实验一:操作系统初步
在linux系统中的实现
实验原理
API
API(Application Programming Interface,应用程序编程接口),指的是我们用户程序编程调用的如read(),write(),malloc(),free()之类的调用的是glibc库提供的库函数。API直接提供给用户编程使用,运行在用户态。这里要另外提一下,POSIX针对API提出标准,即针对API的函数名,返回值,参数类型进行规范约束,但是并不管API具体如何实现。
系统调用
系统操作系统为用户态进程与硬件设备进行交互提供了一组接口——系统调用,用户程序可以通过这组“特殊”接口来获得操作系统内核提供的服务。通过软中断或系统调用指令向内核发出一个明确的请求,内核将调用内核相关函数来实现(如sys_read(),sys_write())。用户程序不能直接调用这些Sys_read,sys_write等函数。这些函数运行在内核态。
两者联系与区别
区别:API只是一个函数定义,系统调用通过软终端向内核发出一个明确的请求
联系:
1.Libc库定义了一些API引用了封装例程,目的在于发布系统调用。
2.一般每个系统调用对应了一个封装例程,库再用这些封装例程定义出给用户的API。通常API函数库中的函数会调用封装例程,封装例程负责发起系统调用,这些都运行在用户态;内核开始接受系统调用后,CPU从用户态切换到内核态;内核调用相关的内核函数来处理再逐步返回给封装例程,cpu进行一次内核态到用户态的切换,API函数从封装例程拿到结果,在处理完毕后返回用户。
3.当API函数不一定都需要进行系统调用
系统调用号
一个系统调用号,对应一个函数入口地址,glibc和内核里面的这个系统调用号是一致的,所以glibc调用汇编之类把系统调用号传给内核的时候,内核找到这个具体的系统调用服务例程对应的函数入口地址,如sys_read。
系统调用和函数调用的区别
- 系统调用和库函数的关系
a. 系统调用通过软终端int 0x80从用户态进入内核态。 函数库中的某些函数调用了系统调用
b. 函数库中的函数可以没有调用系统调用,也可以调用多个系统调用 编程人员可以通过函数库调用系统调用 高级编程也可以直接采用int
c.0x80进入系统调用,而不必通过函数库作为中介 如果是在核心编程,也可以通过int
d.0x80进入系统调用,此时不能使用函数库。因为函数库中的函数是内核访问不到的, - 从用户调用库函数到系统调用执行的流程
a.用户调用getpid()库函数
b.库函数执行int 0x80中断,由于中断使得进程从用户态进入内核态,参数通过寄存器传送
c.0x80中断对应的中断例程被称为system call handler。其工作为存储大多数寄存器到内核堆栈中,这是汇编代码写的
d.执行真正的系统调用函数-system call service routine,这是C代码
e.通过ret_from_sys_call()返回,回到用户态的库函数,这是汇编代码写的
软中断
软中断与硬中断
硬中断:由与系统相连的外设(比如网卡、硬盘)自动产生的。主要是用来通知操作系统系统外设的变化,比如网卡收到数据包的时候,就会发送一个中断。通常我们说的中断指的是硬中断(hardirq)
软中断:为了满足实时系统的要求,中断处理应该是越快越好。Linux为了实现这个特点,当中断发生的时候硬中断处理那些短时间就可以完成的工作,而将那些处理事情比较长的工作,放到中断之后来完成,也就是软中断(softirq)
软中断指令。
Int是软中断指令。中断向量表是中断号和中断处理函数地址的对应表,int n-触发软中断n。相应的中断处理函数的地址为:中断向量表地址+4*n
int与函数调用call的区别
以上内容参考以下博主的该篇文档中的实验原理部分
原文:https://blog.csdn.net/weixin_43641509/article/details/88567034
Task1 系统调用实验
实验要求
-
分别运行用API接口函数getpid()直接调用和汇编中断调用两种方式调用Linux操作系统的同一个系统调用getpid的程序
-
请问getpid的系统调用号是多少?linux系统调用的中断向量号是多少?
答:getpid的系统调用号是 14H、中断向量号是80H。
实验代码
使用接口
invoke.c
//Using API getpid()
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid;
pid = getpid();
printf("%d\n",pid );
return 0;
}
使用汇编中断
invokeassemble.c
//Using Assembly Language
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid;
asm volatile(
"mov $0,%%ebx\n\t"
"mov $0x14,%%eax\n\t"
"int $0x80\n\t"
"mov %%eax,%0\n\t"
:"=m"(pid)
);
printf("%d\n",pid );
return 0;
}
运行结果
使用gcc -o filename filename.c将源文件改写成可执行文件
下图:生成可执行文件invokepid
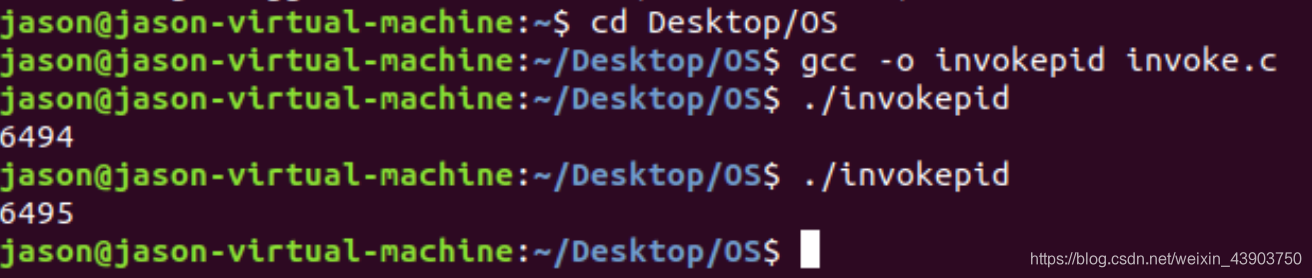
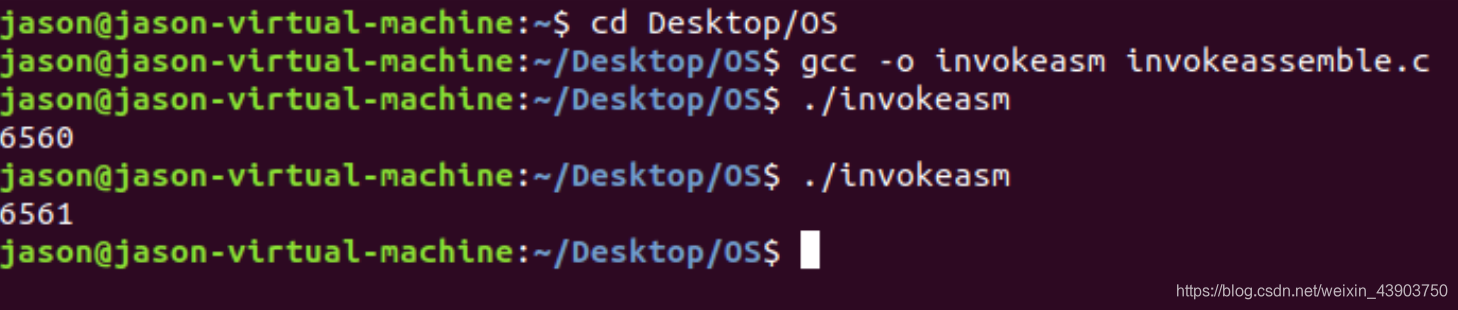
生成可执行文件invokeasm
系统调用
系统调用和普通函数完全不同,系统调用实际上是0x80号中断对应的中断处理程序的子程序。换句话说,在linux系统上,0x80中断是系统调用的统一入口。某个具体的系统调用是这个中断处理程序的子程序,进入具体某个系统调用是通过内核定义的系统调用号码来实现的。linux通过执行如下汇编代码陷入内核执行系统调用:
int 0x80; //这一句是进入系统调用统一入口。
在执行"int 0x80;"进行中断之前,
1.把系统调用号码赋值给寄存器EAX;
2.把系统调用需要的参数按次序赋值给寄存器EBX,ECX,EDX等等。
这样,等下0x80中断发生的时候,系统调用需要的全部信息就能通过这些寄存器传递给中断处理程序了。
使用汇编语言写hello world程序
.section .data
message:
.ascii "hello world!\n"
length = . - message
.section .text
.global _start # must be declared for linker
_start:
movq $1, %rax # 'write' syscall number
movq $1, %rdi # file descriptor, stdout
lea message(%rip), %rsi # relative addressing string message
movq $length, %rdx
syscall
movq $60, %rax # 'exit' syscall number
xor %rdi, %rdi # set rdi to zero
syscall
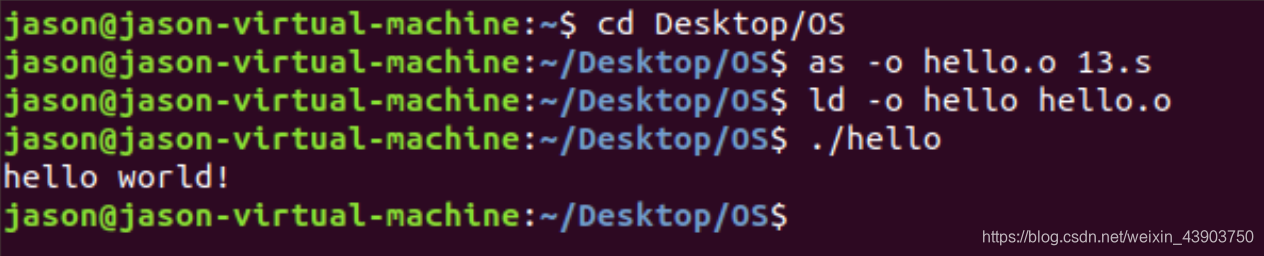
运行结果
Task2 并发实验
实验要求
- 编译运行该程序(cpu.c),观察输出结果,说明程序功能。
(编译命令: gcc -o cpu cpu.c –Wall)(执行命令:./cpu) - 再次按下面的运行并观察结果:执行命令:./cpu A & ; ./cpu B & ; ./cpu C & ; ./cpu D &程序cpu运行了几次?他们运行的顺序有何特点和规律?请结合操作系统的特征进行解释。
实验代码
cpu.c
#include <stdlib.h>
#include <sys/time.h>
#include <assert.h>
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "usage: cpu <string>\n");
exit(1);
}
char *str = argv[1];
while (1) {
sleep();
printf("%s\n", str);
}
return 0;
}
运行结果
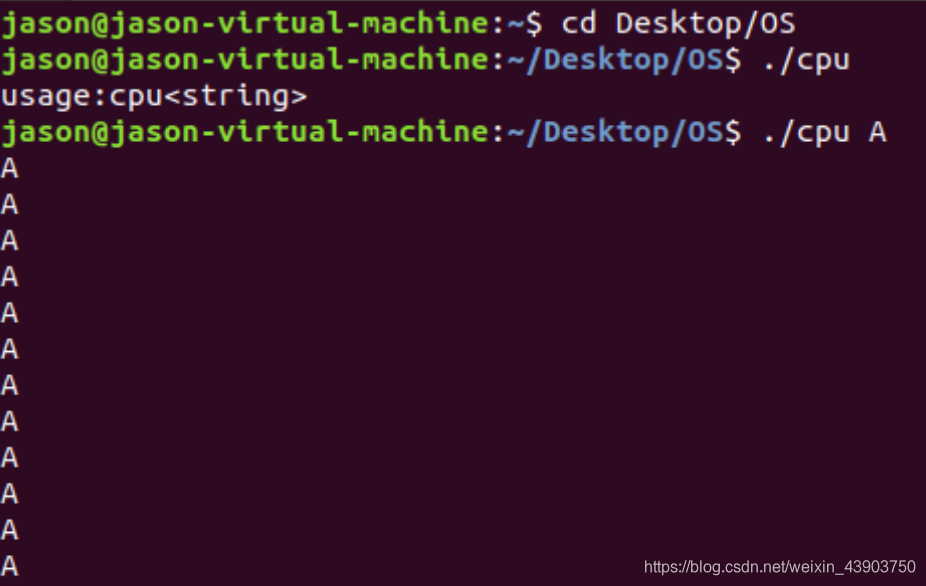
当不输入参数时,会输出显示usage : cpu < string >;当传入参数A的时候,每隔一段循环(sleep)时间,只要不手动停止,就会一直输出这个字符A。
当运行指令 ./cpu A & ./cpu B & ./cpu C & ;时,四个程序分别使用参数ABCD开始运行,操作系统在硬件的帮助下负责程序的并发执行,让用户感受到CPU的虚拟化。将单个CPU转换为看似无限数量的CPU,看起来像是一起在运行,称为虚拟化。
Task3 内存分配
实验代码
mem.c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
int main(int argc, char *argv[])
{
int *p = malloc(sizeof(int)); // a1
assert(p != NULL);
printf("(%d) address pointed to by p: %p\n",getpid(), p); // a2
*p = 0; // a3
while (1) {
sleep(10);
*p = *p + 1;
printf("(%d) p: %d\n", getpid(), *p); // a4
}
return 0;
}
实验结果
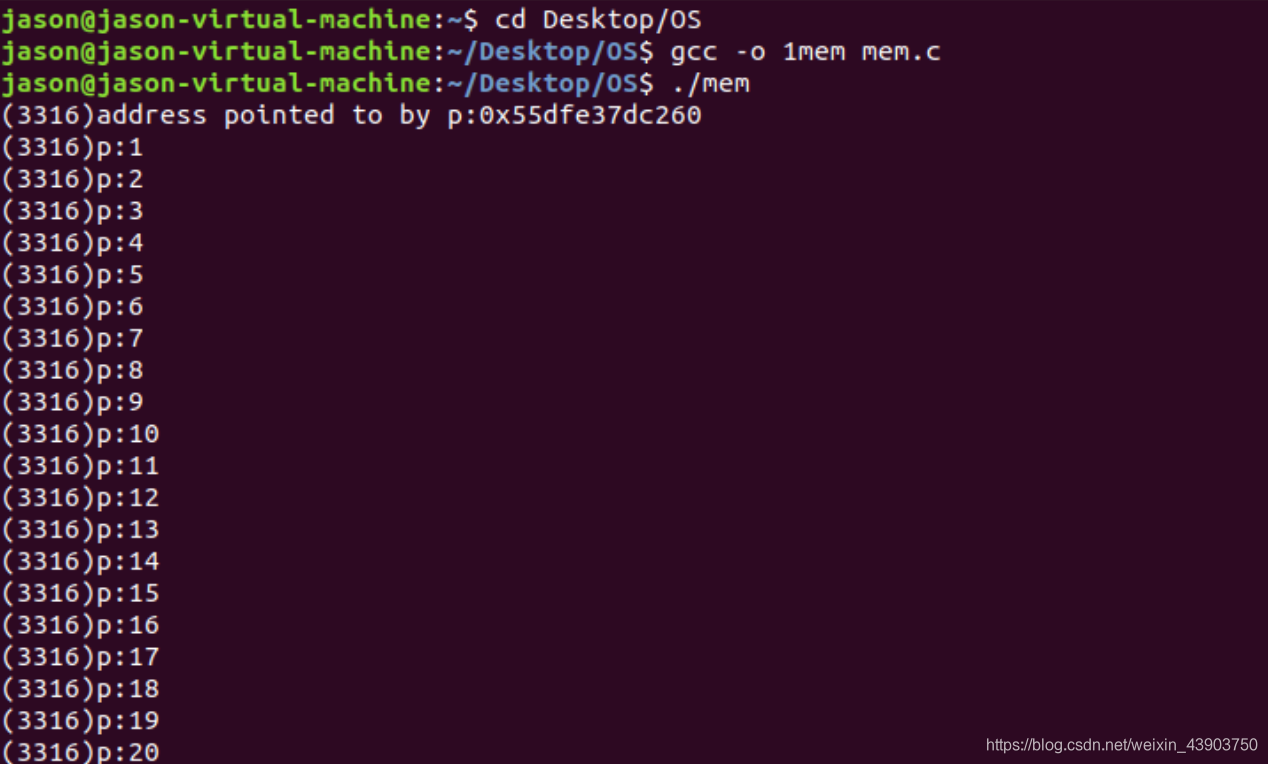
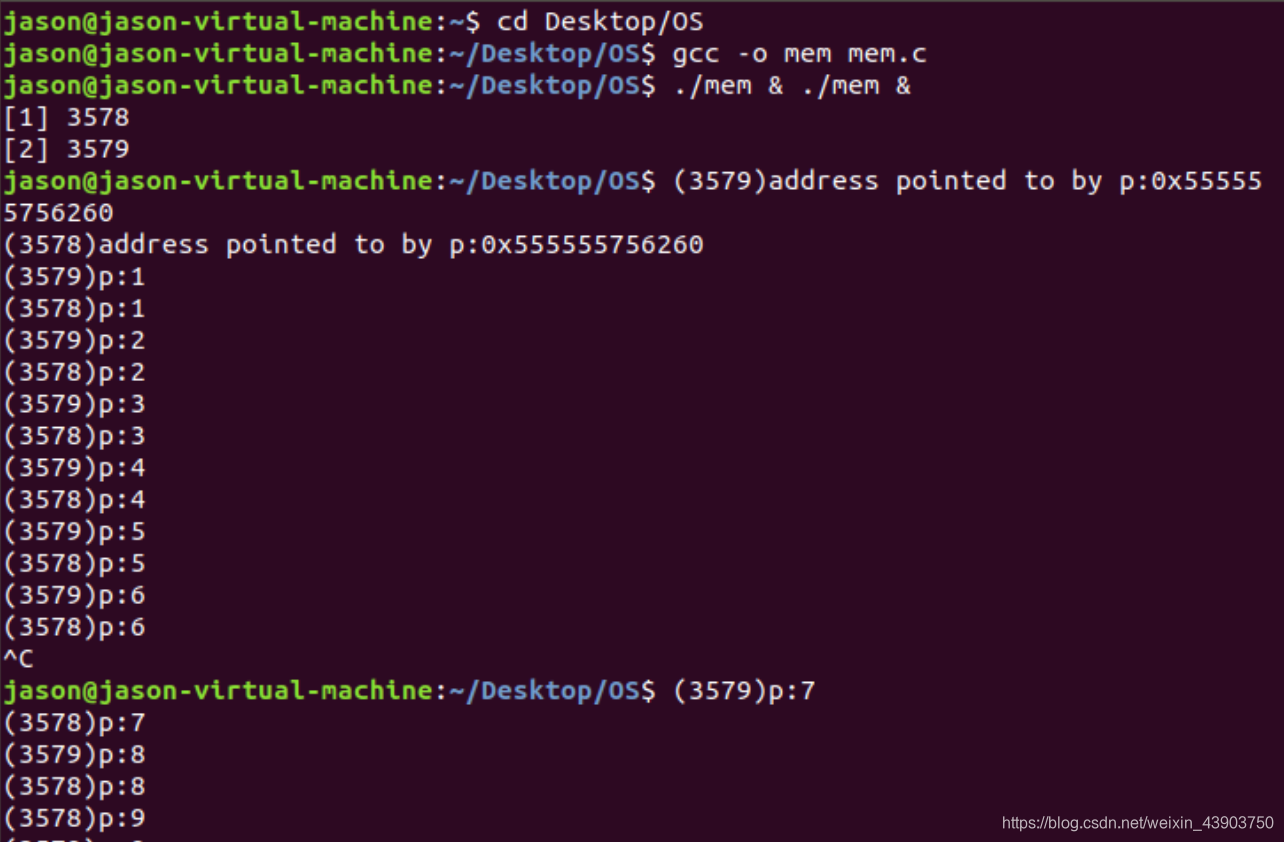
当运行单个mem程序的时候,内存是顺序分配的。下面看两个mem程序运行的情形。
先使用 命令
sysctl -w kernel.randomize_va_space=0
关闭地址空间随机化,再在shell中打开两个mem程序,查看结果
- 操作系统虚拟化了内存,每个进程访问自己的私有虚拟地址空间,操作系统以某种方式映射到机器的物理内存。一个正在运行的程序中的内存引用不会影响其他进程的地址空间;就运行程序而言,它拥有所有的物理内存。然而,现实是物理内存是由操作系统管理的共享资源。究竟如何实现所有这些也是本书第一部分关于虚拟化主题的内容。
- 所以从进程的不同性上面来说,有可能对应相同的虚拟地址,但是真实的物理地址不会相同,这种虚拟内存也不保证不同进程的相互隔离,错误程序不会干扰别的正确的进程。
Task4 共享问题
实验要求
- 阅读并编译运行该程序,观察输出结果,说明程序功能。(编译命令:gcc -o thread thread.c -Wall –pthread)(执行命令1:./thread 1000)
- 尝试其他输入参数并执行,并总结执行结果的有何规律?你能尝试解释它吗?(例如执行命令2:./thread 100000)(或者其他参数。)
- 提示:哪些变量是各个线程共享的,线程并发执行时访问共享变量会不会导致意想不到的问题。
实验代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
volatile int counter = 0;
int loops;
void *worker(void *arg) {
int i;
for (i = 0; i < loops; i++) {
counter++;
}
return NULL;
}
int
main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "usage: threads <value>\n");
exit(1);
}
loops = atoi(argv[1]);
pthread_t p1, p2;
printf("Initial value : %d\n", counter);
pthread_create(&p1, NULL, worker, NULL);
pthread_create(&p2, NULL, worker, NULL);
pthread_join(p1, NULL);
pthread_join(p2, NULL);
printf("Final value : %d\n", counter);
return 0;
}
实验结果
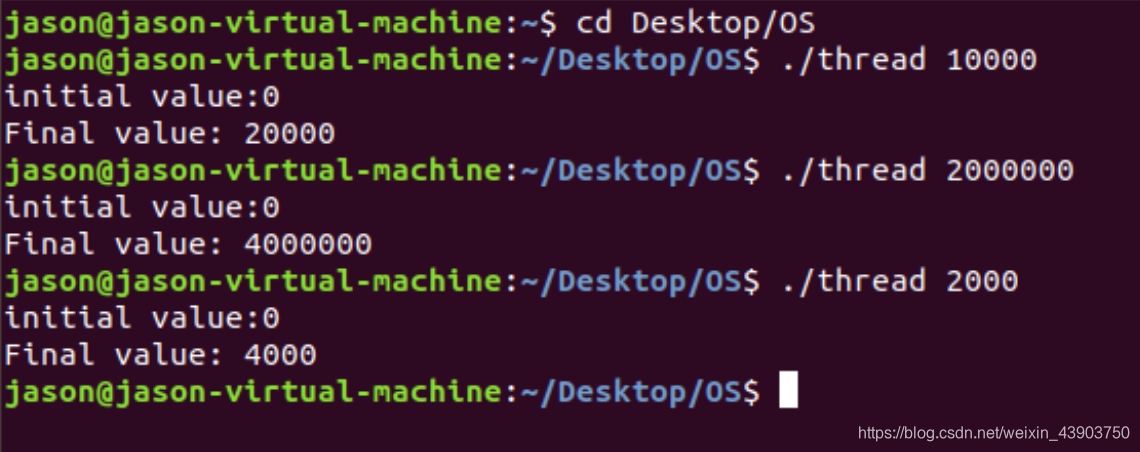
当传入参数值较小时,Final Value会是参数两倍值,但是随着传入参数变大,会发生异常的情况。‘

此时输出值小于了输入的值。
两个线程在同一进程,并且访问共享的操作对象时,会发生读脏数据的情况。现今为防止该现象发生,一般采用内存锁的设计,保证线程实现的完整性。
当参数比较大时,单核心无法满足运行多线程的任务,锁机制就会被破坏,进而产生读脏数据的情况。