基本流程
- 获取流的执行环境;
- 设定数据源source;
- 设定operator/数据转换;
- 设定sink;
- 执行程序;
获取流的执行环境
API获取
自动根据程序的所处的上线文环境创建合适的执行环境:本地执行环境或者以客户端的形式提交到远程服务端执行;
StreamExecutionEnvironment.getExecutionEnvironment()
Typically, you only need to use getExecutionEnvironment(), since this will do the right thing depending on the context: if you are executing your program inside an IDE or as a regular Java program it will create a local environment that will execute your program on your local machine. If you created a JAR file from your program, and invoke it through the command line, the Flink cluster manager will execute your main method and getExecutionEnvironment() will return an execution environment for executing your program on a cluster.
环境区分
通过判断contextEnvironmentFactory是否为空判断,如果contextEnvironmentFactory为空则创建本地执行环境,否则提交到cluster;
/**
* Creates an execution environment that represents the context in which the program is currently executed.
* If the program is invoked standalone, this method returns a local execution environment, as returned by
* {@link #createLocalEnvironment()}. If the program is invoked from within the command line client to be
* submitted to a cluster, this method returns the execution environment of this cluster.
*
* @return The execution environment of the context in which the program is executed.
*/
public static ExecutionEnvironment getExecutionEnvironment() {
return contextEnvironmentFactory == null ?
createLocalEnvironment() : contextEnvironmentFactory.createExecutionEnvironment();
}
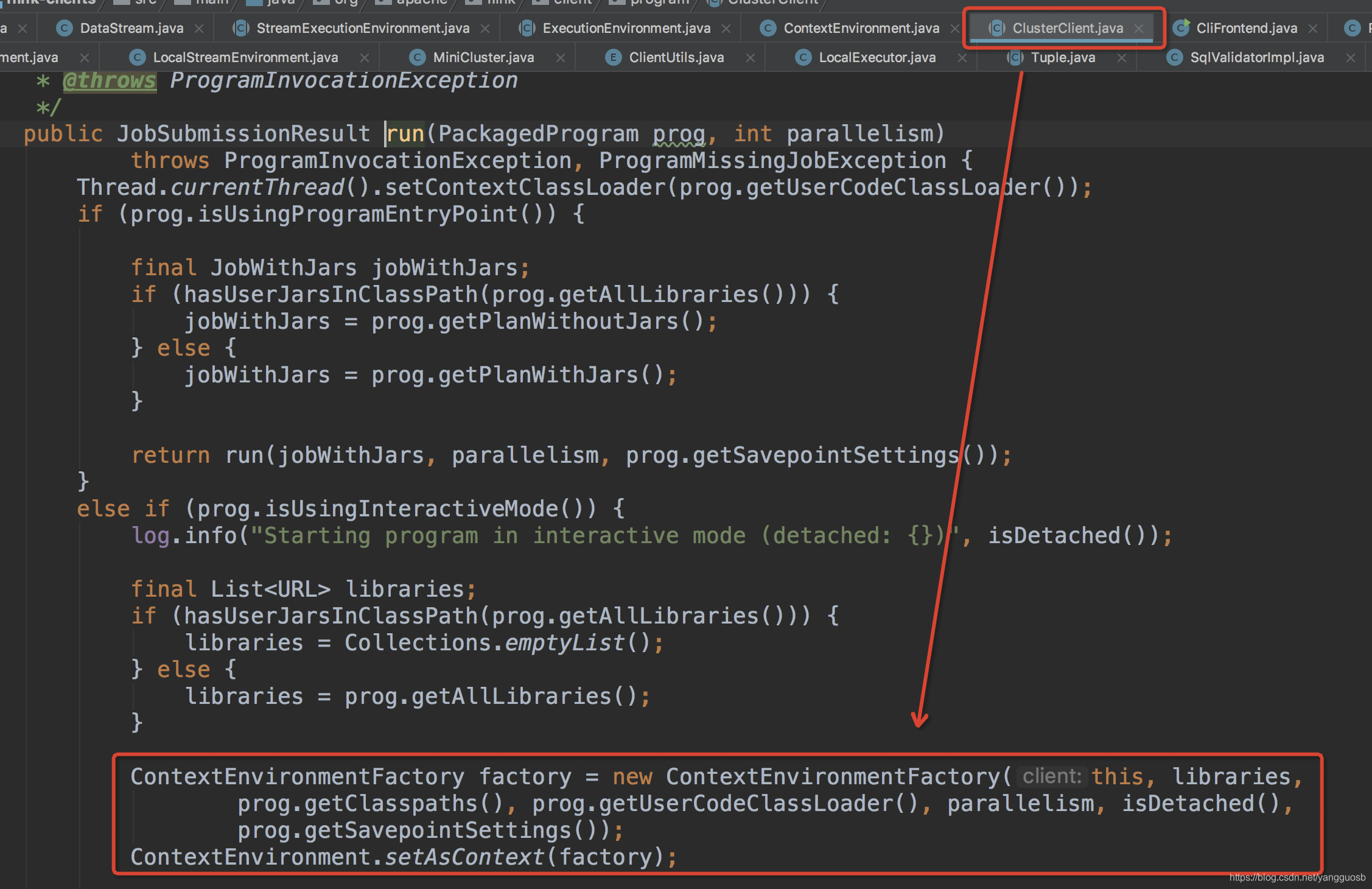
ExecutionEnvironmentFactory 初始化过程
- 执行终端命令提交jar包
./bin/flink run *.jar [参数]
- 终端命令中执行java命令,CliFrontend为执行类

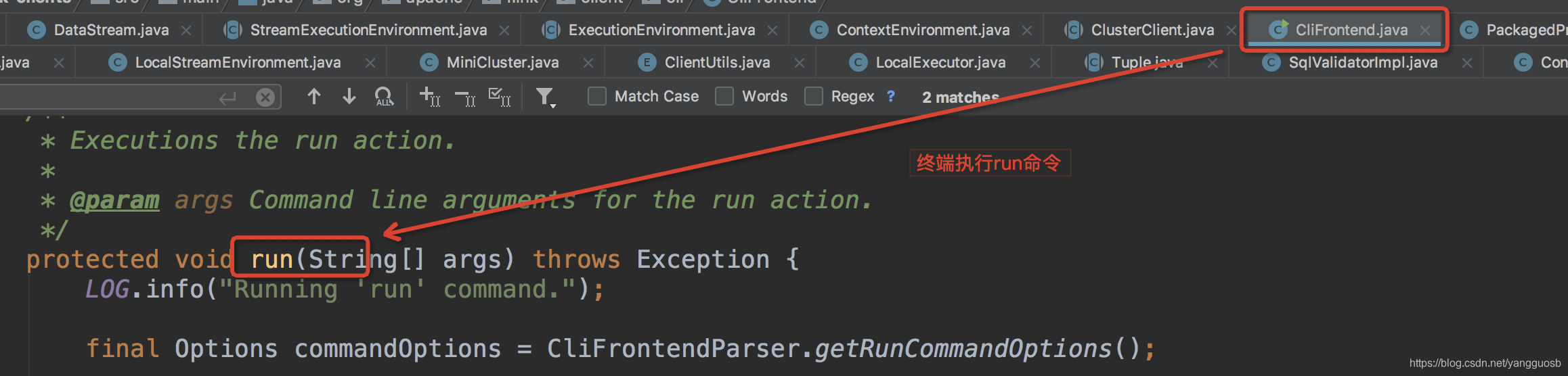
- 触发ClusterClient的run方法初始化ExecutionEnvironmentFactory
Source设定
Flink的数据源支持多种形式,使用见官网:
- 文件
- 集合
- Socket
- 第三方数据源(比如Kafka、ES、MQ等)
设定方式:直接调用StreamExecutionEnvironment的readTextFile、fromCollection、socketTextStream、addSource等方法即可;
For specifying data sources the execution environment has several methods to read from files using various methods: you can just read them line by line, as CSV files, or using completely custom data input formats.
Sink设定
- 文件
- 终端
- Socket
- 第三方数据源(比如Kafka、ES、MQ等)
Operators
- Map(DataStream → DataStream):输入一个元素,产出一个元素;
- FlatMap(DataStream → DataStream):输入一个元素,产出多个元素;
- Filter(DataStream → DataStream):对元素进行过滤,表达式为true则保留,否则过滤掉;
- KeyBy(DataStream → KeyedStream):按照元素的key生成哈希值,然后分区;

更多查看官网
参考: