博客内容来自我啃的Hadoop权威指南,记录一下帮助自己理一下思路
一、文件读取
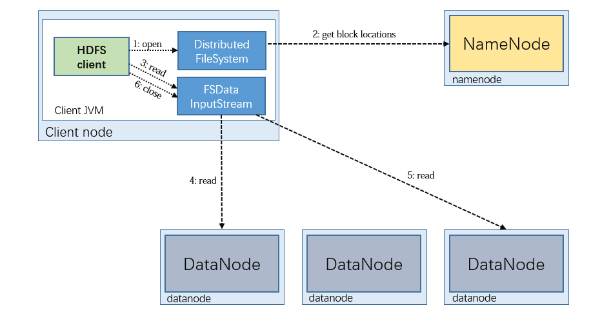
- 步骤1,客户端通过调用 FileSystem 对象的 open() 方法来打开想读取的文件,对于 HDFS 来说,这个对象是分布式文件系统(DistributedFileSystem)的一个实例
- 步骤2,DistributedFileSystem 通过使用 RPC 来调用 namenode ,获取文件的存储位置,以确定文件起始块的位置。namenode 返回文件所有组成块的副本的 datanode 地址。并且这些 datanode 地址信息是已经排过序的。DistributedFileSystem 的 open() 方法返回一个 FSDataInputStream 对象给客户端读取数据。FSDataInputStream 类封装了DFSInputStream 对象,该对象管理着 datanode 和 namenode 的 I/O。
- 步骤3,客户端对 FSDataInputStream 对象调用 read() 方法,存储着文件起始几个块的datanode地址的DFSInputStream随即连接距离最近的文件中第一个块所在的datanode。
- 步骤4,通过对数据流反复调用read()方法,可以将数据从datanode传输到客户端。
- 步骤5,到达块的末端时,DFSInputStream关闭与该datanode的连接,然后寻找下一个块的最佳datanode。
- 步骤6,客户端从流中读取数据时,块是按照打开DFSInputStream与datanode新建连接的顺序读取的,它也会根据需要询问namenode来检索下一批数据块的datanode位置。一旦客户端完成读取,就对FSDataInputStream调用close()方法。
二、写入文件
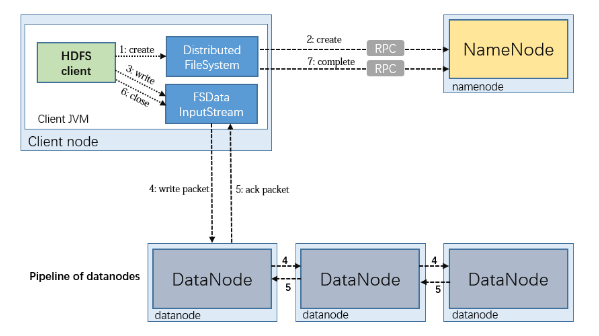
- 步骤1,客户端通过对DistributedFileSystem对象调用create()函数来新建文件。
- 步骤2,DistributedFileSystem对namenode创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时该文件中还没有相应的数据块。namenode执行各种不同的检查以确保这个文件不存在以及客户端有新建文件的权限。如果这些检查均通过,namenode就会为创建新文件记录一条记录
- 步骤3,客户端写入数据。
- 步骤4,在客户端写入数据时,DFSOutputStream将它分成一个个的数据包,并写入内部队列,称为“数据队列”(data queue)。DataStreamer处理数据队列,它的责任是根据datanode列表来要求namenode分配适合的新块来存储数据复本。这一组datanode构成一个管线——我们假设复本数为3,所以管线中有3个节点。DataStreamer将数据包流式传输到管线中第一个datanode,该datanode存储数据包并将它发送到管线中的第二个datanode。同样,第二个datanode存储该数据包并且发送给管线中的第三个(也是最后一个)datanode。
- 步骤5,DFSOutputStream也维护着一个内部数据包队列来等待datanode的收到确认回执,称为“确认队列”(ack queue)。收到管道中所有datanode确认信息后,该数据包才会从确认队列删除
- 步骤6,客户端完成数据的写入后,对数据流调用close()方法
- 步骤7,该操作将剩余的所有数据包写入datanode管线,并在联系到namenode且发送文件写入完成信号之前,等待确认。namenode已经知道文件由哪些块组成(通过Datastreamer请求分配数据块),所以它在返回成功之前只需要等待数据块进行最小量的复制。