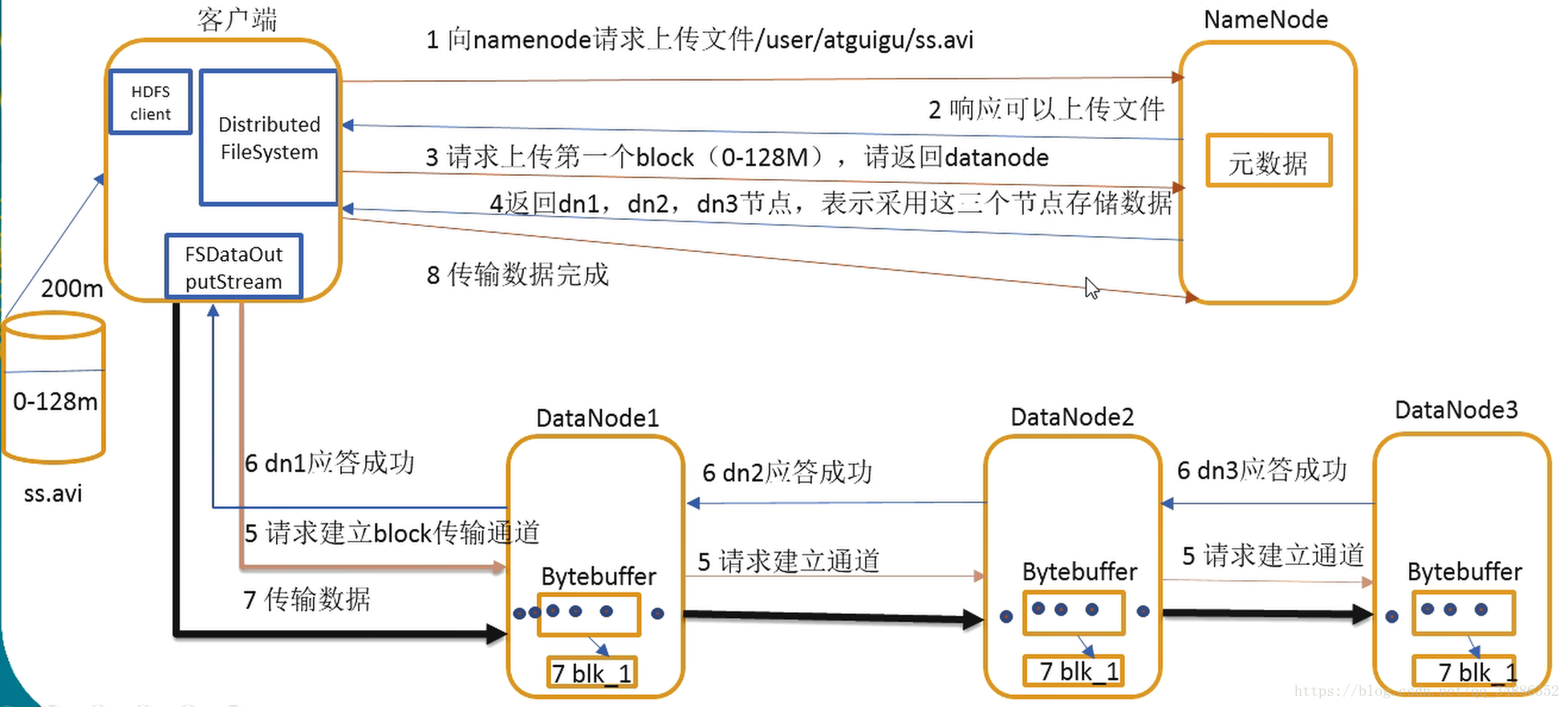
一、HDFS的写数据流程
-
客户端通过Distributed FileSystem模块namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
-
namenode返回是否可以上传
-
客户端请求第一个block上传到哪几个datanode服务器上
-
namenode放回3个datanode节点,分别为dn1、dn2、dn3。
-
客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2、然后dn2调用dn3,将这个通信管道建立完成。
-
dn1、dn2、dn3逐级应答客户端
-
客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给 dn3;dn1每传一个packet会放入一个应答队列等待应答
-
当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器(重复3-7)
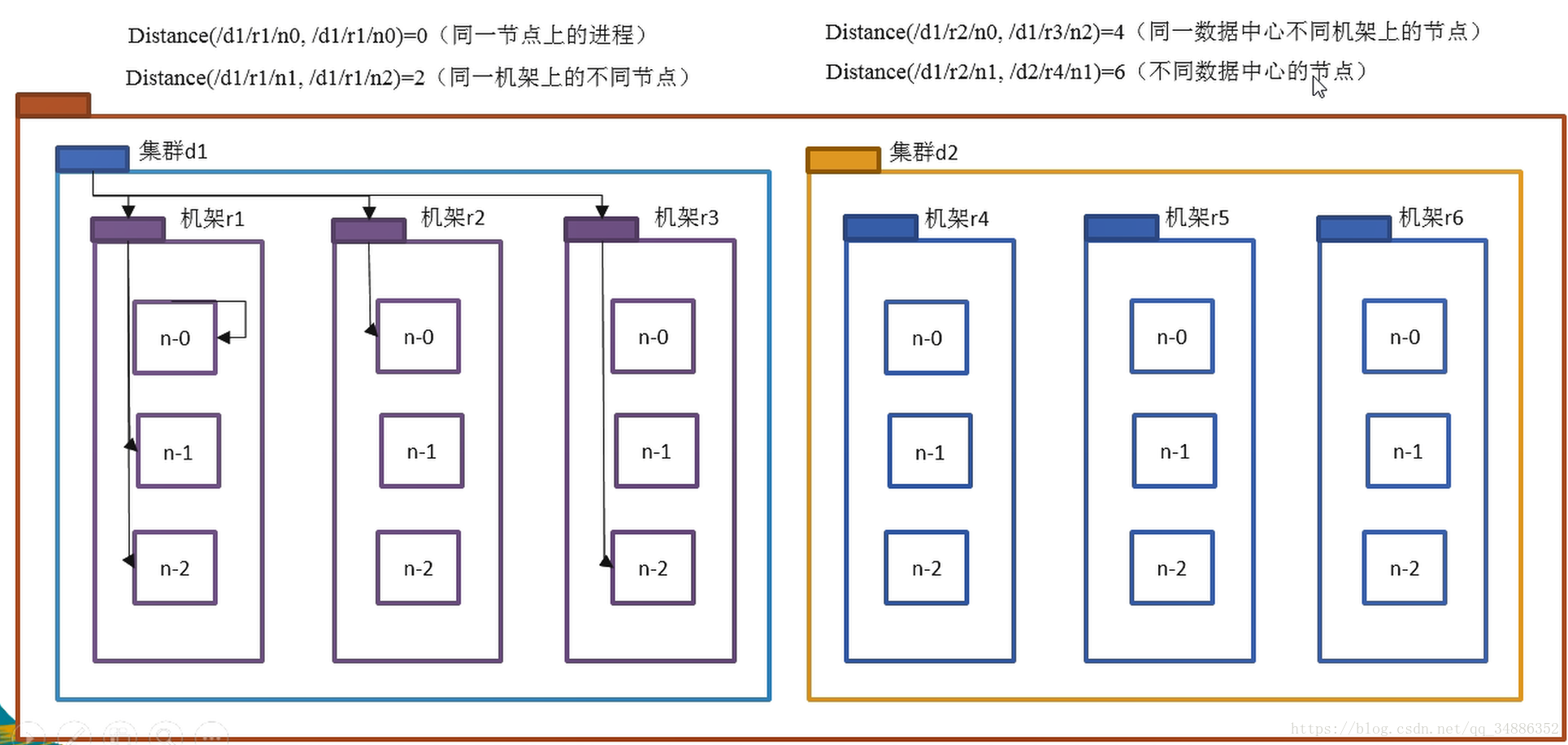
二、网络拓扑概念
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输效率——带宽很稀缺。这里的想法是将两个节点的带宽作为距离的很亮标准。
节点距离:两个节点到达最近的共同祖先的距离总和。
三、机架感知(副本节点选择)
在1000个节点中,副本数为3那么我们 如何选出这3个副本的位置
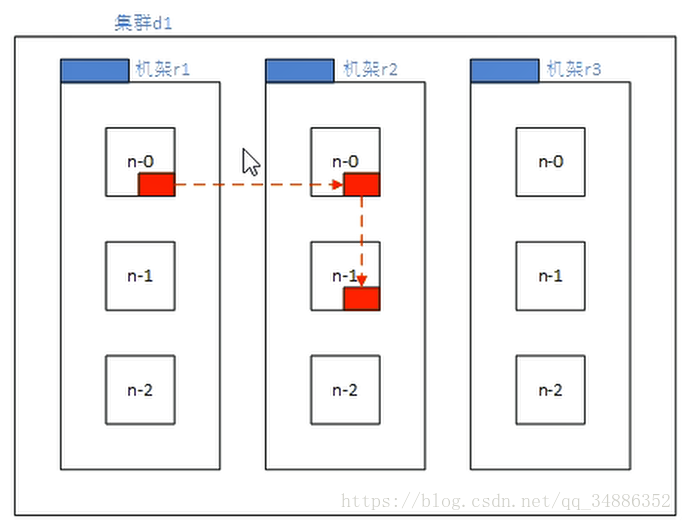
1.低版本的Hadoop副本节点选择
-
第一个副本在Client所在的节点上。如果客户在集群外,随机选择一个。
-
第二个副本和第一个副本位于不相同机架的随机节点上。
-
第三个副本和第二个副本位于相同机架的随机节点上。
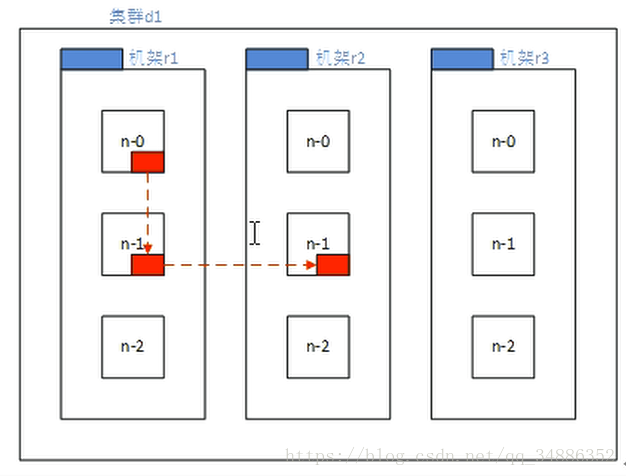
2.Hadoop2.7.2副本节点选择
-
第一个副本在client所在的节点上。如果客户端在集群外,随机选择一个。
-
第二个副本和第一个副本位于相同机架,随机节点
-
第三个副本位于不同机架的随机节点
3.HDFS如何控制客户端读取哪个副本节点的数据
HDFS满足客户端访问副本数据的最近原则,即客户端距离哪个副本数据最近,HDFS就让哪个节点把数据给客户端。
四、HDFS的读取数据流程
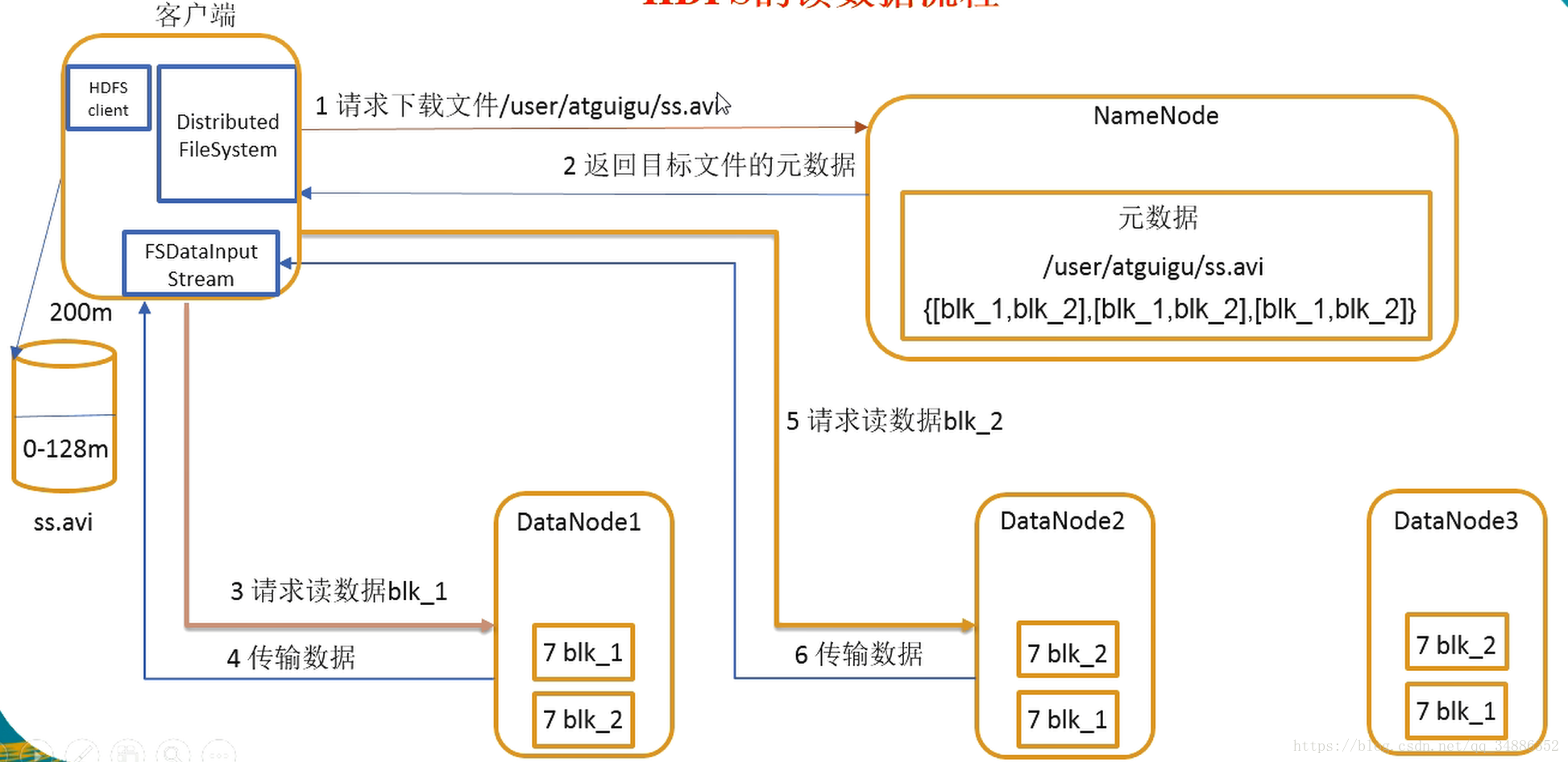
-
客户端通过Distributed FileSystem向namenode请求下载文件,namenode通过查询元数据,找到文件所在的datanode地址。
-
挑选一个datanode(就近原则),然后选择服务器
-
datanode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)
-
客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
五、一次性数据模型
// 1 连接hdfs
Configuration entries = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.44.128:9000"), entries, "gyx");
// 2 输出流获取上传路径
FSDataOutputStream fos = fileSystem.create(new Path("/hello2.txt"));
// 3 写数据
fos.write("hello".getBytes());
// 4 一致性刷新
fos.hflush();
// 5 关闭流
IOUtils.closeStream(fos);
fileSystem.close();如果第4步不存在,则在流关闭之后才会将数据写入磁盘,之前一直存在于缓存中
写入数据时,如果希望数据被其他client立即可见,就可以使用FsDataOutputStream.hflush();