目录
1. flink-conf.yaml,修改jobManager
4.3.5 任务(Tasks)和任务槽(Task Slots)
一、简介
1.1 flink是什么
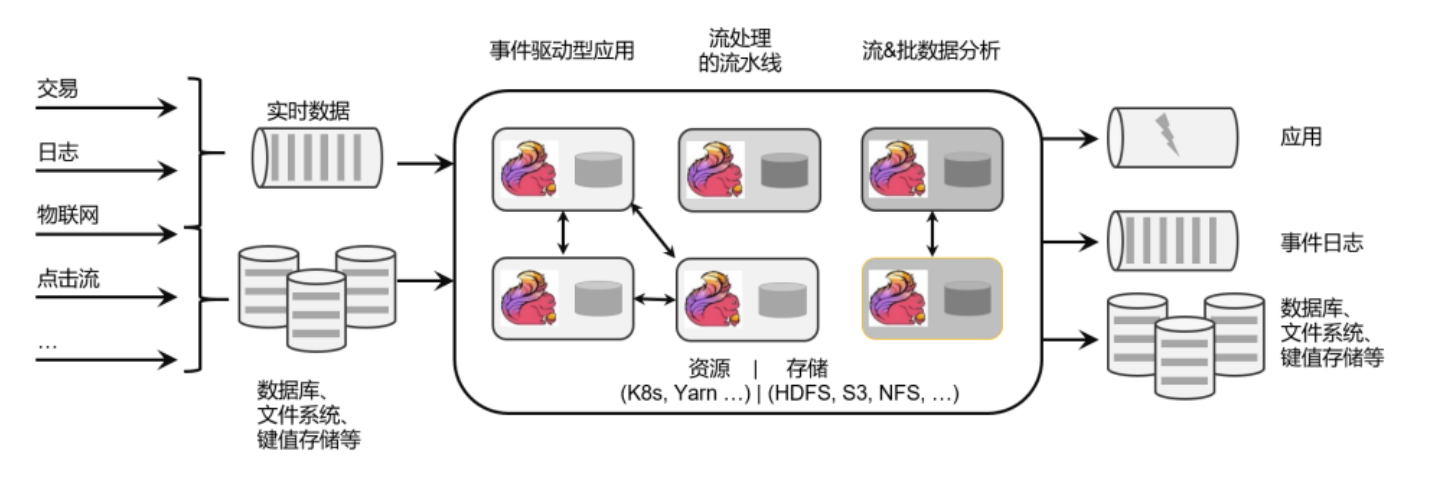
apache flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
1.2 flink主要特点
类似于一个管道,数据处理完了之后能够及时输出,flink主要应用场景就是处理大规模的数据流。
核心特性:
1、高吞吐、低延迟,每秒处理百万个事件,毫秒级延迟
2、 结果的准确性。flink提供了事件时间(event-time)和处理时间(processing-time)。对于乱序事件流,事件事件语义仍然能提供一致且准确的结果。
3、 精确一次(ecatly-once)的状态一致性保证
4、 可以与常用存储系统连接。
5、 高可用,支持动态扩展
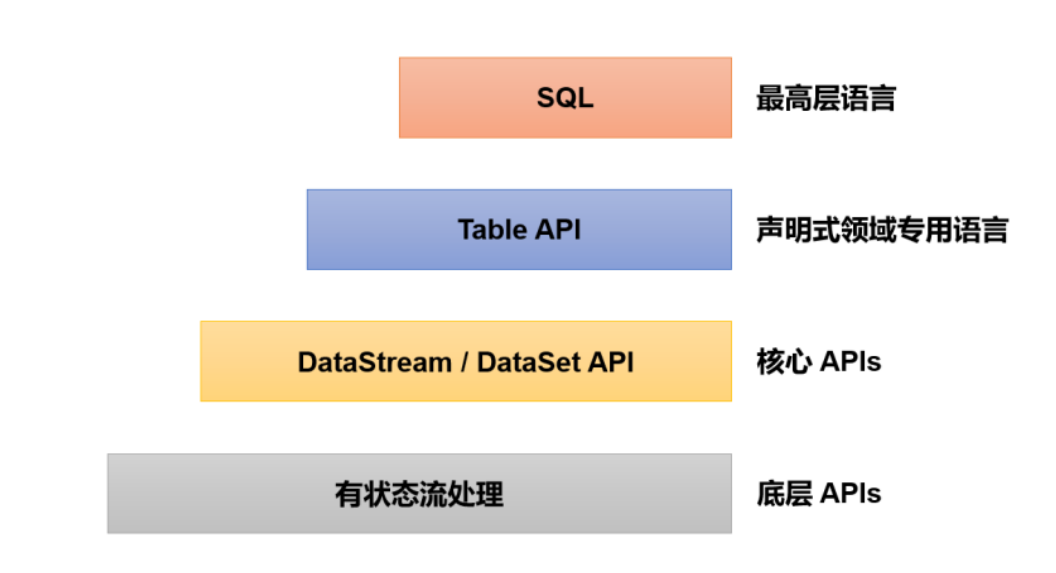
分层API:
约顶层越抽象,表达含义越简明,使用越方便
约底层越具体,表达含义越丰富,使用越灵活
1.3 flink vs spark
1.3.1 数据处理框架

1.3.2 数据模型
Spark采用RDD模型,spark streaming的DStream实际上也是一组组小批数据RDD的集合
flink基本数据模型是数据流,以及事件event序列
1.3.3 运行时架构
spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个
flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
二、wordcount实例
2.1 项目依赖
<properties>
<flink.version>1.13.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
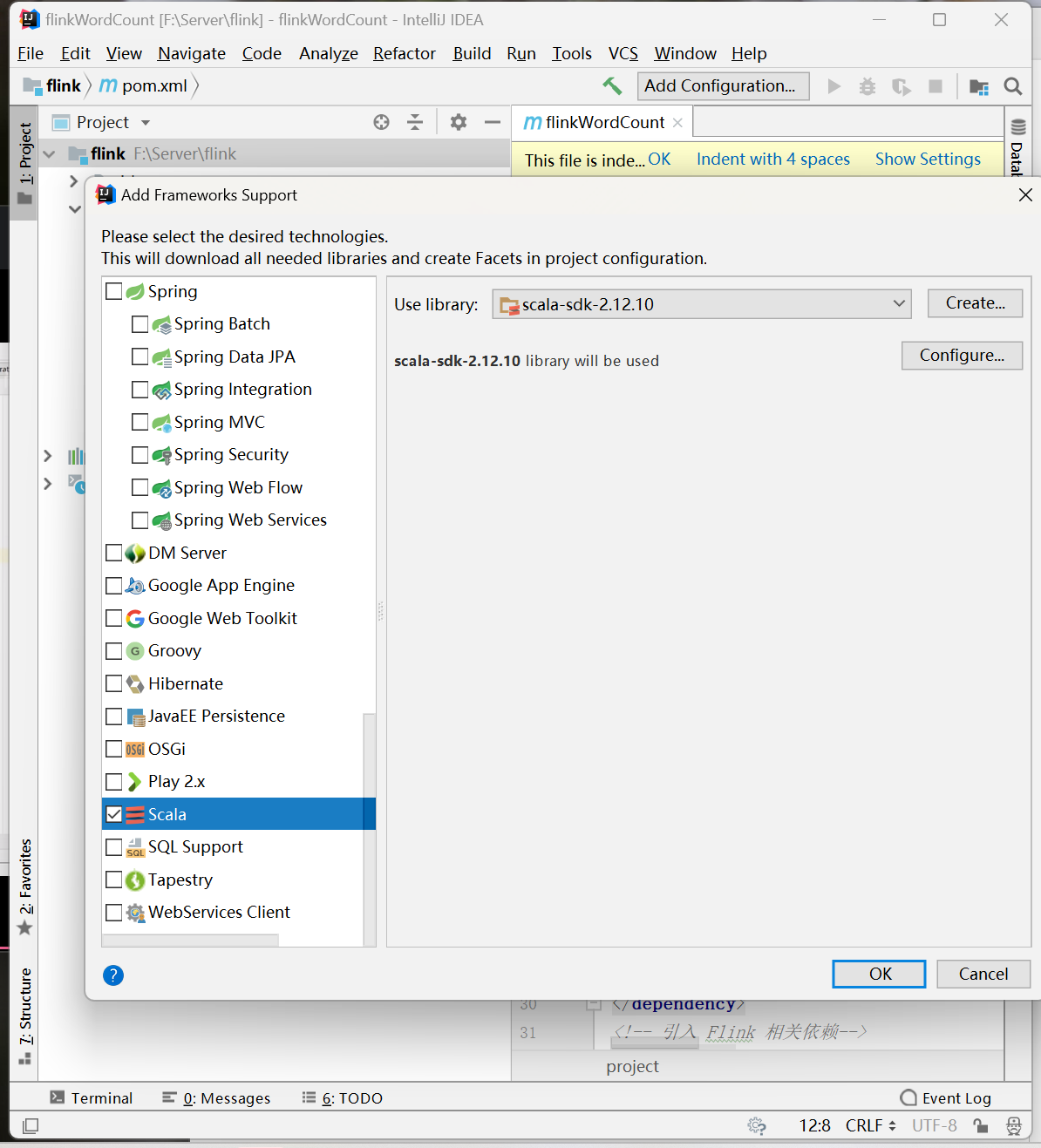
</dependencies>2.2 添加框架支持
2.3 批处理 - DataSet API
执行环境:ExecutionEnvironment
package org.example.cp2
import org.apache.flink.api.scala._
object BatchWordCount {
def main(args: Array[String]): Unit = {
// 1. 创建一个执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 读取文本文件数据
val lineDataSet: DataSet[String] = env.readTextFile("input/word.txt")
// 3. 对数据集进行转换处理
val wordAndOne: DataSet[(String, Int)] = lineDataSet.flatMap(_.split(" ")).map(x=>(x,1))
// 4. 按照单词进行转换处理
val wordAndOneGroup: GroupedDataSet[(String, Int)] = wordAndOne.groupBy(0)
// 5. 对分组数据进行sum聚合统计
val sum: AggregateDataSet[(String, Int)] = wordAndOneGroup.sum(1)
// 6. 打印输出
sum.print()
}
}

这里需要导入 import org.apache.flink.api.scala._,否则会报下面的异常。
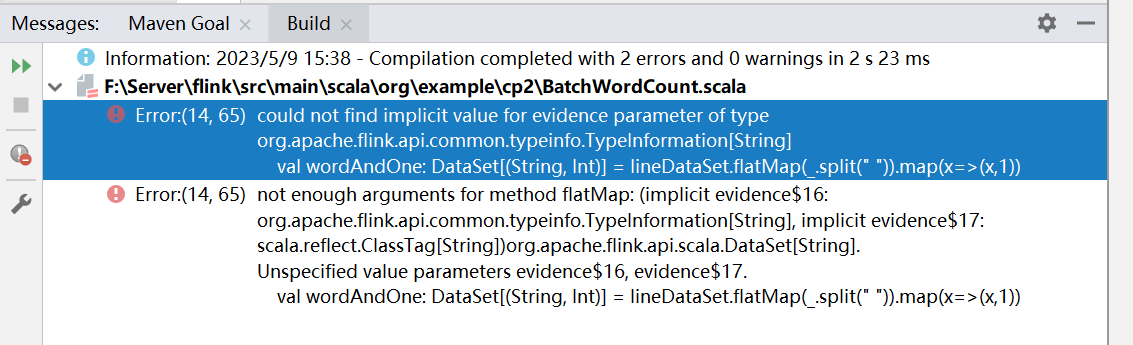
需要注意的是,这种代码的实现方式是基于 DataSet API 的。也就是说,是把对数据的处理转换看作数据集来进行操作的。flink是一种流、批一体的处理架构,对于数据批量处理的时候底层也是数据流,所以没有必要使用 DataSet API 去进行特别的处理。
所以官方推荐的用法是直接使用 DataStream API ,在提交任务的时候通过将执行模式设为 BATCH 来进行批处理。
2.4 有界流处理wordcount
使用环境:
流处理:StreamExecutionEnvironment ,
批处理:ExecutionEnvironment 。
package org.example.cp2
import org.apache.flink.api.scala.{AggregateDataSet, DataSet, GroupedDataSet}
import org.apache.flink.streaming.api.scala._
object BoundedStreamWordCount {
def main(args: Array[String]): Unit = {
// 1. 创建一个流式执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 读取文本文件数据
val lineDataStream: DataStream[String] = env.readTextFile("input/word.txt")
// 3. 对数据集进行转换处理
val wordAndOne = lineDataStream.flatMap(_.split(" ")).map(x=>(x,1))
// 4. 按照单词进行转换处理
// 与批处理不同,流式处理没有groupBy(),我们这里采用keyBy()
val wordAndOneGroup = wordAndOne.keyBy(_._1)
// 5. 对分组数据进行sum聚合统计
val sum = wordAndOneGroup.sum(1)
// 6. 打印输出
sum.print()
// 执行任务,等待数据的流入
env.execute()
}
}

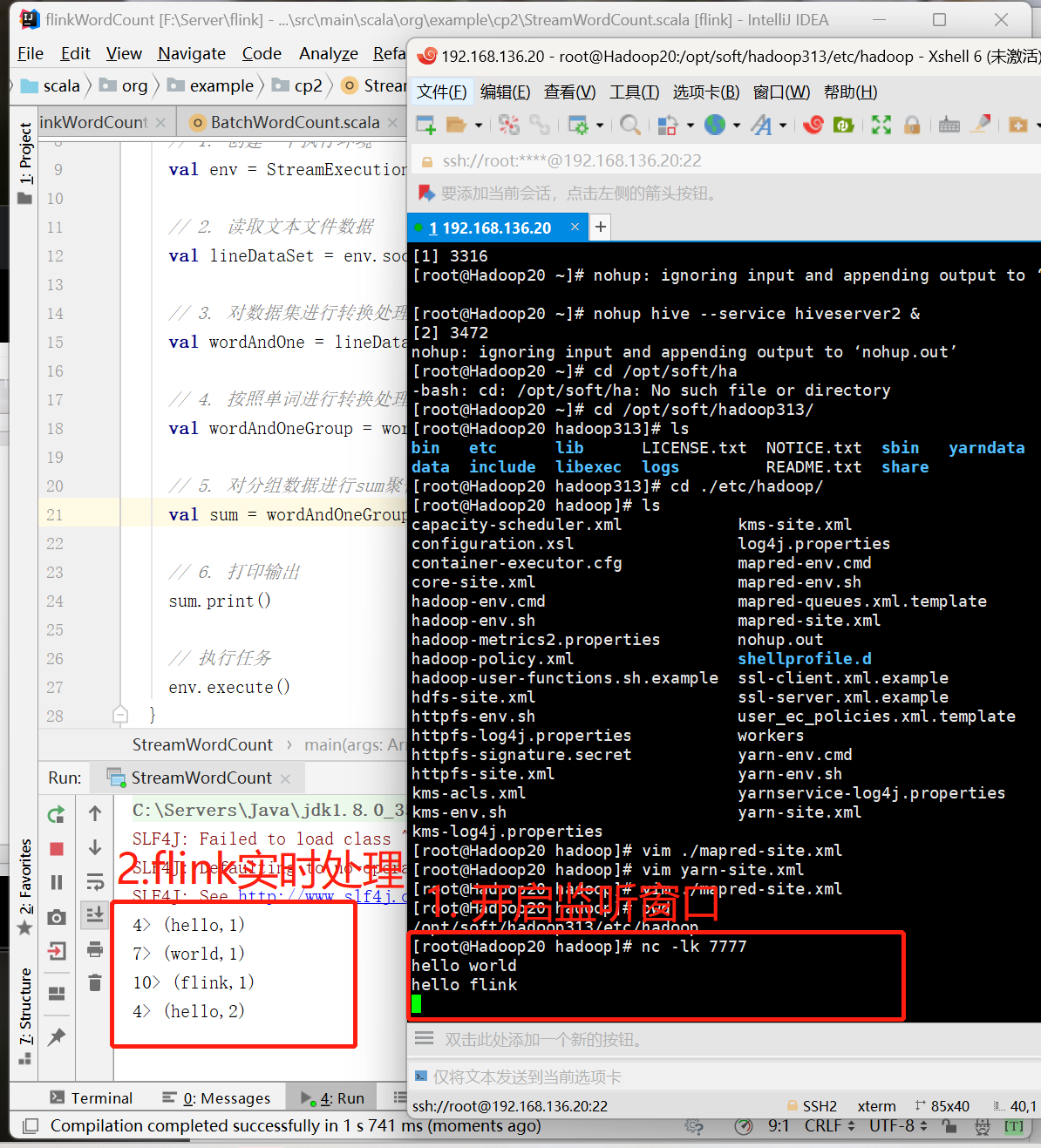
我们这里可以看到,hello 出现了3次,每来一次都会处理一次。对于前面的数字,我们可以理解成不同的线程在并行的执行,前面的数字为并行的编号。
2.5 无界流处理wordcount
执行API
package org.example.cp2
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 1. 创建一个执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 读取文本文件数据
val lineDataSet = env.socketTextStream("192.168.136.20",7777)
// 3. 对数据集进行转换处理
val wordAndOne = lineDataSet.flatMap(_.split(" ")).map(x=>(x,1))
// 4. 按照单词进行转换处理
val wordAndOneGroup = wordAndOne.keyBy(_._1)
// 5. 对分组数据进行sum聚合统计
val sum = wordAndOneGroup.sum(1)
// 6. 打印输出
sum.print()
// 执行任务
env.execute()
}
}
程序启动之后没有任何输出, 也不会退出。这是由于flink的流处理是事件驱动的,当前程序会一直处于监听状态。只有接收到数据才会执行任务、输出统计结果。
主机192.168.136.20
[root@Hadoop20 hadoop]# nc -lk 7777输出的结果和读取文件的流处理十分相似。每输入一条数据,就有一次对应的输出。这里的数字表示的是线程数,默认为CPU的核数。当输入的数据足够多的时候,从1-12所有的核数都会占据。
监听的端口不会写死, 可以将主机名和端口号配置在外面。在flink代码中有 parameterTool 工具用来读取。
配置端口
--host 192.168.136.20 --port 7777
// 固定端口
val lineDataSet = env.socketTextStream("192.168.136.20",7777)
// 配置端口
val parameterTool = ParameterTool.fromArgs(args)
val hostname = parameterTool.get("host")
val port = parameterTool.getInt("port")
val lineDataStream = env.socketTextStream(hostname,port)三、Flink部署
3.1 flink集群中的主要组件
包括客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。代码编写完之后,由客户端获取并做转换,发送给JobManager,也就是Flink集群的管理者,对作业进行中央调度管理。对作业进行转换后,将任务分发给众多的TaskManager,由TaskManager对数据进行实际的处理。
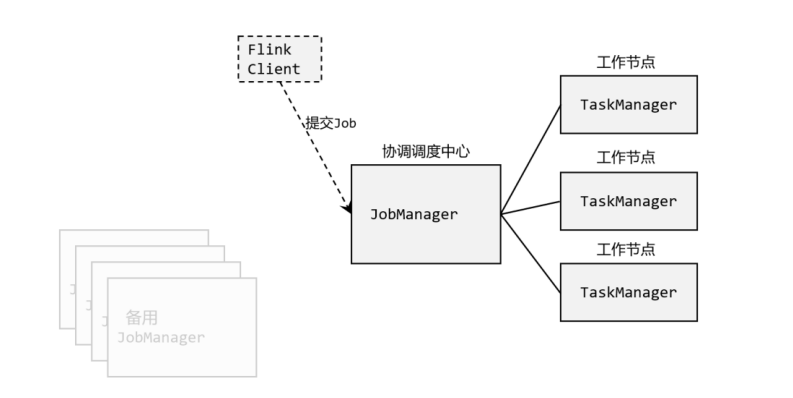
详细流程:

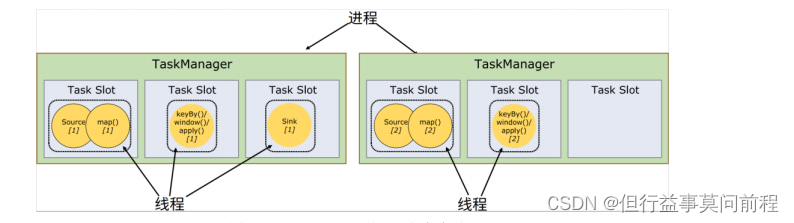
重要概念:
Client:
flink用来提交任务的客户端,命令行提交,Web页面提交。
JobManager处理器:
协调分布式执行。用来调度task,协调检查点,协调失败时恢复。
TaskManager处理器:
用于执行一个 dataFlow 的 task(或特殊的 subtask )、数据缓冲和 data stream的交换。
Slot任务执行槽位:
一个 TaskManager 内会划分多个Slot。一个 Slot 内最多可以运行一个 Task 或 一个组由 Task 组成的任务链。
Task任务:
每一个 Flink 的 Job 会根据情况(并行度、算子链类型)将一个整体的 Job 划分为多个Task。
Subtask子任务:
一个 Task 有多少个 Subtask 取决于这个 Task 的并行度。也就是,每一个 Subtask 就是当前 Task 任务并行的一个线程。
并行度:
一个 Task 可以获得的最大并行度取决于整个 Flink 环境的可用 Slot 数量
State:
Flink 运行过程中的中间结果。
3.2 本地启动flink
1. 启动
[root@Hadoop20 flink113]# ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host Hadoop20.
Starting taskexecutor daemon on host Hadoop20.
[root@Hadoop20 flink113]# jps
18096 Jps
2948 NodeManager
17700 StandaloneSessionClusterEntrypoint
2117 NameNode
2773 ResourceManager
3445 RunJar
3319 RunJar
17975 TaskManagerRunner
2284 DataNode
2. 访问Web UI
启动成功后,访问192.168.136.20:8081,可以对flink集群和任务进行监控管理。
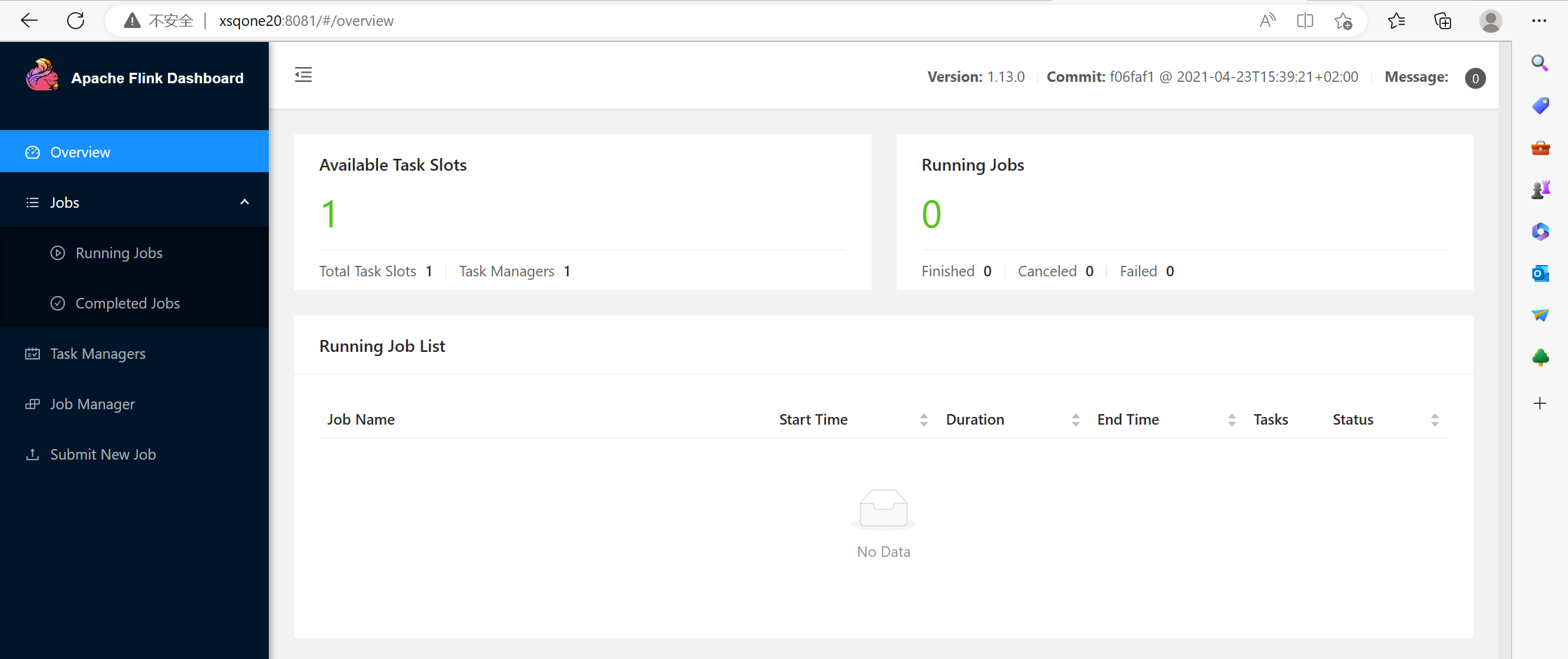
3. 关闭flink
[root@Hadoop20 flink113]# ./bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 17975) on host Hadoop20.
Stopping standalonesession daemon (pid: 17700) on host Hadoop20.
3.3 集群启动
启动的命令和配置没有变化,需要对主从关系 masters 和 workers 进行配置。
1. flink-conf.yaml,修改jobManager
[root@Hadoop20 flink113]# cd ./conf/
[root@Hadoop20 conf]# vim flink-conf.yaml
// 修改本机地址
jobmanager.rpc.address: 192.168.136.202. masters和worker
[root@Hadoop20 conf]# vim masters
192.168.136.20:8081
[root@Hadoop20 conf]# vim workers
192.168.136.21
192.168.136.22
3. 分发安装目录
$ scp -r ./flink-1.13.0 root@xsqone21:/opt/module
$ scp -r ./flink-1.13.0 root@xsqone22:/opt/module4. 启动集群
[root@Hadoop20 flink113]# ./bin/start-cluster.sh 3.4 向集群提交作业
IDEA中的默认的打包对scala代码打包效果不是很好,所以会引入打包插件。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>1. webUI提交作业
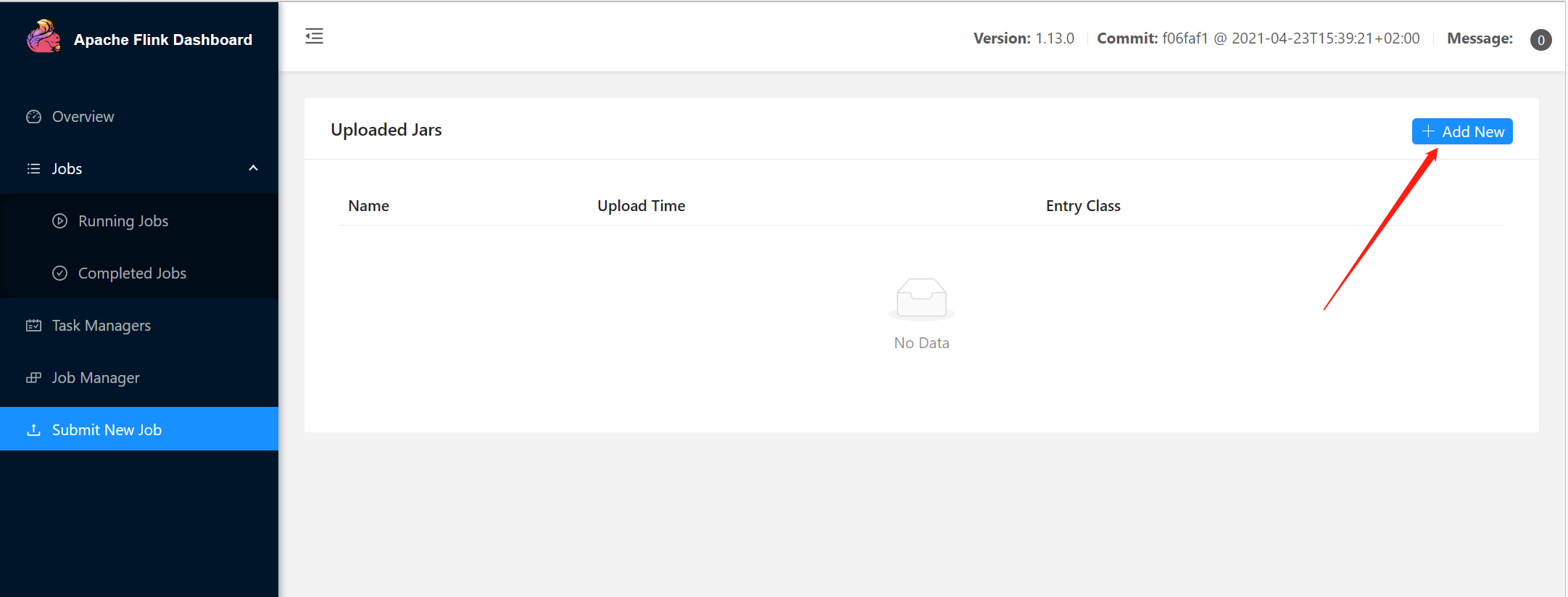
2. 命令行提交作业
上传jar包
[root@Hadoop20 flink113]# ./bin/flink run -m 192.168.136.20:8081 -c org.example.cp2.StreamWordCount -p 2 ./FlinkTutorial-1.0-SNAPSHOT.jar --host 192.168.136.20 --port 77771. 查看当前运行的作业
[root@Hadoop20 flink113]# ./bin/flink list
Waiting for response...
No running jobs.
No scheduled jobs.
2. 查看所有的运行作业
[root@Hadoop20 flink113]# ./bin/flink list -a
Waiting for response...
No running jobs.
No scheduled jobs.
3. 取消当前作业
[root@Hadoop20 flink113]# ./bin/flink cancel [jobID]
3.5 部署模式
flink主要有三种部署模式:会话模式、单作业模式、应用模式。
会话模式:
先启动一个集群,保持一个会话。在这个会话中通过客户端提交作业。集群启动时所有资源都已经确定,所有提交的作业会竞争集群中的资源。
会话模式适合单个规模小、执行时间短的大量作业。
单作业模式:
会话模式因为资源共享会导致很多问题。为了隔离资源,为每个提交的作业启动一个集群,就是单作业模式。
单作业模式无法直接启动,需要借助一些资源管理平台来启动集群,如yarn。
应用模式:
不管是会话模式还是单作业模式,应用代码都是在客户端执行,由客户端提交给 jobManager 。这种方式客户端需要占用大量网络带宽,用来下载依赖和向jobManager上发送数据。而往往我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
于是应用模式直接由JobManager执行应用程序,而不是通过客户端。这意味着,我们需要为每一个提交的单独应用启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager就会关闭。
3.6 独立模式
独立运行,不依赖任何外部的资源管理平台,是部署flink最基本的方式。但是出现资源不足或者出现故障时,没有自动扩展或者重分配资源的保证,所以只能在开发测试等非常少的场景。
3.7 yarn模式
yarn上的部署过程就是:客户端把flink应用提交给yarn的ResourceManager,Yarn的ResourceManager会向NodeManager申请容器。在容器上部署flink的JobManager和TaskManager实例,从而启动集群。
启动集群
$ bin/yarn-session.sh -nm test可用参数解读:
-d:分离模式。即使关掉当前对话窗口,YARN session也可以在后台运行
-jm(--jobManagerMemory):配置jobManager所需内存,默认单位为MB
-nm(--name):配置在YARN UI界面上显示的任务名
-qu(--queue):指定YARN队列名
-tm(--taskManager):配置每个TaskManager所使用内存
四、Flink运行时架构
4.1 系统构成
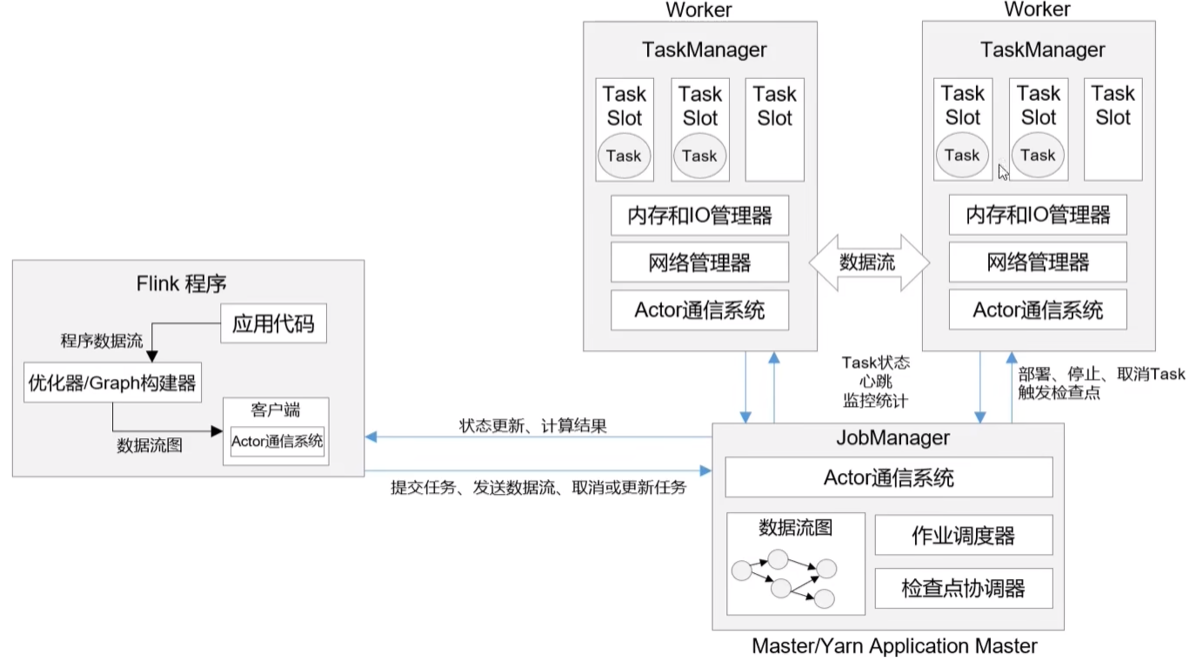
4.1.1 作业管理器(JobManager)
JobManager 是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。
JobManager 包含3个不同的组件:
- JobMaster
- JobMaster 是 JobManager 中最核心的组件,负责处理单独的作业(Job)
- 作业提交时,JobMaster 会先接收到要执行的应用。一般由客户端提交。包括:Jar包、数据流图(Dataflow graph)、作业图(JobGraph)
- JobMaster 把 JobGraph 转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。JobMaster 回向资源管理器ResourceManager 发出请求,申请执行任务的必要的资源。一旦获取到了足够的资源,就会将执行图分发到真正运行它们的 TaskManager 上。
- 在运行过程中,JobMaster 会负责所有需要中央协调的操作,比如 检查点cheakpoint 的协调。
- ResourceManager 资源管理器
ResourceManager 主要负责资源的分配和管理,在Flink 集群中只有一个。所谓“资源”主要是指 TaskManager 的任务操(task slots)。任务操就是 Flink 集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每一个 任务Task 都需要分配到一个 slot 上执行。
- Dispatcher 分发器
Dispatcher主要负责提供一个REST接口,用来提交应用,且为每一个新提交的作业启动一个新的 JobMaster 组件。
4.1.2 任务管理器(TaskManager)
TaskManager 是 Flink 中的工作进程,也被称为 Worker。每一个 TaskManager 都包含了一定数量的任务槽 taskslots。Slot 是资源调度的最小单位,slot 的数量限制了 TaskManager 能够并行处理的任务数量。
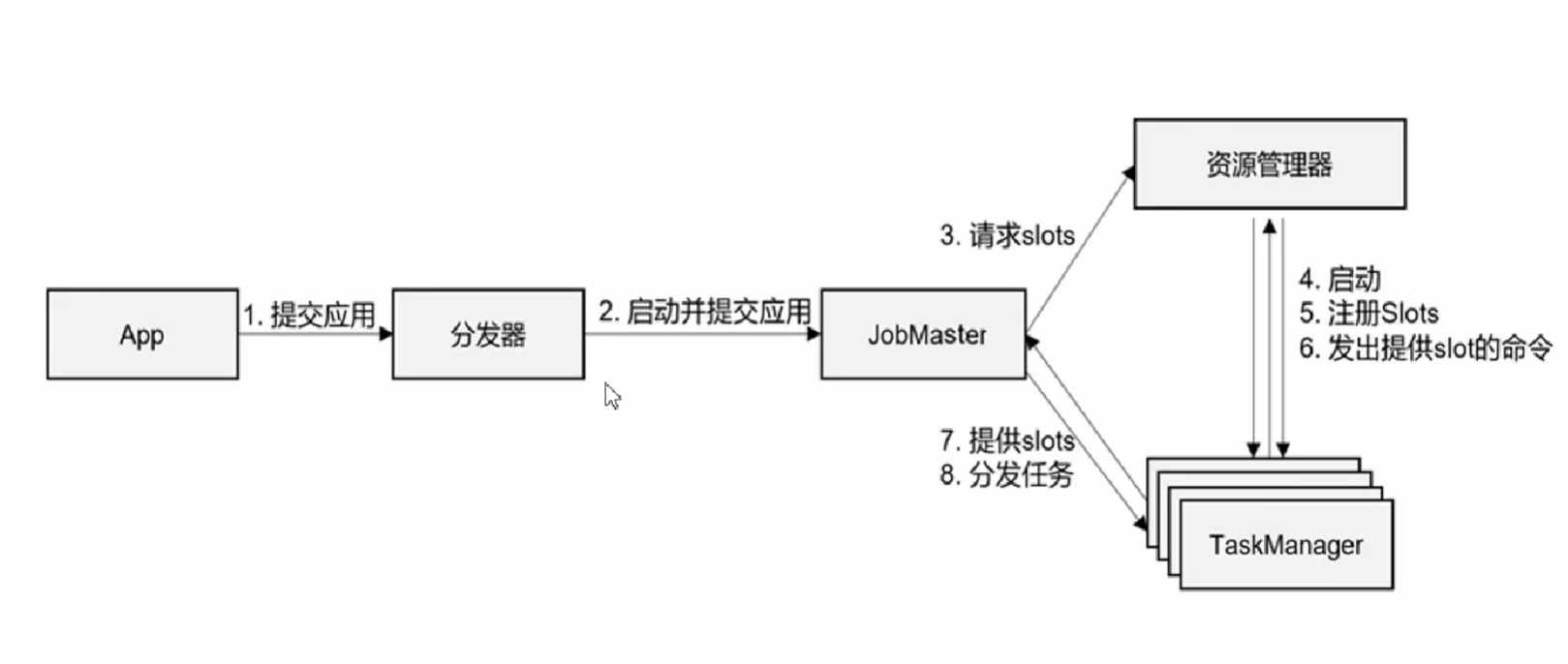
4.2 作业提交流程
结合不同的提交模式,任务提交流程会有些许不同。
-
Standalone 模式
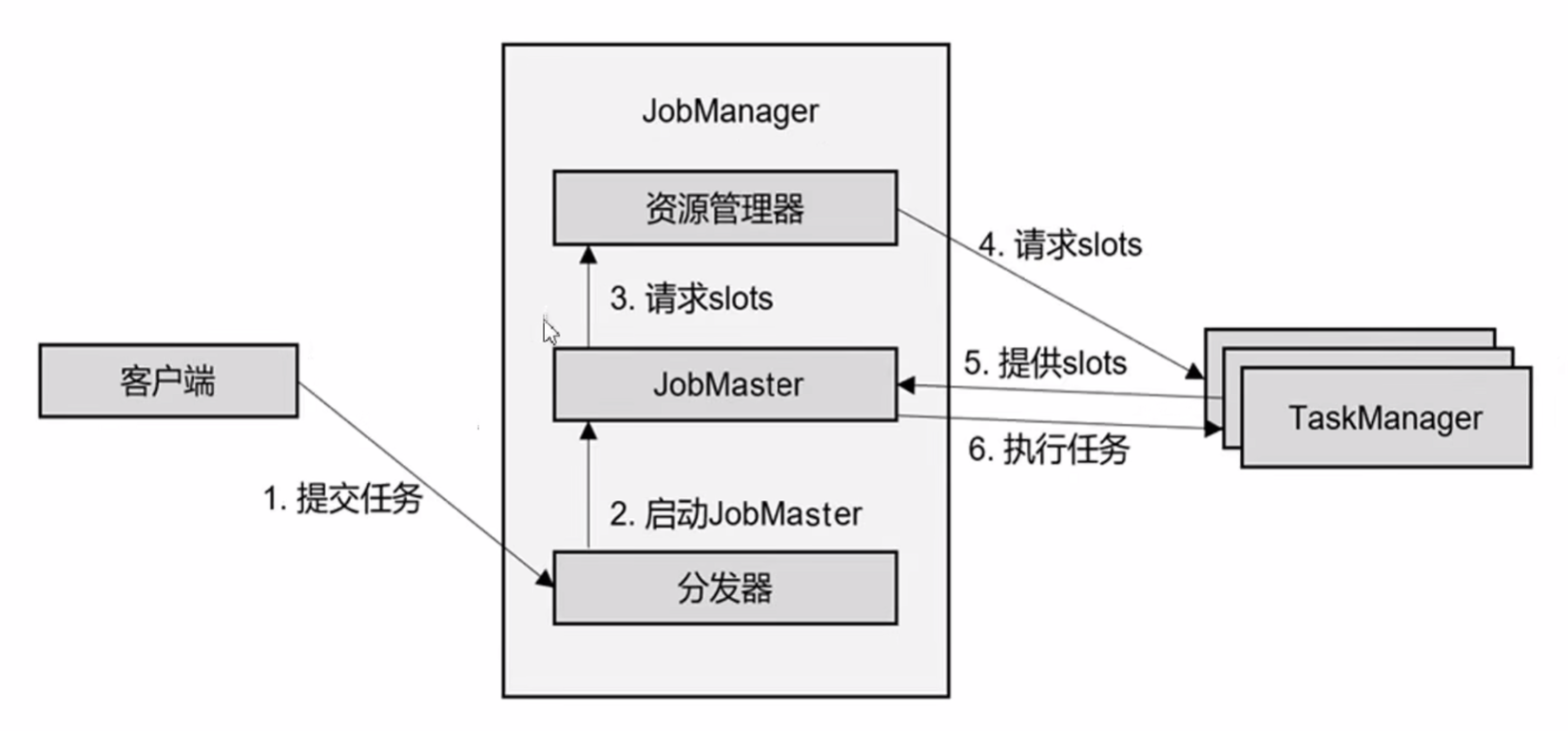
- YARN会话模式

-
YARN单作业模式
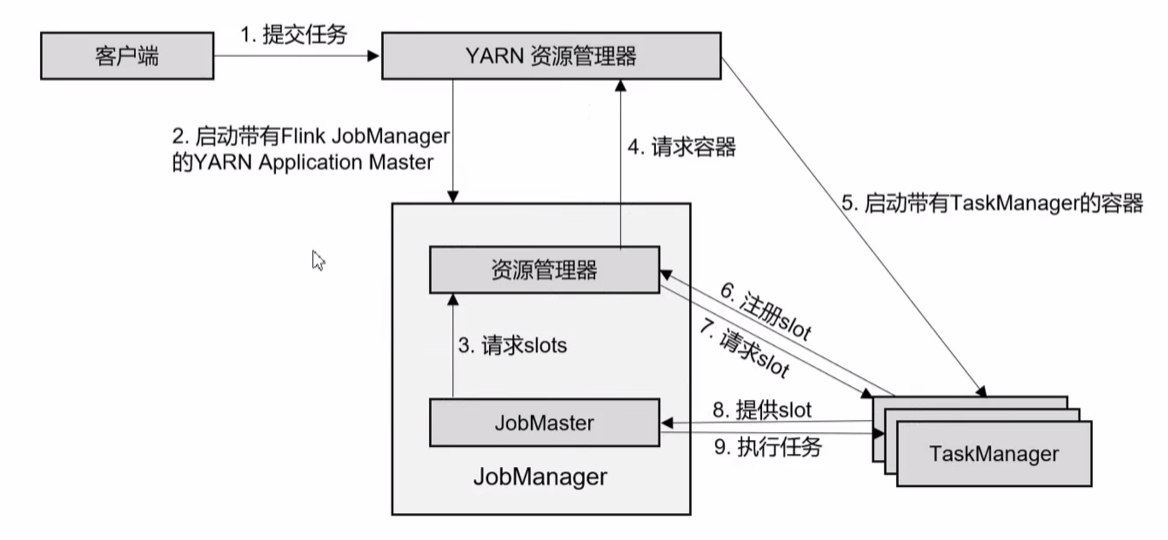
4.3 重要概念
4.3.1 数据流图(Dataflow Graph)
所有的 Flink 程序都是由三部分组成的:Source、Transformation 和 Sink。Source 负责读取数据源,Transformation 利用各种算子进行处理加工,Sink 负责输出。
在运行时,Flink 上运行的程序会被映射成“逻辑数据流”(dataflows)。每一个 dataflows 以一个或多个 sources 开始、以一个或多个 sinks 结束。dataflows 类似于任意的有向无环图DAG。
在大部分情况下,程序中的转换运算(transformations)和 dataflow 中的算子(operator)是一一对应的关系。
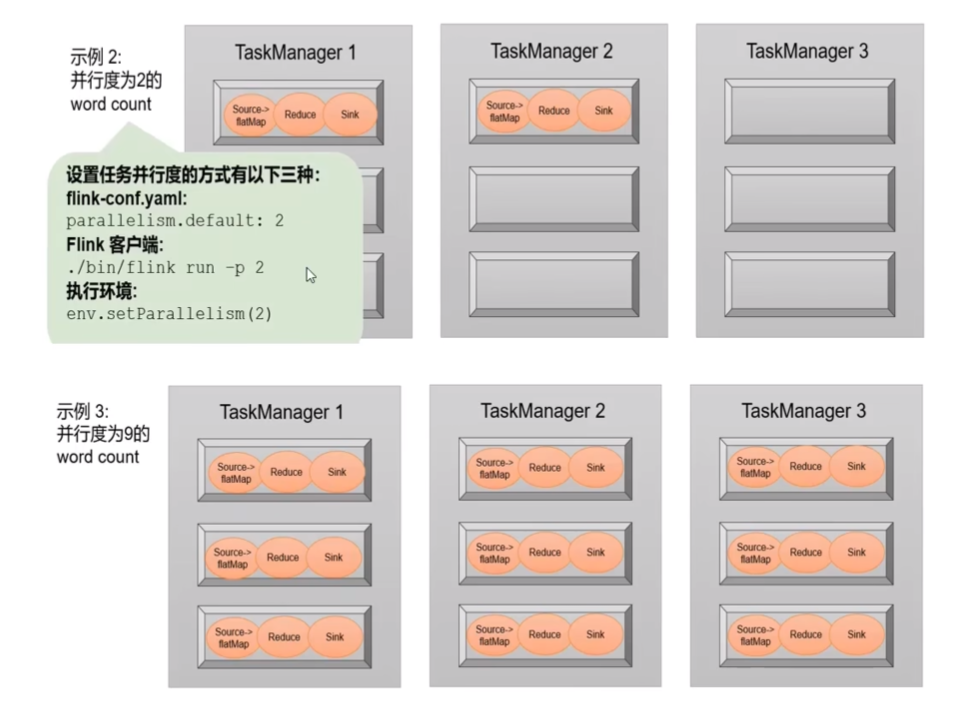
4.3.2 并行度(Parallelism)
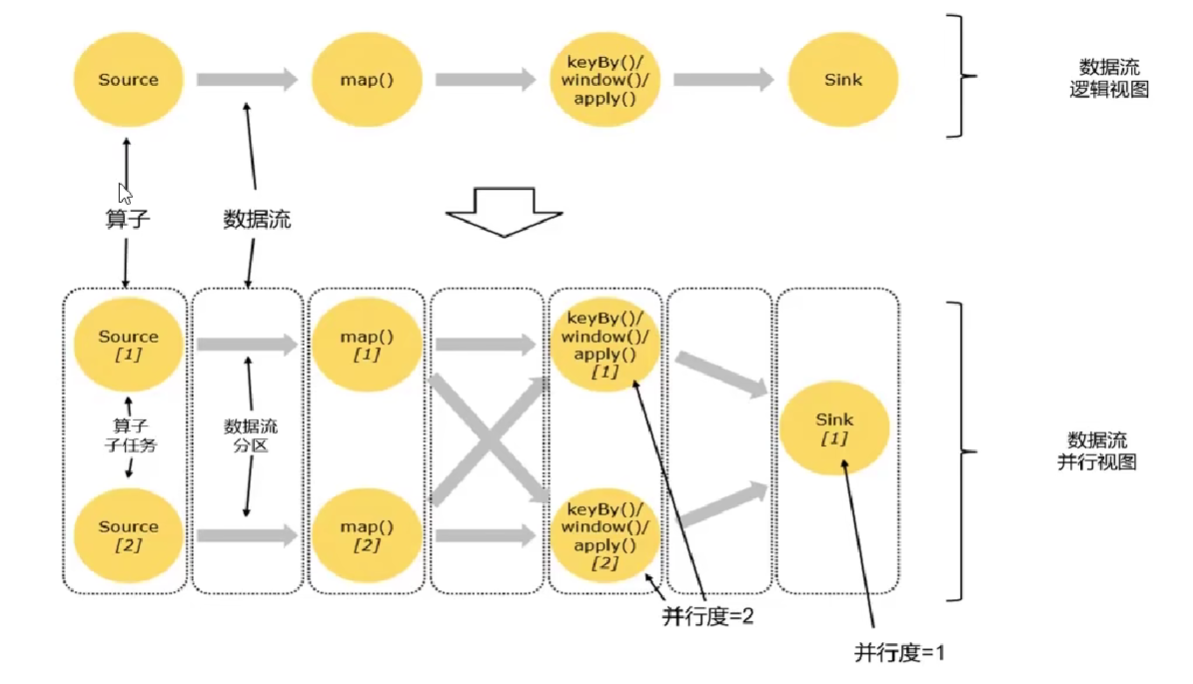
- 每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立的运行。
- 一个特性算子的子任务(subtask)的个数称之为并行度(parallelism)
并行度的设置:
- 代码中设置:
1. 在算子后跟着调用 setParallelism() 方法,设置当前算子的并行度 stream.map().setParallelism(2); 2. 直接调用执行环境的 setParallelism() 方法,全局设定并行度 env.setParallelism(2);
- 提交应用时设置:
flink run 命令提交应用时,可以增加-p 参数来指定当前应用程序执行的并行度 bin/flink run -p 2 -c com.wc.StreamWordCount./FlinkTutorial-1.0-SNAPSHOT.jar
- 配置文件中设置:
直接在集群的配置文件 flink-conf.yaml 中直接更改默认并行度 parallelism.default: 2
4.3.3 算子链
一个程序中,不同的算子可能具有不同的并行度。算子之间的数据传输形式可以是 一对一模式,也可以是 重分区模式。具体哪一种形式,取决于算子的种类。
- One-to-one(一对一模式):
stream 维护着分区以及元素的顺序(如 source 和 map 之间)。表示 map 算子的子任务看到的元素的个数、顺序跟 source 算子的子任务生产段元素个数、顺序相同。
其他算子如:map、filter、flatMap 等算子都是 One-to-one 对应关系。
- Redistributing(重分区模式):
stream 的分区会发生改变。每一个算子的子任务依据所选择的 transformation 发送数据到不同的目标任务。如,keyBy 基于 hashCode 重分区、而 broadcast 和 rebalance 回随机重新分区。这些算子都会引起 redistribute 过程,redistribute 过程就类似于 Spark 中的 shuffle 过程。
Flink 采用了一种任务链的优化技术,在特定条件下减少本地通信的开销。为满足任务链的要求,必须将两个或多个算子设为相同的并行度,通过本地转发的方式进行连接。
相同并行度的 one-to-one操作,Flink这样相连的算子链接在一起形成一个 task,原来的算子成为里面的 subtask。并行度相同、并且是 one-to-one 操作,两个条件缺一不可。
算子链参数:
- 禁用算子链:
.map().disableChaining();
- 从当前算子开始新链:
.map().startNewChain();
4.3.4 执行图
Flink 中的执行图可以分为四层:逻辑流图(StreamGraph) -> 作业图(JobGraph) -> 执行图(ExecutionGraph) -> 物理执行图(Physical Graph)。
- StreamGraph(逻辑流图):
Flink 程序直接映射成的数据流图,也称为逻辑流图。用来表示程序的拓扑结构。
- JobGraph(作业图):
StreamGraph 将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链。在客户端形成 JobGraph,作业提交时传递给 JobMaster。
- ExecutionGraph(执行图):
JobMaster 收到 JobGraph 后,会根据它来生成执行图。与 JobGraph 最大的区别就是:按照并行度对并行子任务进行了拆分,并明确了任务间数据传输的方式。
- 物理执行图:
JobMaster 生成执行图后,会将它分发给 TaskManager。各个 TaskManager 会根据执行图部署任务,最终的物理执行过程也会形成一张“图”,就叫做物理图。它并不是一个具体的数据结构。
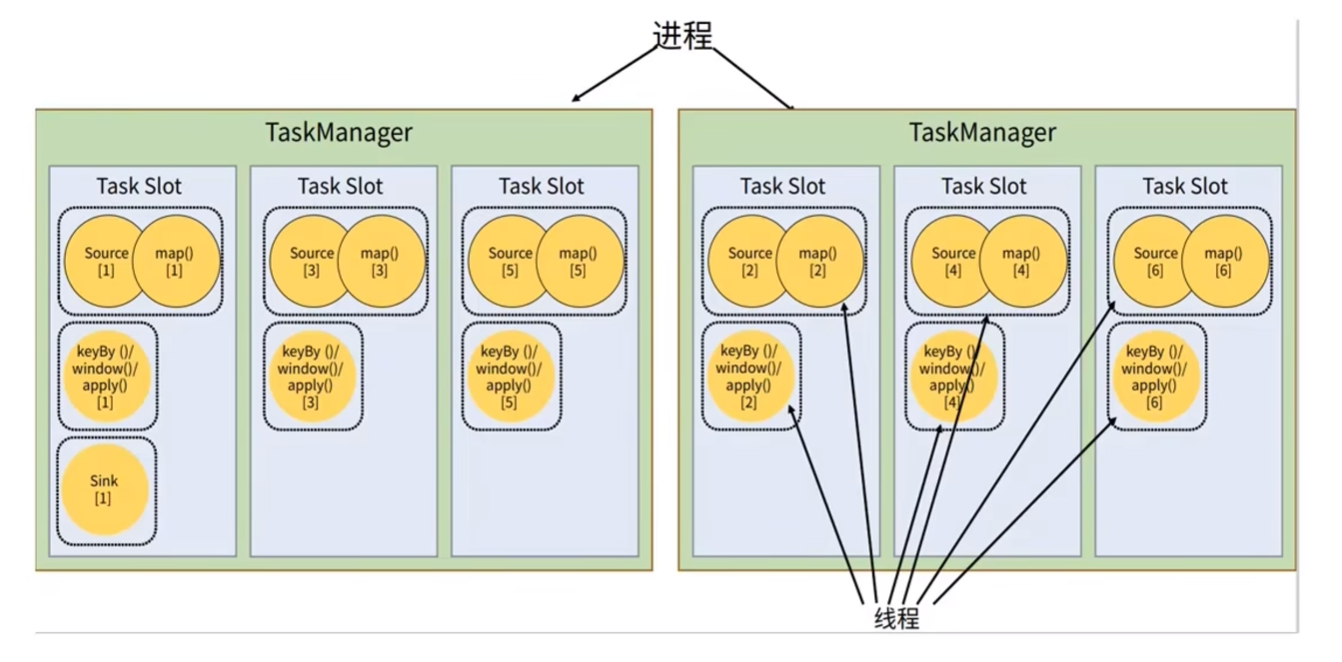
4.3.5 任务(Tasks)和任务槽(Task Slots)

Flink 中每一个 TaskManager 都是一个 JVM 进程,它可能会在独立的线程上执行一个或多个子任务。为了控制一个 TaskManager 能接收到多少个 task,TaskManager 通过 Task Slot 来进行控制(一个 TaskManager 至少有一个 slot)。
任务共享Slot:
默认情况下,Flink 允许子任务共享 slot。这样一个 slot 可以保存作业的整个管道。当我们将资源密集型 和 非密集型 的任务同时放到一个 slot 中,他们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的 TaskManager。
Flink 默认是允许 slot 共享的,如果希望某个算子对应的任务完全独占一个 slot,或者只有某一部分算子共享 slot,我们也可以通过设置“slot共享组”
.map().slotSharingGroup("1");
4.3.6 Slot 和 并行度
- Task Slot
- 静态概念,是指 TaskManager 具有的并发执行能力
- 通过参数 taskmanager.numberOfTaskSlots 进行配置
- 并行度(parallelism)
- 动态概念,也就是 TaskManager 运行程序时实际使用的并发能力
- 通过参数 parallelism.defalut 进行配置