网页分析
首先来看下要爬取的网站的页面
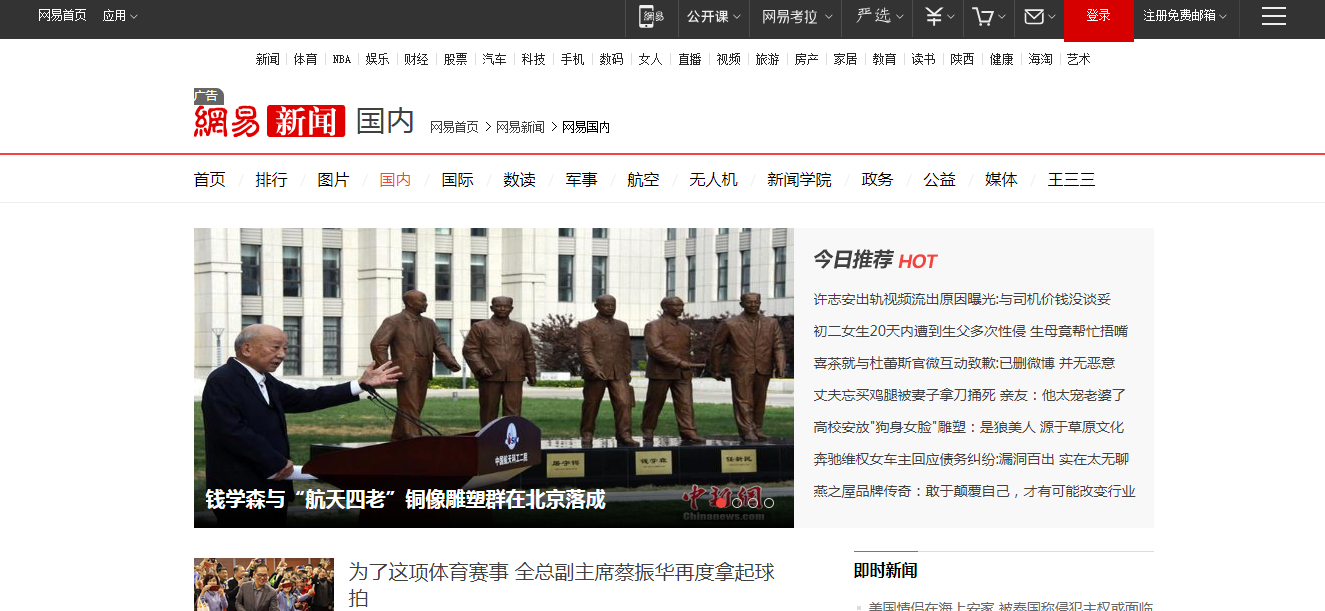
查看网页源代码:你会发现它是由js动态加载显示的
所以采用selenium+谷歌无头浏览器来爬取它
1 加载网站,并拖动到底,发现其还有个加载更多
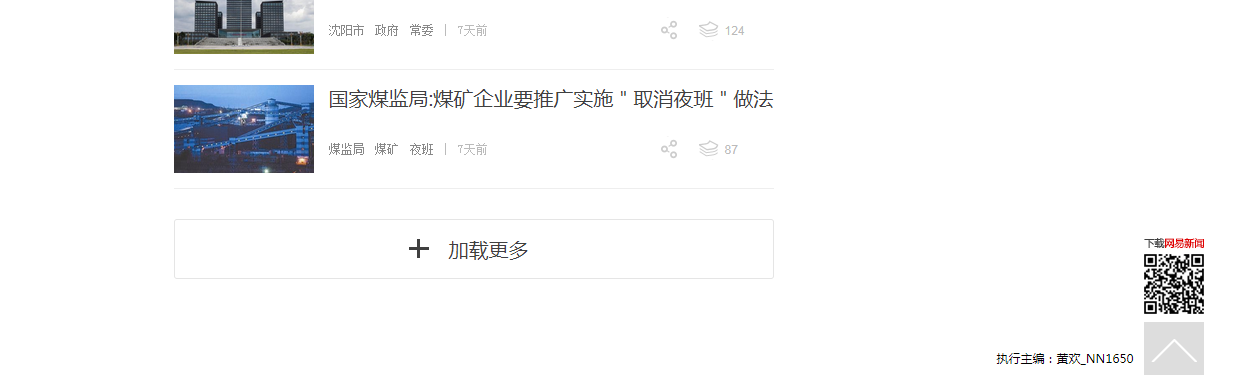
2 模拟点击它,然后再次拖动到底,,就可以加载完整个页面
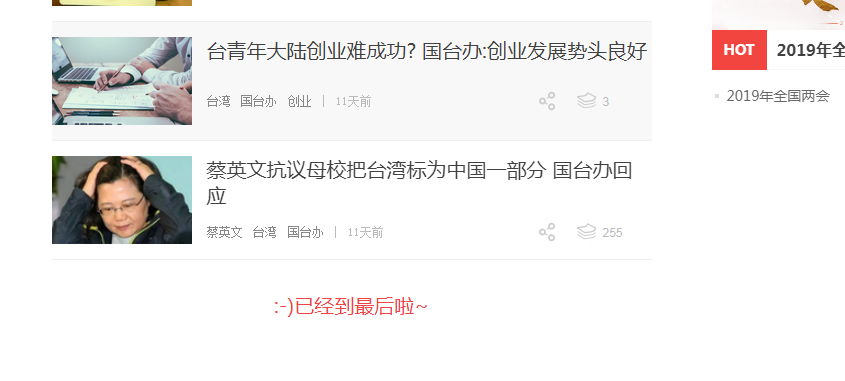
示例代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from time import sleep
from lxml import etree
import os
import requests
# 使用谷歌无头浏览器来加载动态js
def main():
# 创建一个无头浏览器对象
chrome_options = Options()
# 设置它为无框模式
chrome_options.add_argument('--headless')
# 如果在windows上运行需要加代码
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
# 设置一个10秒的隐式等待
browser.implicitly_wait(10)
browser.get(url)
sleep(1)
# 翻到页底
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 点击加载更多
browser.find_element(By.CSS_SELECTOR, '.load_more_btn').click()
sleep(1)
# 再次翻页到底
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 拿到页面源代码
source = browser.page_source
browser.quit()
with open('xinwen.html', 'w', encoding='utf-8') as f:
f.write(source)
parse_page(source)
# 对新闻列表页面进行解析
def parse_page(html):
# 创建etree对象
tree = etree.HTML(html)
new_lst = tree.xpath('//div[@class="ndi_main"]/div')
for one_new in new_lst:
title = one_new.xpath('.//div[@class="news_title"]/h3/a/text()')[0]
link = one_new.xpath('.//div[@class="news_title"]/h3/a/@href')[0]
write_in(title, link)
# 将其写入到文件
def write_in(title, link):
print('开始写入篇新闻{}'.format(title))
response = requests.get(url=link, headers=headers)
tree = etree.HTML(response.text)
content_lst = tree.xpath('//div[@class="post_text"]//p')
title = title.replace('?', '')
with open('new/' + title + '.txt', 'a+', encoding='utf-8') as f:
for one_content in content_lst:
if one_content.text:
con = one_content.text.strip()
f.write(con + '\n')
if __name__ == '__main__':
url = 'https://news.163.com/domestic/'
headers = {"User-Agent": 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0'}
if not os.path.exists('new'):
os.mkdir('new')
main()
得到结果:
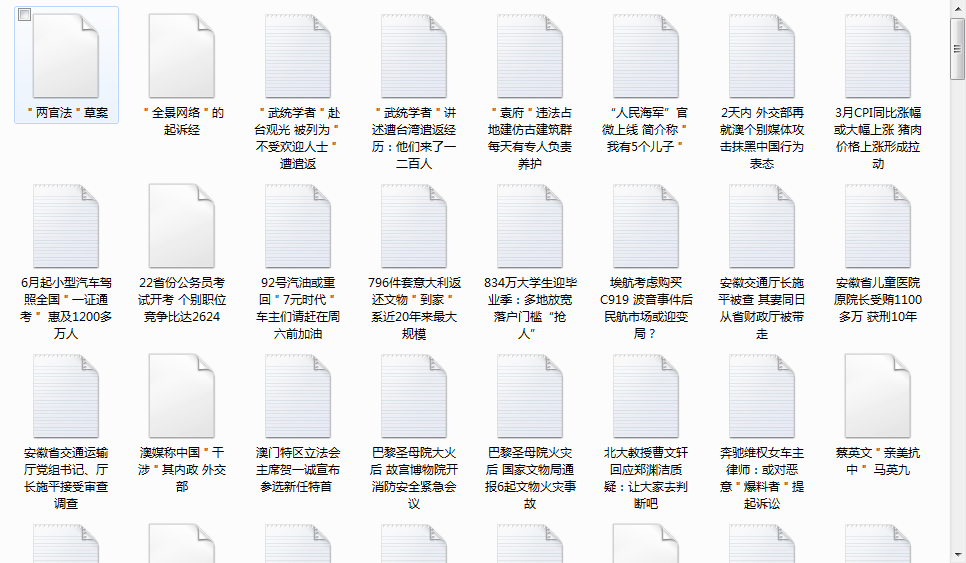
随意打开一个txt:

总结:
1 其实主要的工作还是模拟浏览器来进行操作。
2 处理动态的js其实还有其他办法。
3 爬虫的方法有好多种,主要还是选择适合自己的。
4 自己的代码写的太烂了。