前言:由于以前是学了爬虫的,以前常用request,bs4,re等来爬去网页等数据,也做过一些大型网站,后来很多人都说request适合网页级爬虫,爬网站级还是异步的scrapy框架好,二者都是优秀的爬虫工具,request适合新手,入门很轻松,爬取的逻辑和过程也好理解,scray入门稍难是一个系统的5+2结构,很有可能会懵逼,要花一段时间理解运用,才能逐渐理解这个框架,毕竟官方的文档写的说明就那样了....
今天就说下爬取简书的网站级爬虫,在爬虫分类或者专栏里有scrapy框架和request系列的爬虫过程,以及讲解,存入mysql,或者excel等,点击传送门:https://blog.csdn.net/memory_qianxiao/column/info/29130
老规矩镇楼图如下:

当然最有意思的是看到浏览器自己动,真的感觉很爽~
一:环境:python3 +pycharm+selenium+scrapy+mysql
安装scrapy比较简单:pip install scrapy会自动下载适应你电脑里的python版本或者在pycharm接口里面添加,selenium类似
一般我们都有了,需要重点说明的是谷歌驱动下载,这里给出传送门:http://chromedriver.storage.googleapis.com/index.html
里面有各版本对应谷歌浏览器的驱动版本,下载了解压后随便放在一个英文文件夹里面。
二:开始一个项目
开始之前先看下scrapy的常用命令
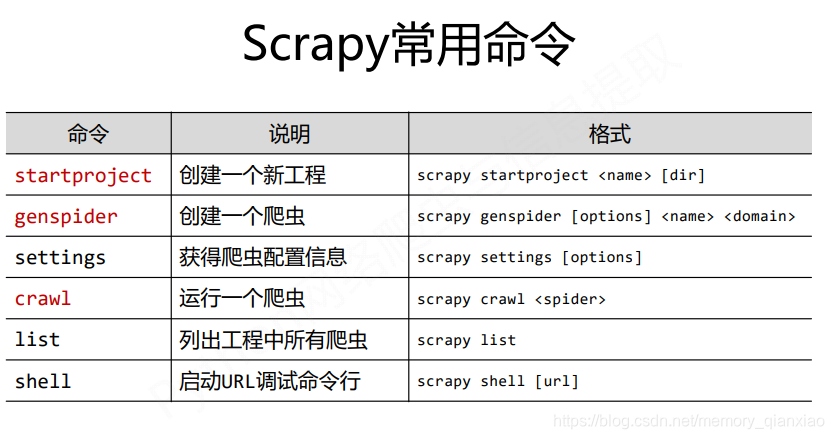
创建一个项目:在命令窗口下scrapy startproject +项目名
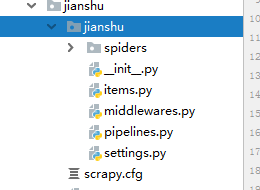
eg:scrapy startproject jianshu
会自动生成如下目录:
三:创建spider爬虫 :一般是scrapy genspider +爬虫名+爬取的域名
不过今天我用的是crawl模版爬虫所以在命令界面是这样的:scrapy genspider -t crawl +项目名+爬取域名
eg:scrapy genspider -t crawl jianshu_spider jianshu.com会在spider目录下生成一个jianshu_spider的爬虫文件如下:
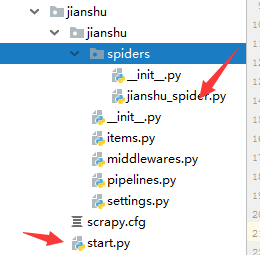
为了方便启动和减少启动次数输入的代码,新建一个start文件,代码如下,以后每次启动就不需要每次输入scrapy crawl jianshu_spider代码了,直接鼠标右键启动就行了。
start.py
from scrapy import cmdline
cmdline.execute("scrapy crawl jianshu_spider".split())四:在setting里面把遵守爬虫协议改为不遵守
ROBOTSTXT_OBEY = True 改为-》ROBOTSTXT_OBEY = False
取消DEFAULT_REQUEST_HEADERS 注释,加入自己的浏览器user-agent信息伪装浏览器。

你的user-agent,浏览器按F12,选择network,随便选中一个boss直聘中的一个文件,复制其中的user-agent

五: 打开items.py文件,在BossJobItem定义item容器,方便数据的存储,以及数数据的表的建立(和django中的module类似)
代码如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JianshuItem(scrapy.Item):
title=scrapy.Field()#标题
content=scrapy.Field()#内容
origin_url=scrapy.Field()#文章的url
author=scrapy.Field()#作者
pub_time=scrapy.Field()#发布时间
read_count=scrapy.Field()#阅读量
like_count=scrapy.Field()#点赞量
word_count=scrapy.Field()#文章字数
subjects=scrapy.Field()#文章分类标签
六:把jianshu中的spider编写完成
提取方法是用的是框架自带的xpath,很方便的,还有css,re,等也可以用,提取过程可以在scrapy shell测试,测试完成后就能保证提取的准确性。如果不知道xpath提取,可以看如下菜鸟教程:
菜鸟教程xpath教程:http://www.runoob.com/xpath/xpath-tutorial.html
代码如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from 简书.jianshu.jianshu.items import JianshuItem
class JianshuSpiderSpider(CrawlSpider):
name = 'jianshu_spider'
allowed_domains = ['jianshu.com']
start_urls = ['http://jianshu.com/']
rules = (
#每个文章的链接提取规则,fllow=true自动提取其他类似的的文章
Rule(LinkExtractor(allow=r'/p/[0-9a-z]{12}'), callback='parse_detail', follow=True),
)
def parse_detail(self, response):
title=response.xpath('//h1[@class="title"]//text()').get()
content=response.xpath('//div[@class="show-content-free"]').get()
author=response.xpath('//span[@class="name"]/a/text()').get()
pub_time=response.xpath('//span[@class="publish-time"]/text()').get()
word_count = response.xpath('//span[@class="wordage"]/text()').get().split()[-1]
read_count=response.xpath('//span[@class="views-count"]/text()').get().split()[-1]
like_count = response.xpath('//span[@class="likes-count"]/text()').get().split()[-1]
subjects=','.join(response.xpath('//div[@class="include-collection"]//a/div/text()').getall())
item=JianshuItem(
title=title,
content=content,
author=author,
pub_time=pub_time,
origin_url=response.url,
word_count=word_count,
read_count=read_count,
like_count=like_count,
subjects=subjects
)
yield item七:创建mysql数据库,编写pipelines对数据进行清洗入mysql库
对python操作mysql增删改差不太熟悉的朋友请点击传送门:https://blog.csdn.net/memory_qianxiao/article/details/82620079
创建数据库表结构如下:

# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from twisted.enterprise import adbapi
from pymysql import cursors
class JianshuPipeline(object):
def __init__(self):
dbparams={
'host':'127.0.0.1',
'port':3306,
'user':'test',
'password':'123',
'database':'简书',
'charset':'utf8'
}
self.conn=pymysql.connect(**dbparams)
self.cursor=self.conn.cursor()
def process_item(self, item, spider):
self.sql = """insert into article(title,content,author,pub_time,origin_url,
read_count,like_count,word_count,subjects) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"""
self.cursor.execute(self.sql,(item['title'],item['content'],item['author'],item['pub_time'],
item['origin_url'],item['read_count'],item['like_count'],item['word_count'],item['subjects']))
self.conn.commit()
return item
#**********异步插入数据库****************
class JianshuTwistedPipeline(object):
def __init__(self):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'test',
'password': '123',
'database': '简书',
'charset': 'utf8',
'cursorclass':cursors.DictCursor
}
self.dbpool=adbapi.ConnectionPool("pymysql",**dbparams)
def process_item(self,item,spider):
self.sql = """insert into article(title,content,author,pub_time,origin_url,
read_count,like_count,word_count,subjects) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"""
defer=self.dbpool.runInteraction(self.insert_item,item)
defer.addErrback(self.handle_error,item,spider)#定义错误提示语句
def insert_item(self,cursor,item):
cursor.execute(self.sql,(item['title'],item['content'],item['author'],item['pub_time'],
item['origin_url'],item['read_count'],item['like_count'],item['word_count'],item['subjects']))
def handle_error(self,error,item,spider):
print("="*30+"errror"+"="*30)
print(error)
上面pipeline的代码两个类,JianshuPipeline和JianshuTwistedPipeline,第一个是同步存入mysql,第二个是异步存入mysql需要用到dbpool实现,在teisted这个包中,数据io操作异步相对同步来说,效率高,亲测小规模爬虫其实同步和异步差别不大~
八:编写完后pipelines需要在setting 里面把ITEM_PIPELINES注释取消,才能生效

九:改写下载驱动,让scrapy的驱动为selenium,在middlewares中,在只保留代码如下:
selenium基本用法请点击传送门:https://blog.csdn.net/qq_29186489/article/details/78661008
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import time
from scrapy import signals
from selenium import webdriver
from scrapy.http.response.html import HtmlResponse
#如果返回的是response就不会发给下载器,直接返回给爬虫,捕获爬虫,不走scrapy框架下载页面
class SeleniumDownloadMiddleware(object):
def __init__(self):
self.driver=webdriver.Chrome(executable_path=r"D:\chromedriver_win32\chromedriver.exe")
def process_request(self,request,spider):
self.driver.get(request.url)
time.sleep(1)
try:
while True:
#获取简书标签更多的按钮,模拟点击
showMore=self.driver.find_element_by_class_name('show-more')
showMore.click()#点击
time.sleep(0.3)
if not showMore:
break
except:
pass
source=self.driver.page_source
response=HtmlResponse(url=self.driver.current_url,body=source,request=request,encoding='utf-8')
return response十:在setting里面把DOWNLOADER_MIDDLEWARES注释取消,同时把中间件改成SeleniumDownloadMiddleware如下:
DOWNLOADER_MIDDLEWARES = {
'jianshu.middlewares.SeleniumDownloadMiddleware': 543,
}十一:运行爬虫
找到开始创建的start.py文件鼠标右键就能运行,结果如下(在写博客的时间我的代码一直在运行,稳定性很好):



十二:总结
scrapy是一个性能非常优秀的框架,很多网站有一些反爬策略,我们可以添加user-agent,更换ip代理,hearder里面添加cook信息,减缓爬取的速度....要熟练的爬取各种网站,需要不断的实践练习,然后自己的经验和对框架和一些库有了自己的理解,真正的知道它们的用法,慢慢形成了自己的爬取风格,学习最开始就是模仿的过程,然后学习过程中有了自己的风格~