分类目录:《知识图谱从入门到应用》总目录
知识工程发展历史
在前面的文章中,曾介绍过早期的人工智能有一个流派称为符号主义。符号主义认为智能的本质就是符号的操作和运算。符号主义在后来几大流派的较量中,曾长期一枝独秀,为人工智能的发展做出重要贡献。但在20世纪60年代到70年代初,符号主义主导的人工智能遭遇第一次寒冬。研究者们开始重新审视、思考未来的道路。Feigenbaum提出人工智能必须引进知识,并提出了专家系统。专家系统一般由两部分组成——知识库与推理引擎。1977年,Feigenbaum将其正式命名为知识工程。

知识工程诞生之后,经过繁荣发展,不断产生了新的知识表示语言和方法。随后万维网的出现,为基于互联网获取知识提供了极大的方便。1998年,万维网之父蒂姆·伯纳斯·李提出的Semantic Web本质上就是“互联网上的知识工程”,即鼓励大家通过互联网采用统一的知识表示方法来发布自己的数据,从而让互联网上的数据更加易于被机器自动处理。在20世纪七八十年代,传统的知识工程的确解决了很多的问题,但是这些问题都有一个很鲜明的特点,即它们大部分都是在规则明确、边界清晰、应用封闭的场景取得的成功,一旦涉及开放的问题就比较难以实现。传统知识工程通常是自上而下实现的,需要依赖专家表达、获取和运用知识。这就会存在很多问题:一方面,人工构建的知识库规模和知识覆盖面很有限;另外一方面,由于专家对知识的认知很难完全统一,而且专家知识也具有高度的不确定性、不精确性,导致其实很难用统一的符号精确刻画专家大脑中的知识,这也是著名的知识汤概念的内涵。
知识获取的瓶颈问题
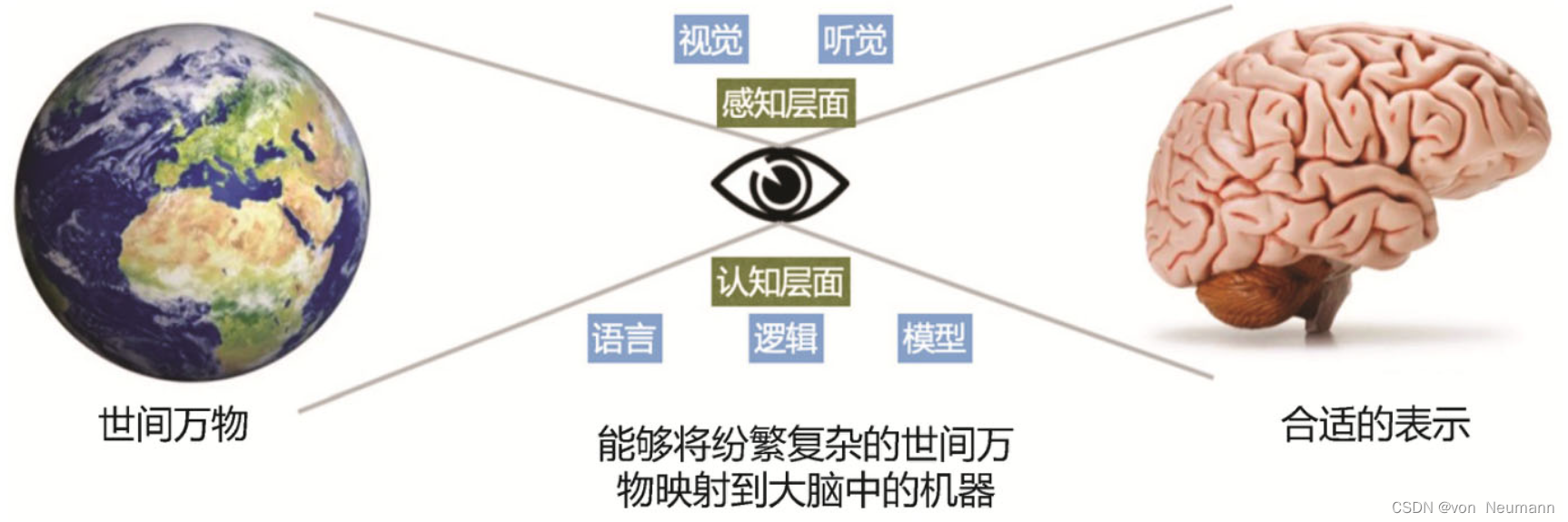
再换一个视角来探讨知识获取的瓶颈问题:成年人脑包含近1000亿个神经元,每个神经元都可能有近千个连接。模拟这样的人脑需要约100TB的参数。假设这100TB的参数能完整地存储人脑中的知识,靠人工编码可以获取这样规模的知识吗?单个人脑中的知识仍然是有限的,如果需要获取全人类知识,靠人工编码是无法完的。这就是人工获取人类知识的天花板。因此,计算机领域始终有一个持久性的研究命题:挑战机器自主获取知识的极限。首先从感知层面,机器应该具备基本的事物与对象的识别能力。深度学习的一个重大贡献是在感知层面实现了事物的准确识别,但仅仅识别是远远不够的。我们看到一张图片,不仅要识别其中包含的对象,还需要理解图片中事物之间的关联关系,并进一步从感知产生知识。
再进一步到认知层面,人类从通过识别世间万物形成关于万物的知识,进而形成关于万物的概念,并发明了语言描述这些概念。概念之间相互组合,进而产生逻辑,依赖这些逻辑来完成推理。更为复杂的知识来源于我们对事物关系更深层次的把握,比如那些数学符号所描述的模型就是依赖概念符号进一步抽象出来的更深层次的关于世界的知识。显然,让机器能自动地从识别感知出发构建概念,进而产生逻辑和生成模型,还有非常漫长的路要走,机器知识获取依然道阻且长。
知识图谱工程
人类知识是复杂的,利用机器来表示和自动化获取全部的人类知识是困难的。知识图谱不希望陷入传统知识工程的困境当中,因此首先把知识获取的内容限定于界面比较清晰的任务,例如概念抽取、实体识别、关系抽取、事件抽取等。同时,知识图谱的构建更加强调依靠大数据来自动化地获取,更加注重知识的规模。
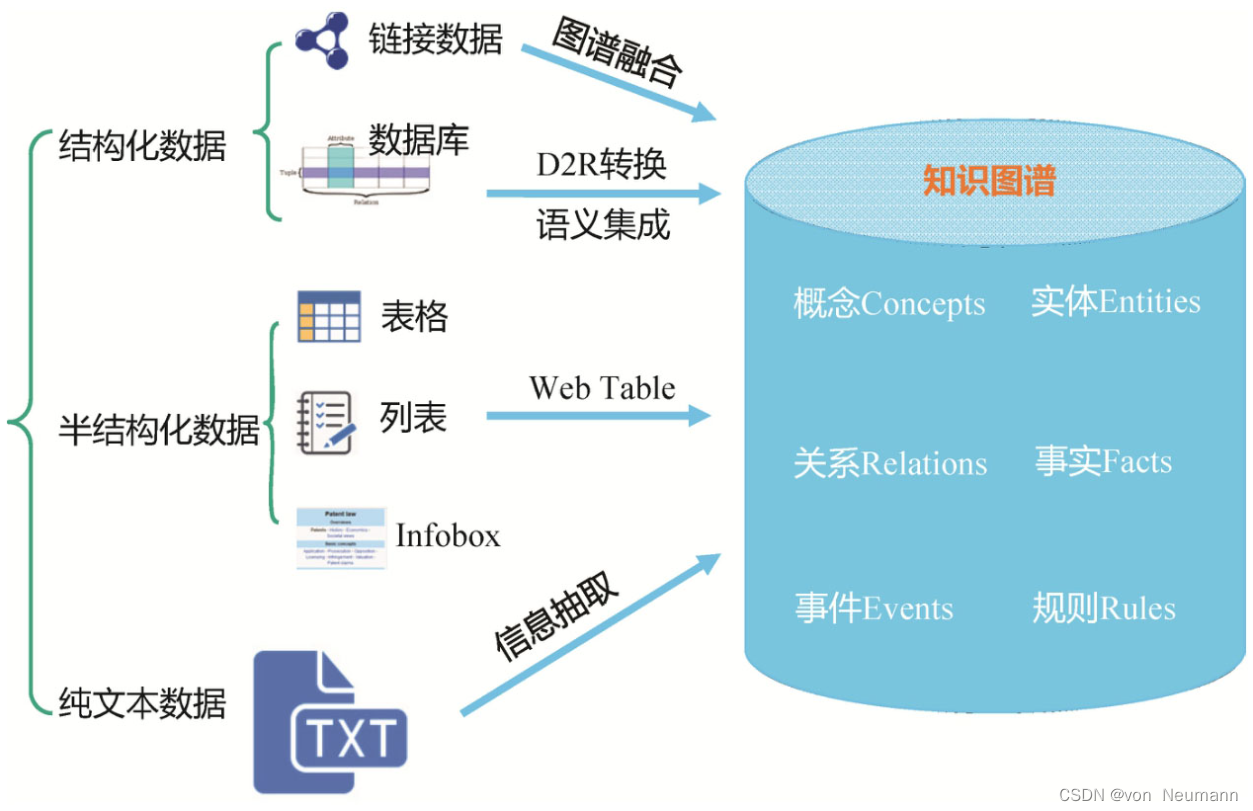
知识图谱构建的数据来源可以是文本、多媒体数据、结构化数据或半结构化数据等。不同类型的数据来源有各自不同的技术手段。通常,绝大部分知识图谱工程项目是通过已有的结构化数据完成冷启动,再进一步利用文本、图片等数据进一步补全知识图谱。最为直接快速地获取知识图谱的数据的方法是从已有的关系数据库中抽取。通常的做法是先定义一个Common Schema或本体,然后通过定义一个映射语言,将关系模型映射到本体语言。如图所示,基于W3C定义的R2RML语言可以定义从关系表到RDF Schema的映射,从而精准地实现从关系数据库提取需要的知识图谱数据。在视觉领域也有一个和知识图谱相关的领域称为Scene Graph Construction,指的是在识别对象的基础上,进一步识别对象之间的关联关系,并形成关系图谱。在计算机视觉领域有非常多的研究怎样从大量视觉数据中获取知识图谱数据,或者利用图片数据来补全知识图谱。
后面的文章更多地关心怎样从文本中获取知识图谱数据。这主要可以分解为如下几个方面的任务:
- 命名实体识别主要完成从文本中识别实体:这是进一步识别三元组的基本条件
- 概念抽取:从大量语料中发现多个单词组成的相关术语
- 关系抽取:从句子中抽取一组实体之间的关系,比如怎样从“王思聪是万达集团董事长王健林的独子”,抽取出知识图谱需要的三元组关系:
([王健林]<父子关系>[王思聪])。
更为复杂的任务还包括怎样从文本中抽取事件。事件是更为复杂的结构化数据,一个事件至少包含一个触发词,例如“发生爆炸”,同时还需要抽取多个要素,例如事件发生的事件、地点、涉及的对象等。一个事件抽取的过程可以看作一组三元组的联合抽取过程。接下来将逐一介绍从文本抽取知识图谱数据的一系列技术和方法。
知识图谱与传统知识工程的差异
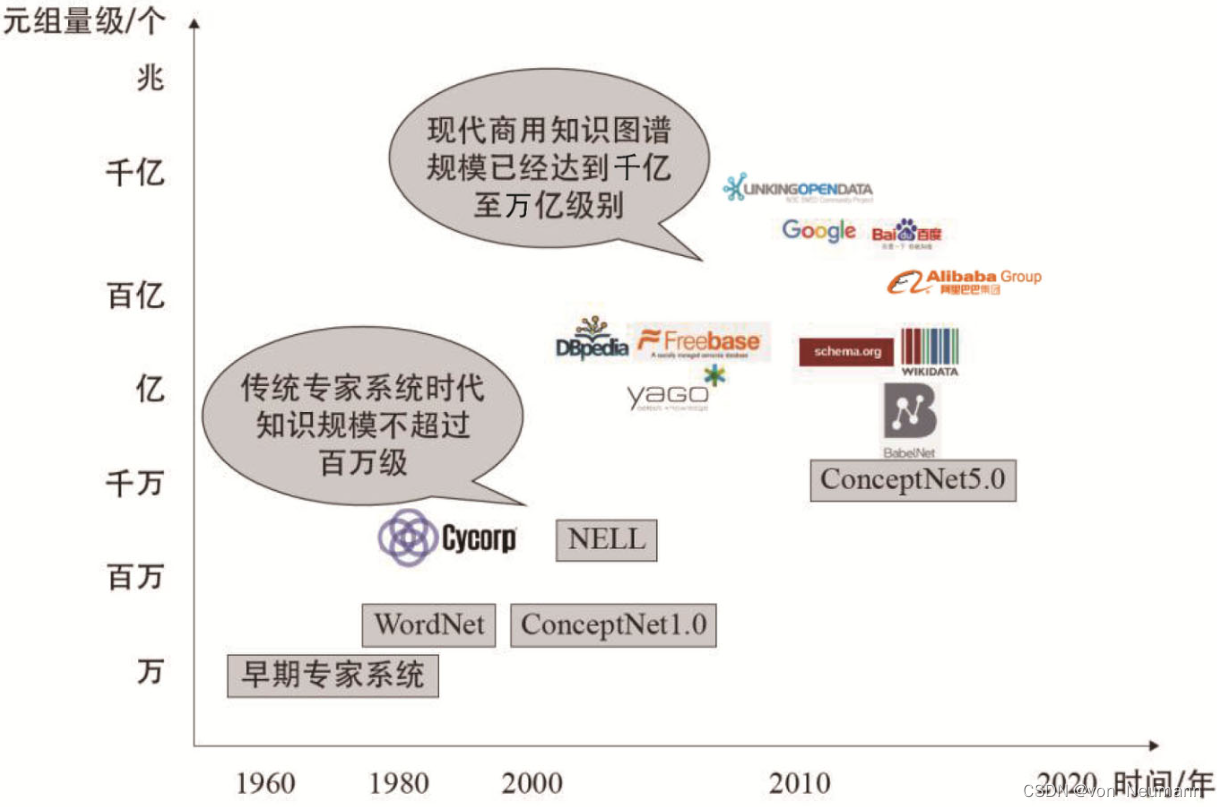
知识图谱不等于传统意义的专家系统,也和传统意义的知识工程有很多不一样的地方。传统知识工程极大地依赖人工,且对知识表示的要求比较高,例如Cyc项目可以采用高阶的谓词逻辑来描述知识,而知识图谱获取的对象是相对简单的实体和三元组。这就为知识的自动化获取提供更多的便利,从而大大提高了现代知识图谱的规模。例如,当前阿里、百度、美团、谷歌等企业构建的知识图谱都已经达到千亿级别规模,并在向万亿级别迈进。这是传统专家系统时代的知识工程所不能比的。同时,构建知识图谱的成本也大大降低,在ISWC2018上有一篇论文题目叫How much is a triple。文章大致统计了几个典型知识库项目的平均构建成本。可以看到,传统的Cyc项目每条知识构建成本是5.71美金,而到了Yago知识库,一条知识的成本已经降低至0.83美分。这样的成本使得很多小领域就可以实现低成本的知识工程。当然,成本的降低也是极大地得益于各个领域已有数据的积累以及大数据技术的不断进步。
参考文献:
[1] 陈华钧.知识图谱导论[M].电子工业出版社, 2021
[2] 邵浩, 张凯, 李方圆, 张云柯, 戴锡强. 从零构建知识图谱[M].机械工业出版社, 2021