Flink-sink的种类和基本使用
flink中的sink相当于spark中的action,是划分subTask的重要依据之一。
PrintSink编号问题
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> streamSource = environment.socketTextStream("test130", 8888);
streamSource.print("result:").setParallelism(2);
environment.execute("PrintSink");
}
测试:终端输入abababab
结果:
result::2> b
result::1> a
result::2> b
result::1> a
result::2> b
1.前缀result就是在print里面设置的。
2.前面的编号(也就是subTask的Id)在1和2之间来回切换(由于setParallelism(2))
3.Print这个sink是可以设置并行度的,也就是说明他是并行Sink。
4.首先需要说明的是,flink的subTask的编号是从0开始的,而我们设置的并行度为2.按理来说,前面的编号应该为1和0,为何是1和2呢?
答案:
在ES源码当中,一个叫PrintSinkOutputWriter:
部分方法如下:
public void open(int subtaskIndex, int numParallelSubtasks) {
this.stream = !this.target ? System.out : System.err;
this.completedPrefix = this.sinkIdentifier;
if (numParallelSubtasks > 1) {
if (!this.completedPrefix.isEmpty()) {
this.completedPrefix = this.completedPrefix + ":";
}
// 输出的结果在原来基础上+1了
this.completedPrefix = this.completedPrefix + (subtaskIndex + 1);
}
// 因此为何我们输出的结果有这个 > 的符号
if (!this.completedPrefix.isEmpty()) {
this.completedPrefix = this.completedPrefix + "> ";
}
}
这代码解释了为何我们用prinit()方法的时候输出的结果是这样的:
[subTaskId+1] > value
默认输出模板:
2> b
1> a
2> b
1> a
2> b
1> a
addSink的使用(自定义Sink)
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> streamSource = environment.socketTextStream("test130", 8888);
SingleOutputStreamOperator<Tuple2<String, Integer>> flatMap = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
Tuple2<String, Integer> of = Tuple2.of(word, 1);
out.collect(of);
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = flatMap.keyBy(0).sum(1);
sum.addSink(new RichSinkFunction<Tuple2<String, Integer>>() {
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
// 获取index
int index = getRuntimeContext().getIndexOfThisSubtask();
System.out.println("自定义Sink:" + index + "->" + value);
}
});
environment.execute("AddSink");
}
终端打开8888端口并输入:
nc -lk 8888
flink spark spark
结果:
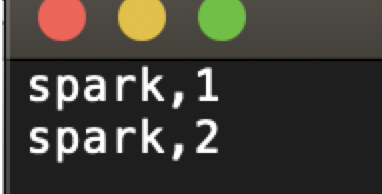
自定义sink: 0 ->(spark,1)
自定义sink: 6 ->(flink,1)
自定义sink: 0 ->(spark,2)
注意:
如果在自定义Sink中需要获取subTask的Id的话,内部实现类必须是RichSinkFunction,否则不支持
int index = getRuntimeContext().getIndexOfThisSubtask();
csvSink的使用
首先大家需要注意的地方:
看下源码: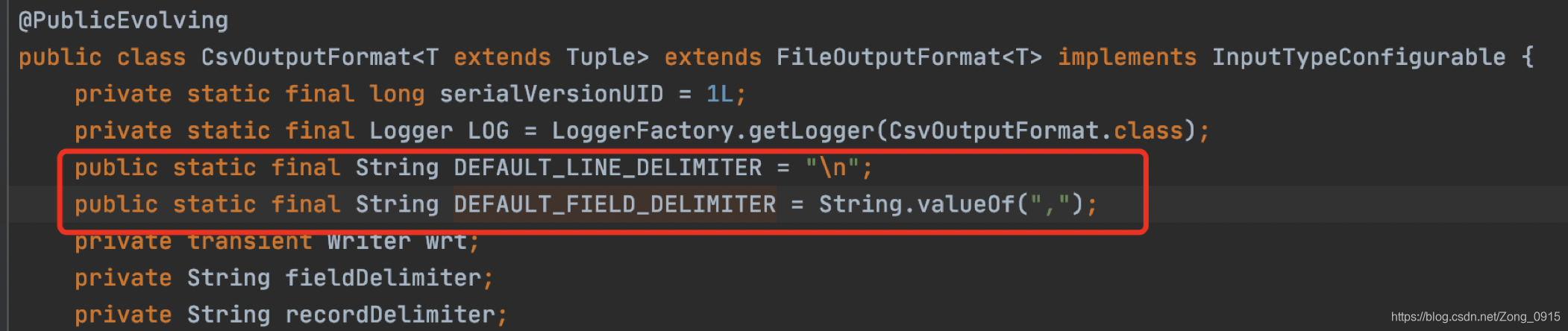
这个内部实现:
- 默认行的分隔符是回车
- 字符串之间的分隔符是逗号
测试代码:
如果我在终端输入一些文字后:
我的文件输出路径会多出一个out2的文件夹,但是此时的大小都是0,为什么呢?如图: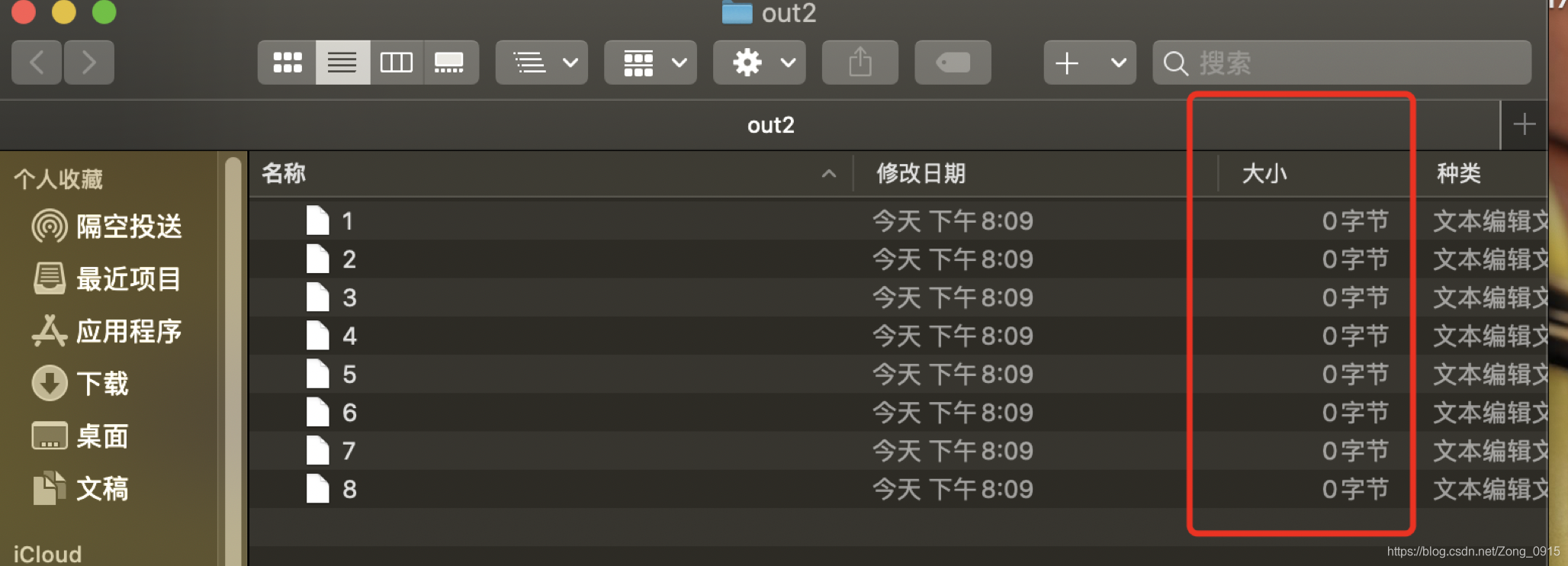
查看源码:
其中一个类叫做 :CsvOutputFormat,贴出部分代码
public void open(int taskNumber, int numTasks) throws IOException {
super.open(taskNumber, numTasks);
this.wrt = this.charsetName == null ? new OutputStreamWriter(new BufferedOutputStream(this.stream, 4096)) : new OutputStreamWriter(new BufferedOutputStream(this.stream, 4096), this.charsetName);
}
可以看到这里有个4096的数字。
意思是,只有文件大小超过4096,那么程序才会启动一次flush,将数据写入文件。因此我们写入的数据太少的情况下,达不到4096的限制,因此不会flush操作,输出的文件内容为空。
因此我们可以通过以下方案进行操作:
- 让终端的8888端口断开。
- 那么程序会进入一个收尾工作,出现异常,进行一次flush。将数据写入到文件当中。
- 断开终端后,打印台会出现提示
此时目标文件夹发生了变化:

数据内容: