准备工作:
1、成功安装Linux(CentOS)系统。
安装CentOS 7详见:https://blog.csdn.net/zxdspaopao/article/details/83277479
2、成功安装jdk。
安装jdk详见:https://blog.csdn.net/zxdspaopao/article/details/83278090
3、成功安装hadoop。
安装hadoop详见:https://blog.csdn.net/zxdspaopao/article/details/83278859
安装过程:
1、配置ssh(免密登陆);
2、配置hdfs-site.xml;
3、配置core-site.xml;
4、配置mapred-site.xml;
5、配置yarn-site.xml;
6、格式化NameNode;
7、启动;
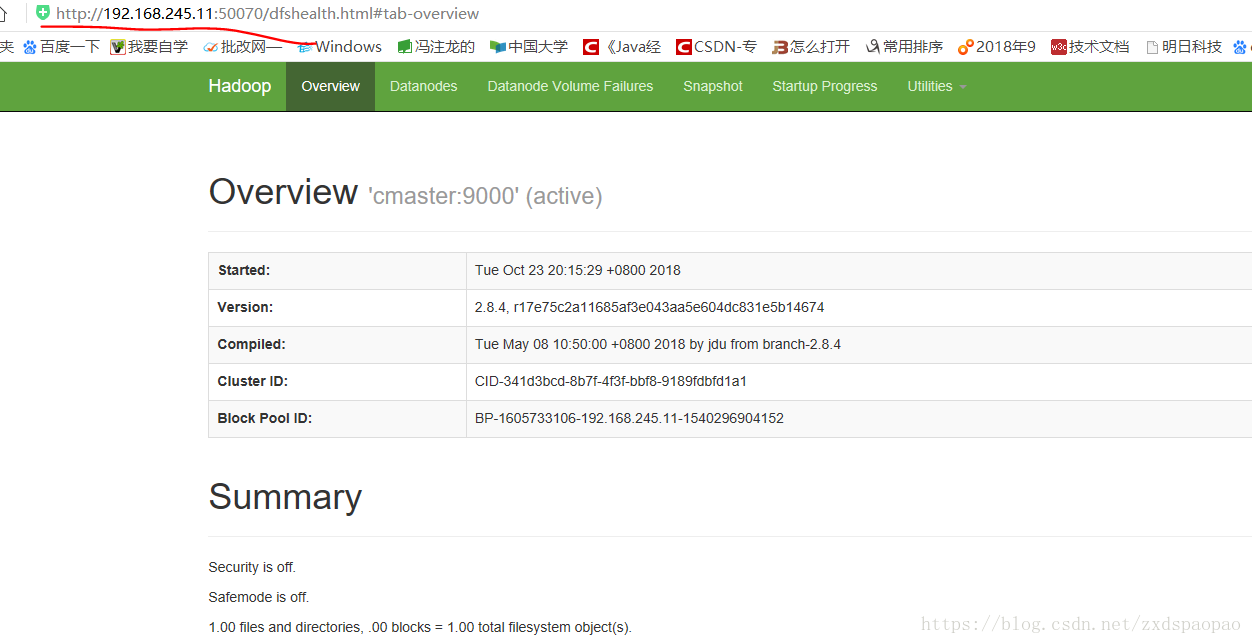
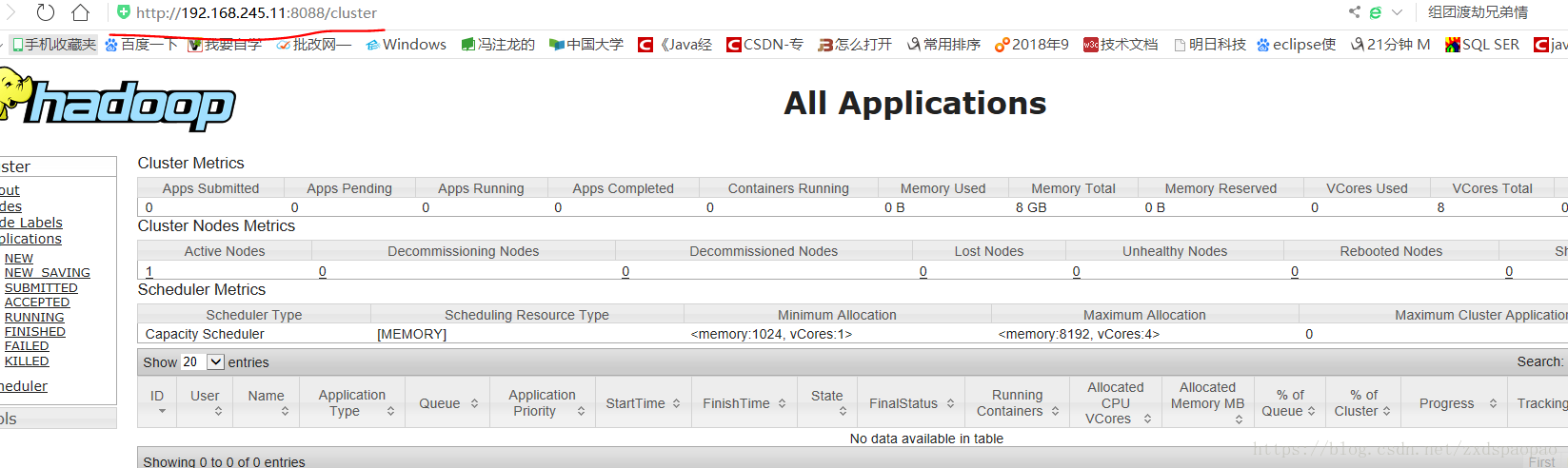
8、访问;
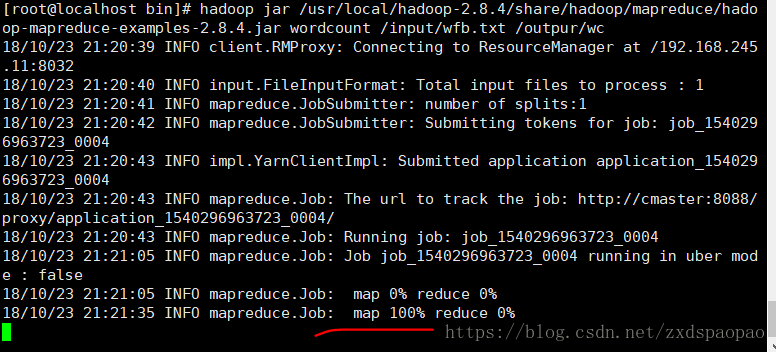
9、运行单词计数程序实例。
1、配置ssh
$ssh-keygen -t rsa
$ll ~/.ssh/
$ssh cmaster
2、配置hdfs-site.xml
#cd /usr/local/hadoop-2.8.4/etc/hadoop
#vi hdfs-site.xml
在<configuration>和</configuration>之间输入以下内容:
<!--配置HDFS的冗余度-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置是否检查权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>3、配置core-site.xml
#vi core-site.xml
在<configuration>和</configuration>之间输入以下内容:
<!--配置HDFS的NameNode-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.245.11:9000</value>
</property>
<!--配置DataNode保存数据的位置-->
<property>mv
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.8.4/tmp</value>
</property> 4、配置mapred-site.xml
#cp mapred-site.xml.template mapred-site.xml
#vi mapred-site.xml
在<configuration>和</configuration>之间输入以下内容:
<!--配置MR运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>5、配置yarn-site.xml
#vi yarn-site.xml
在<configuration>和</configuration>之间输入以下内容:
<!--配置ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.245.11</value>
</property>
<!--配置NodeManager执行任务的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>6、格式化NameNode
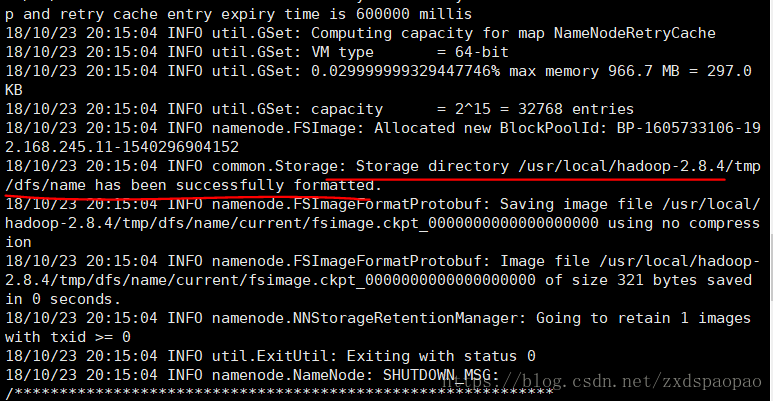
#hdfs namenode -format
出现日志:Storage directory /usr/local/hadoop-2.4.1/tmp/dfs/name has been successfully formatted.
即为成功。
通过查看启动日志分析启动失败原因
有时 Hadoop 无法正确启动,如 NameNode 进程没有顺利启动,这时可以查看启动日志来排查原因,注意几点:
-
启动时会提示形如 “cmaster: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-cmaster.out”,其中 cmaster 对应你的主机名,但启动的日志信息是记录在 /usr/local/hadoop-2.8.4/logs/hadoop-hadoop-namenode-cmaster.log 中,所以应该查看这个后缀为 .log 的文件;
-
每一次的启动日志都是追加在日志文件之后,所以得拉到最后面看,看下记录的时间就知道了。
-
一般出错的提示在最后面,也就是写着 Fatal、Error 或者 Java Exception 的地方。
7、启动
#start.all.sh
- (*) HDFS: 存储数据
- (*) Yarn:执行计算
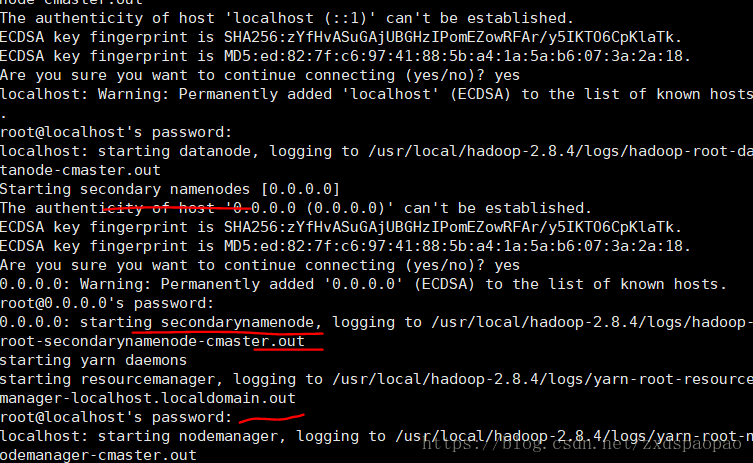
进行免密码配置则不需要重复输入密码。