版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011195398/article/details/88431824
前言
通过上一章《从0开始学大数据(5):HDFS文件系统和常用API》我们学习了一些常用的API进行分析,这章我们来分析HDFS的数据流的写入和读取流程。
1 HDFS写数据的流程
1.1 剖析文件写入
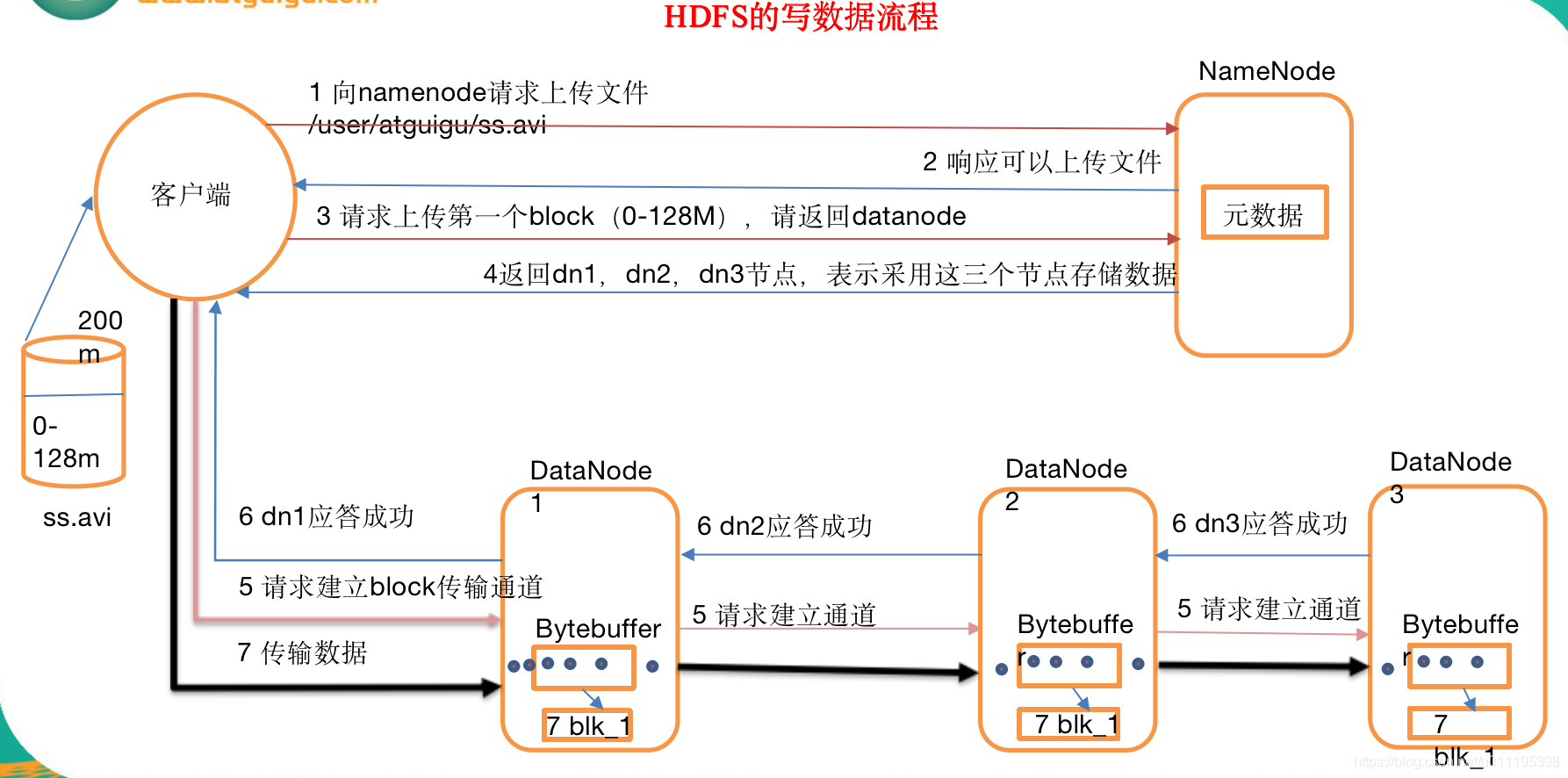
1.2 网络拓扑概念
在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
我们在平台的节点中,选取两个节点A和B并且向上找到他们的共同祖先节点,将A或者B节点到祖先节点的路径相加起来的数字可以得出以下结论:
- Distance(/d1/r1/n1,/d1/r1/n1)=0(同一节点上的进程)
- Distance(/d1/r1/n1,/d1/r1/n2)=2(同一机架上的不同节点)
- Distance(/d1/r1/n1,/d1/r3/n2)=4(同一数据中心不同机架)
- Distance(/d1/r1/n1,/d2/r4/n2)=6(不同数据中心的节点)
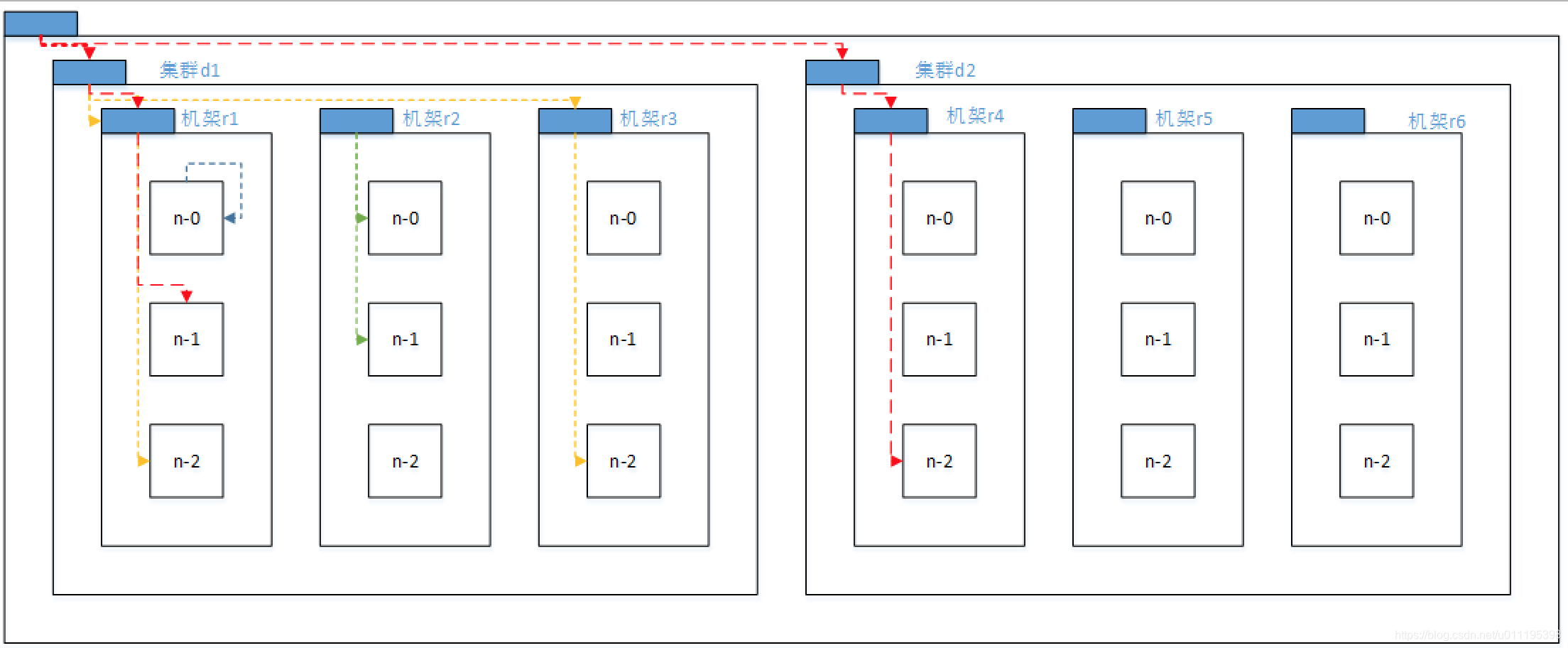
1.3 机架感知
有关于机架感知,我们可以查看官网资料RackAwareness,下面就是数据写入过程中,数据存储选择节点的规则。
- 第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
- 第二个副本和第一个副本位于相同机架,随机节点。
- 第三个副本位于不同机架,随机节点。

public class AutoRack implements DNSToSwitchMapping
{
@Override
public List<String> resolve(List<String> ips)
{
//ips:2 hadoop102 192.168.1.102
List<String> list = new ArrayList<>();
//1.获取机架的ip
if (ips != null && ips.size() > 0)
{
for (String ip : ips)
{
int ipnumber = 0;
if (ip.startsWith("hadoop"))//hadoop102
{
ipnumber = Integer.parseInt(ip.substring(6));
}else{
ipnumber = Integer.parseInt(ip.substring(ip.lastIndexOf(".")+1));
}
//2 自定义机架感知(把102 ,103 放到定义为机架1,把104,105定义为机架2)
if (ipnumber < 104)
{
list.add("/rack1/" +ipnumber);
}else
{
list.add("/rack2/" +ipnumber);
}
}
}
return list;//到具体的机架上
}
@Override
public void reloadCachedMappings()
{
}
@Override
public void reloadCachedMappings(List<String> list)
{
}
}
当我们使用推送到服务器后,存储文件必须到101,102最后一个在104或者105上。
2 HDFS读数据的流程

1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
3. 一致性模型
当我们使用三个数据节点存储数据,此时三个数据库存储的原数据都为10,当我们A客户端对DN1进行数据写入的时候改变了原始数据10为11,此时B客户端对数据进行读取,可能会读取到的数据还是原来的10,那么就不是实时刷新的。所以,我们会使用FsDataOutputStream. hflush ();来对数据进行立即更新,保证其他客户端读取的数据都是最新的,这就是HDFS的一致性模型。
@Test
public void writeFile() throws Exception{
// 1 创建配置信息对象
Configuration configuration = new Configuration();
fs = FileSystem.get(configuration);
// 2 创建文件输出流
Path path = new Path("hdfs://hadoop102:9000/user/atguigu/hello.txt");
FSDataOutputStream fos = fs.create(path);
// 3 写数据
fos.write("hello".getBytes());
// 4 一致性刷新
fos.hflush();
fos.close();
}
小结
这章我们针对HDFS的数据流层,从写数据,存储位置和读数据三个方面讲解,下一章我们学习NameNode的工作流程。