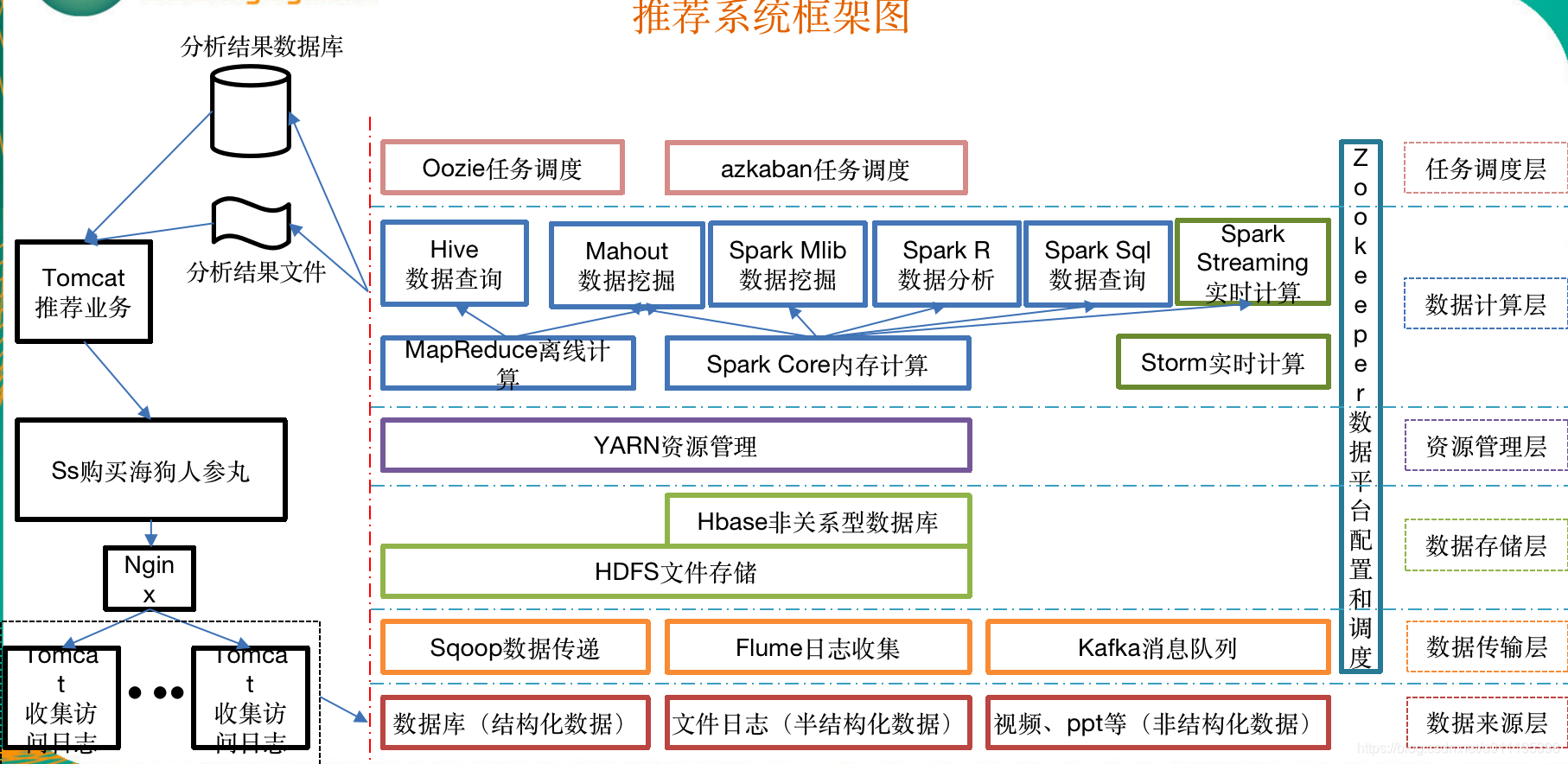
通过上面的两张PPT,我们应该能看懂大数据的作用就是讲用户的行为对某个特定商品的行为习惯变为数据参数整合后通过IT的技术手段在海量数据中找到有价值导向的数据结果推送给用户,我们的目的就是学习其中的IT技术工具,下面我们先从Hadoop来说起。
Hadoop
Hadoop的组成

通过上面的思维导图,我们可以清晰的看见Hadoop的组成。可能其中的技术细节现在还无法看懂,不过我们再心里面有一个框架,以便于我们后期的学习有一个方向。下面开始讲解我们今天的主要目的运行环境的搭建。
Hadoop的运行环境搭建
这节来说下Hadoop的运行环境的搭建,下面我列出一些官网地址信息,这篇文章主要来源于官网信息的教程。
- 官网网址: http://hadoop.apache.org/
- 各个版本的归档库:https://archive.apache.org/dist/hadoop/common/
- Hadoop2.7.2版本详情介绍:https://hadoop.apache.org/docs/r2.7.2/
创建文件夹
-
更改用户权限
一般情况下,在一些特定的目录中需要一些权限来创建文件夹,但是频繁的去切换到root用户比较麻烦,通过修改/etc/sudoers文件来做到当前用户也能获取权限的目的。

我们只需要见root的命令操作权限复制一些编写为我们的martin用户即可,更多细节可以参考这篇文章。查看文章后如果出现error : sudo /etc/sudoer is world writable的bug,可是使用命令#pkexec chmod 0440 /etc/sudoers解决。 -
配置文件拥有者
sudo chown martin:martin module/ software/
安装JDK
- 卸载现有jdk
[martin@hadoop101 opt]$ rpm -qa |grep java
tzdata-java-2018e-3.el7.noarch
java-1.7.0-openjdk-1.7.0.191-2.6.15.4.el7_5.x86_64
javapackages-tools-3.4.1-11.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.191-2.6.15.4.el7_5.x86_64
java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
上面可以查看到centos7默认安装了openjdk1.7.0和openjdk1.8.0下面我们通过yum 命令进行卸载。
[root@hadoop101 opt]# yum -y remove java-1.7.0-openjdk-headless.x86_64
[root@hadoop101 opt]# yum -y remove java-1.7.0-openjdk-1.7.0.191-2.6.15.4.el7_5.x86_64
[root@hadoop101 opt]# yum -y remove java-1.8.0-openjdk-headless-1.8.0.181-3.b13.el7_5.x86_64
[root@hadoop101 opt]# yum -y remove java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
- 用filezilla工具将
jdk、Hadoop 2.7.2.tar.gz导入到opt目录下的software文件夹。
工具链接:https://pan.baidu.com/s/1vYjJSrEEkraYxxAWv6PtLg 密码:bay7
- 解压JDK到/opt/module目录下
[root@hadoop101 software]# tar -zxvf jdk-7u79-linux-x64.gz -C /opt/module
[root@hadoop101 jdk1.7.0_79]# vi /etc/profile
- 配置环境变量
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
export关键字是声明全局变量,这句话就是讲JAVA_HOME声明为全局变量。
PATH是系统变量,我们需要先将PATH变量的值提取出来,然后后面追加内容就用:代替,最后将JAVA_HOME变量重新赋值给PATH变量。
- 启用
[root@hadoop101 jdk1.7.0_79]# source /etc/profile
- 检查
[root@hadoop101 jdk1.7.0_79] java -version
安装Hadoop
- 进入到Hadoop安装路径下,解压压安装文件到/opt/module
[root@hadoop101 module]# cd /opt/software/
[root@hadoop101 software]# tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module
- 将hadoop添加到环境变量
修改/etc/profile,将下面命令添加到文件末尾
#HADOOP
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 配置hadoop中的
hadoop-env.sh
[root@hadoop101 etc]# cd /opt/module/hadoop-2.7.2/etc/hadoop
[root@hadoop101 hadoop]# vi hadoop-env.sh
添加绝对路径,因为远程SSH访问的时候可能拿不到。

结束语
这里我们就把hadoop全部安装完成了,总体来说就是安装jdk和hadoop,下篇文章《从0开始学大数据(3):Hadoop运行模式与官网案例》我们就来学习hadoop的运行模式配置和数据计算案例。