(一)PYTHON的安装(已安装,可跳过此步骤)
1、PYTHON下载
PYTHON官网:https://www.python.org/
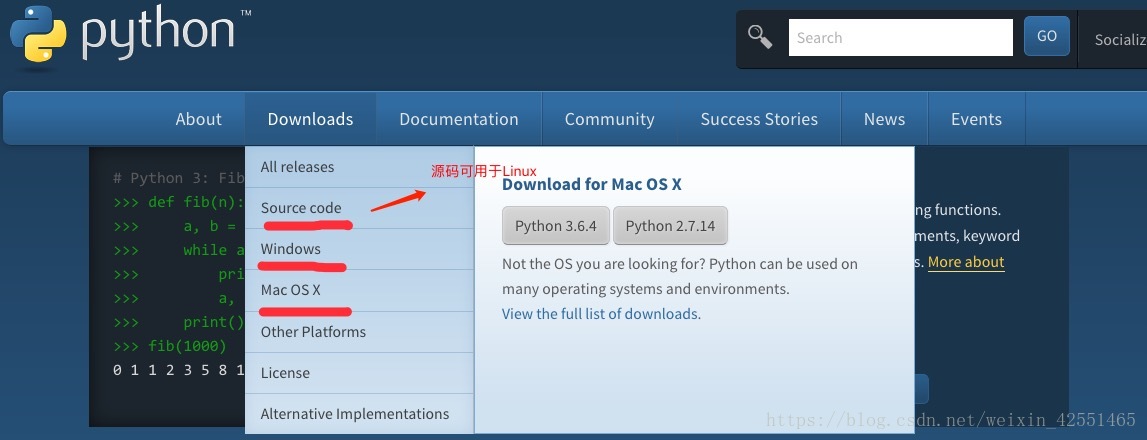
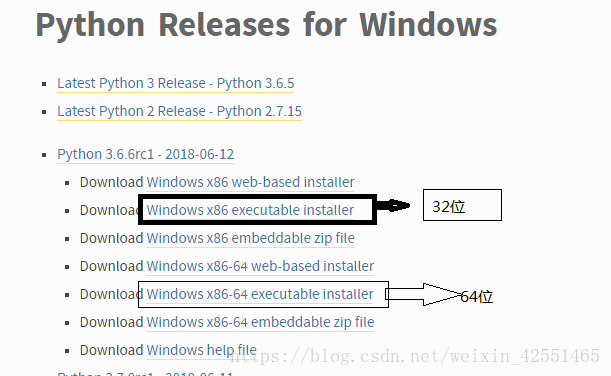
按照对应的系统下载,我这里是window系统,点击windows,根据自己系统操作位数下载
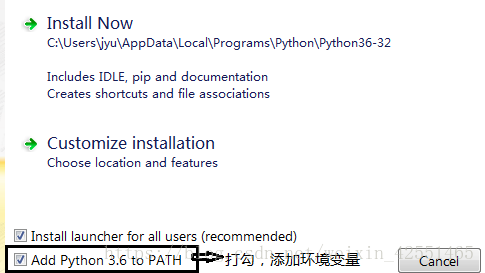
添加环境变量:
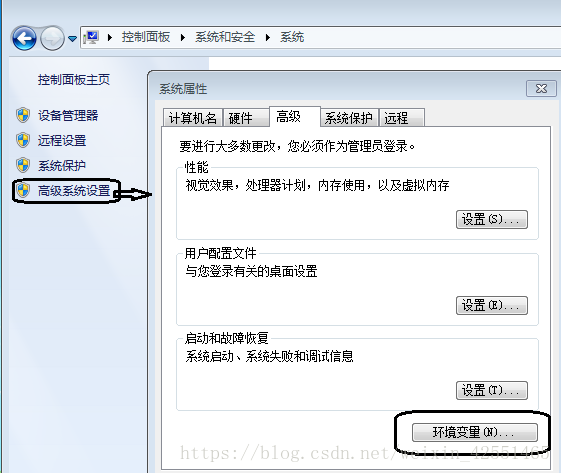
如果没有添加,可自行在计算机添加
(二)第三方库的安装
安装selenium和pyquery,在cmd命令下输入 pip install selenium(pyquery安装类似)
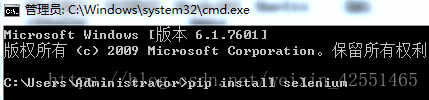
如果报错则进入python目录下scripts目录下,再输入命令

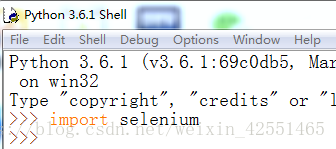
在python的IDLE下如果没有报错则安装成功
(三)浏览器及相应浏览器驱动的安装
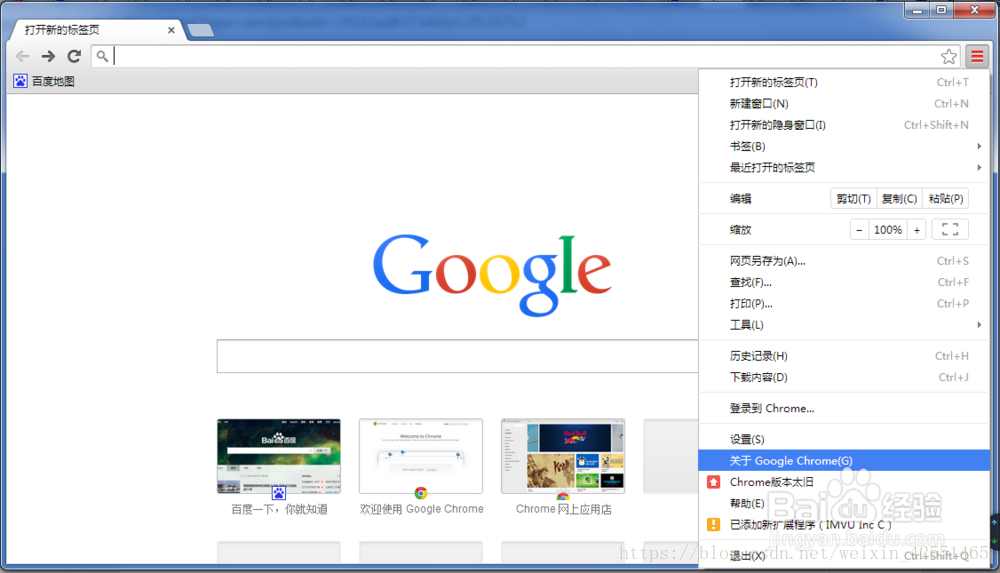
这里主要使用chrome浏览器,自行去谷歌官网下载安装,安装后查看谷歌版本,单击关于google chrome
(一般在这里都可以找到)
我的版本:67.0
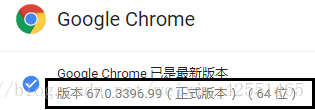
下载对应的webdriver (这里没有可以自己推测每3个版本,对应一个v65-67---v2.38,即v68-70--v2.39)
下载地址:http://chromedriver.storage.googleapis.com/index.html
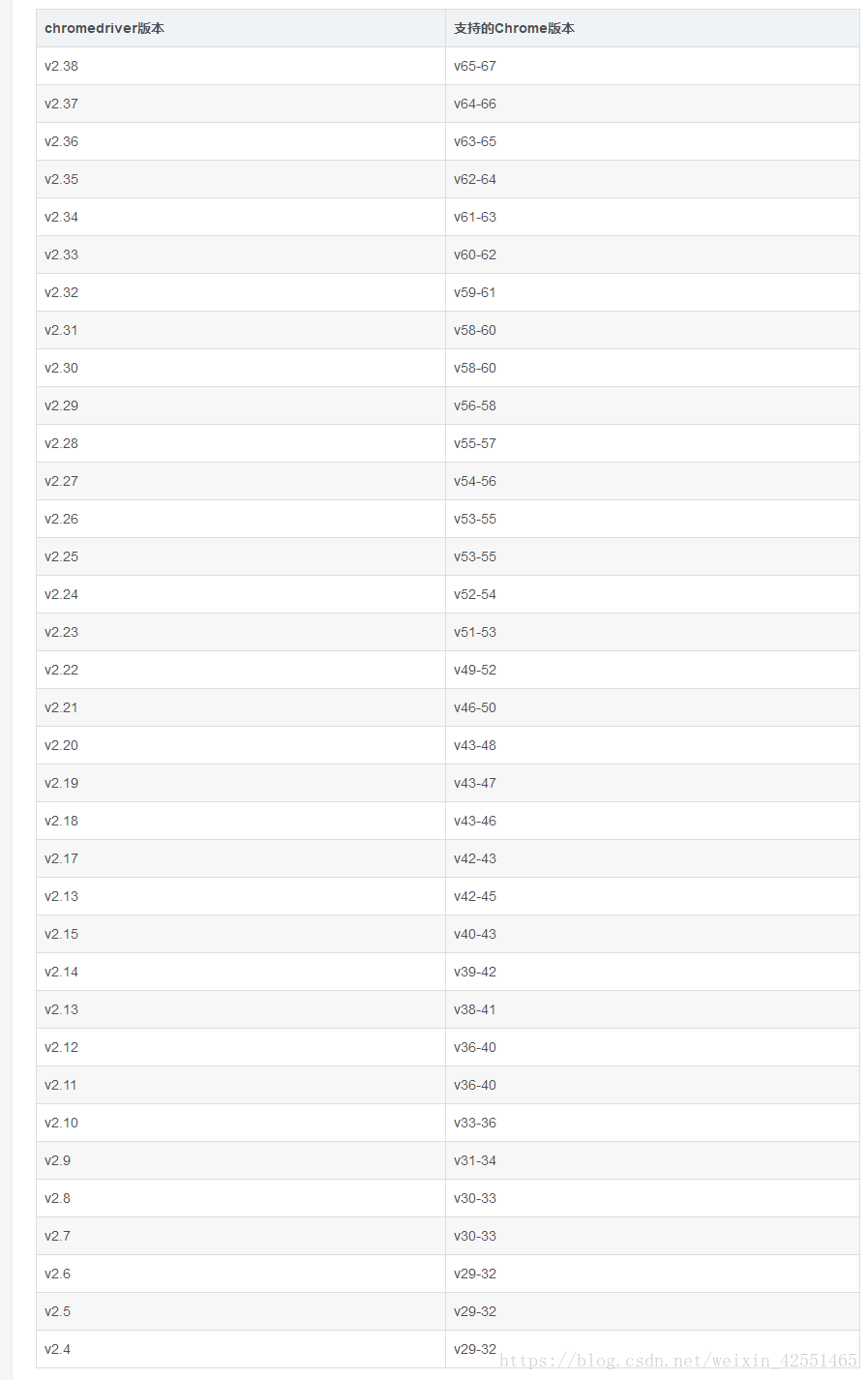
把下载好的chromedriver.exe,解压后放到python36目录下(或者python36目录下的scripts)
在IDLE下执行如下代码,会自动打开你谷歌浏览器(环境搭建完成)

(四)实例代码详解
要求:爬取https://www.xuangubao.cn/股票网站的信息((“利好”或“利空”)和“相关股票”),实现点击加载更多
(1)打开浏览器,获取相关讯息:

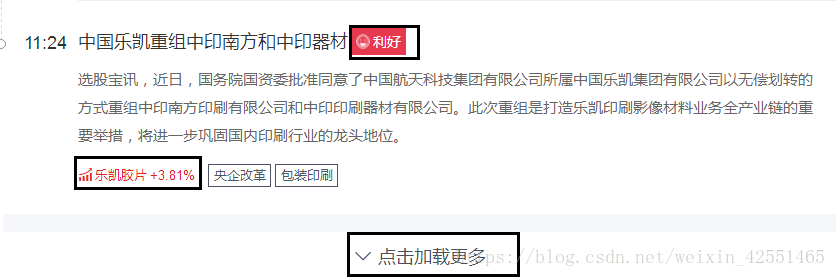
(2)网页分析(selenium有很多定位方法,这里用到比较少)
在上面的代码中,data已经拥有了网页当前页的所有内容(可输出观察);我们现在只要从中拿到我们想要的数据
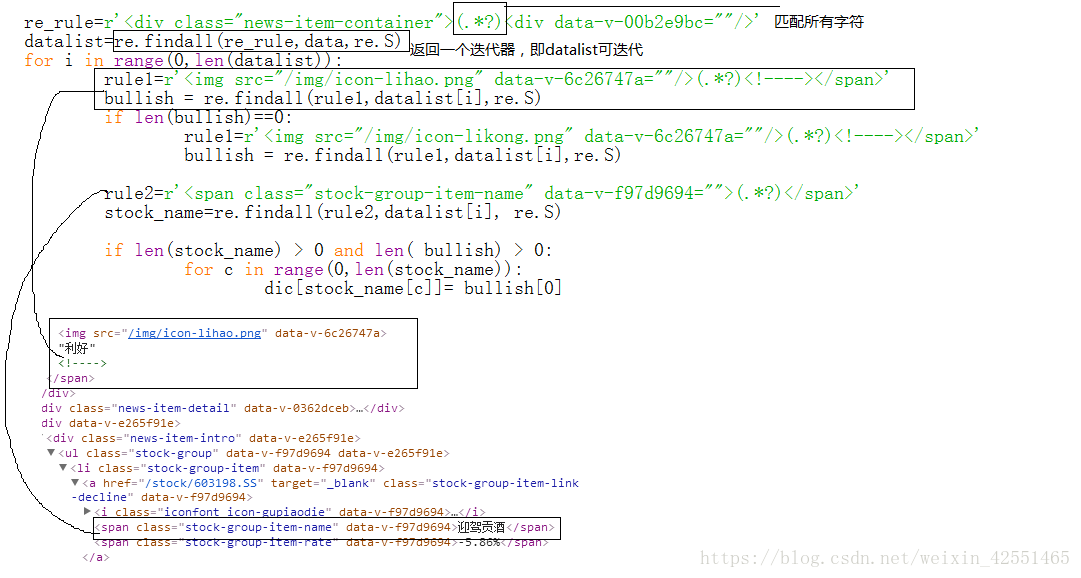
在网页中,右键,审查元素,(或者检查)分析网页:(由于得到的data可能与网页的分析有所出入,建议最好输出data,从data中分析得到正则表达式)
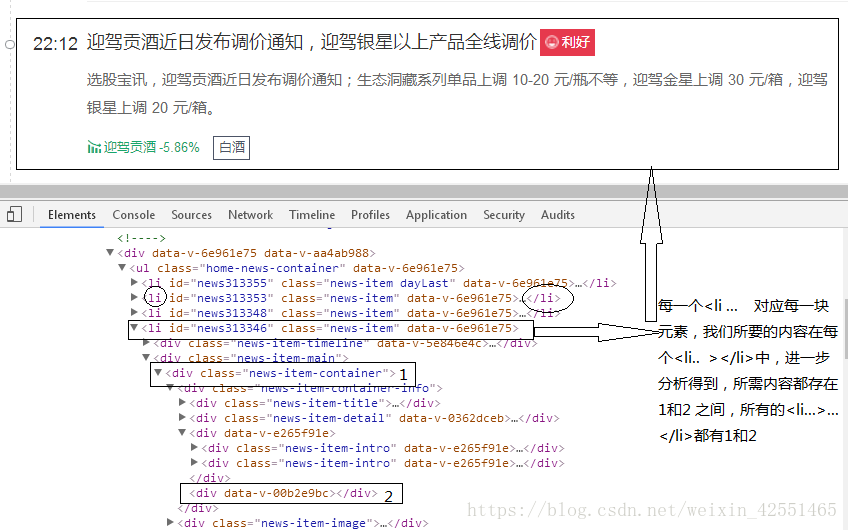
我们用正则表达式找到所有以1开头,以2为结尾内容用findall函数
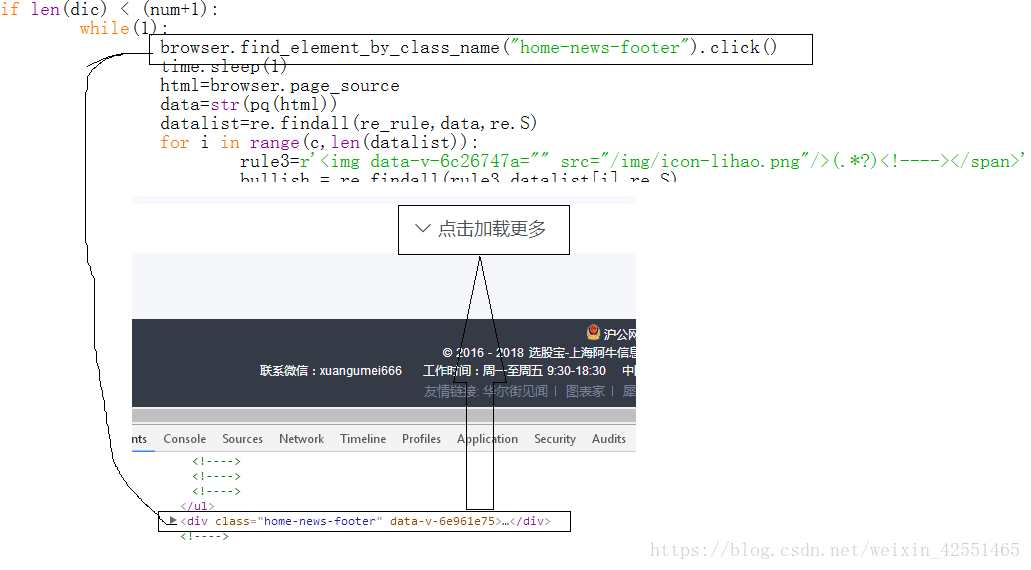
实现点击:(点击之后的”利好”和“相关股票”的正则会与首页的不同(后面点击的与第一次点击后的一样))
定位方法有:(这里用的比较少不做详细介绍,大家自行了解):
find_element_by_id 当你知道一个元素的id属性时使用它。使用此策略,将返回具有与该位置匹配的id属性值的第一个元素。
find_element_by_name 当你知道一个元素的name属性时使用它。使用此策略,将返回具有与该位置匹配的id属性值的第一个元素。
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
源码附上:
#coding=utf-8
from selenium import webdriver
import time
import re
from pyquery import PyQuery as pq
def openurl(url,num):
browser = webdriver.Chrome() #打开浏览器
browser.get(url) #进入相关网站
html=browser.page_source #获取网站源码
data=str(pq(html)) #str() 函数将对象转化为适于人阅读的形式。
dic={}
re_rule=r'<div class="news-item-container">(.*?)<div data-v-00b2e9bc=""/>'
datalist=re.findall(re_rule,data,re.S)
for i in range(0,len(datalist)):
rule1=r'<img src="/img/icon-lihao.png" data-v-6c26747a=""/>(.*?)<!----></span>'
bullish = re.findall(rule1,datalist[i],re.S)
if len(bullish)==0:
rule1=r'<img src="/img/icon-likong.png" data-v-6c26747a=""/>(.*?)</span>'
bullish = re.findall(rule1,datalist[i],re.S)
rule2=r'<span class="stock-group-item-name" data-v-f97d9694="">(.*?)</span>'
stock_name=re.findall(rule2,datalist[i], re.S)
if len(stock_name) > 0 and len( bullish) > 0:
for c in range(0,len(stock_name)):
dic[stock_name[c]]= bullish[0]
print("正在爬取第",len(dic)+1,"个请稍等.....")
c=len(datalist)
if len(dic) < num:
while(1):
browser.find_element_by_class_name("home-news-footer").click()
time.sleep(1)
html=browser.page_source
data=str(pq(html))
datalist=re.findall(re_rule,data,re.S)
for i in range(c,len(datalist)):
rule3=r'<img data-v-6c26747a="" src="/img/icon-lihao.png"/>(.*?)<!----></span>'
bullish = re.findall(rule3,datalist[i],re.S)
if len(bullish)==0:
rule5=r'<img data-v-6c26747a="" src="/img/icon-likong.png"/>(.*?)</span>'
bullish = re.findall(rule5,datalist[i],re.S)
rule4=r'<span data-v-f97d9694="" class="stock-group-item-name">(.*?)</span>'
stock_name=re.findall(rule4,datalist[i], re.S)
if len(stock_name) > 0 and len( bullish) > 0:
for c in range(0,len(stock_name)):
dic[stock_name[c]]= bullish[0]
c=len(datalist)
if len(dic) > num :
browser.quit()
print("爬取完毕!!")
break
print("正在爬取第",len(dic)+1,"个请稍等.....")
else:
browser.quit()
print("爬取完毕!!")
return dic
url='https://www.xuangubao.cn/'
dict=openurl(url,3)
print(dict)
#f=open("F:\\text.txt","a")
#for key,values in dict.items():
#f.write((key+"\t"))
#print(key,values)
#f.close()
---------------------
原文:https://blog.csdn.net/weixin_42551465/article/details/80817552