版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_43435675/article/details/88383366
本文章可以与文章 《一元二次方程回归预测(tensorflow版)》一起比较会更有收获,下面为文章链接 [link]https://blog.csdn.net/weixin_43435675/article/details/88380455
0.数据准备
在桌面新建一个名为tensorflowtest文件夹,cmd打开jupyter notebook,新建名为tensorflowTest.ipynb
#检测tensorflow环境
import tensorflow as tf
hello = tf.constant('hello world')
session = tf.Session()
session.run(hello)
import tensorflow as tf
import numpy as np
batch_size = 100
X_data = np.linspace(-1, 1, 300).reshape(-1, 1).astype('float32')
noise = np.random.normal(0, 0.1, X_data.shape).astype('float32')
y_data = np.square(X_data) - 0.5 + noise
with tf.name_scope('inputs'):#scope中文叫做适用范围,每定义一个tf.name_scope,在tensorboard界面的graph中会有一个节点
X_holder = tf.placeholder(tf.float32, name='input_X')#tf.placeholder方法的第1个参数是tensorflow中的数据类型;第2个关键字参数name的数据类型是字符串,是在tensorboard界面中的显示名
y_holder = tf.placeholder(tf.float32, name='input_y')
1.搭建神经网络
定义addConnect函数,作用是添加1层连接。
因为该神经网络总共有3层:输入层、隐层、输出层,所以需要调用2次addConnect函数添加2层连接。
addConnect函数第1个参数是输入矩阵,第2个参数是输入矩阵的列数,第3个参数是输出矩阵的列数,第4个参数用来定义是第几层连接,第5个参数是激活函数。
最后6行代码定义损失函数、优化器、训练过程。
def addConnect(inputs, in_size, out_size, n_connect, activation_function=None):
connect_name = 'connect%s' %n_connect
with tf.name_scope(connect_name):
with tf.name_scope('Weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]) ,name='W')
tf.summary.histogram(connect_name + '/Weights', Weights)
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
tf.summary.histogram(connect_name + '/biases', biases)
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
return Wx_plus_b
else:
return activation_function(Wx_plus_b)
connect_1 = addConnect(X_holder, 1, 10, 1, tf.nn.relu)
predict_y = addConnect(connect_1, 10, 1, 2)
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.square(y_holder - predict_y))
tf.summary.scalar('loss', loss)
with tf.name_scope('train'):
optimizer = tf.train.AdamOptimizer(0.1)
train = optimizer.minimize(loss)
2.变量初始化
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
3.模型训练
import datetime #导入datetime库获取当前时间,从而给文件夹命名
import random
nowTime = datetime.datetime.now()
timestamp = nowTime.strftime('%m%d%H%M%S')
write = tf.summary.FileWriter('logs'+timestamp, session.graph)
#上面三行给新建的日志文件夹命名
merge_all = tf.summary.merge_all()#将绘制标量曲线图SCALARS、变量曲线图DISTRIBUTIONS、变量分布直方图HISTOGRAMS的任务合并交给变量merge_all
for i in range(201):
select_index = random.sample(range(len(X_data)), k=batch_size)#使用random.sample方法选取数量为batch_size的样本来训练
select_X = X_data[select_index]
select_y = y_data[select_index]
#在200次训练迭代中,第10、11、12行代码选取数量为batch_size的样本来训练
session.run(train, feed_dict={X_holder:select_X, y_holder:select_y})#每运行1次,即神经网络训练1次
merged = session.run(merge_all, feed_dict={X_holder:select_X, y_holder:select_y})#获得每次训练后loss、Weights、biases值;
write.add_summary(merged, i)#把loss、Weights、biases值写入日志文件中
产生日志文件,点进日志文件夹再cmd,输入:tensorboard --logdir ./

此时在浏览器输入上图2或者localhost:6006
4.tensorboard的模型训练可视化
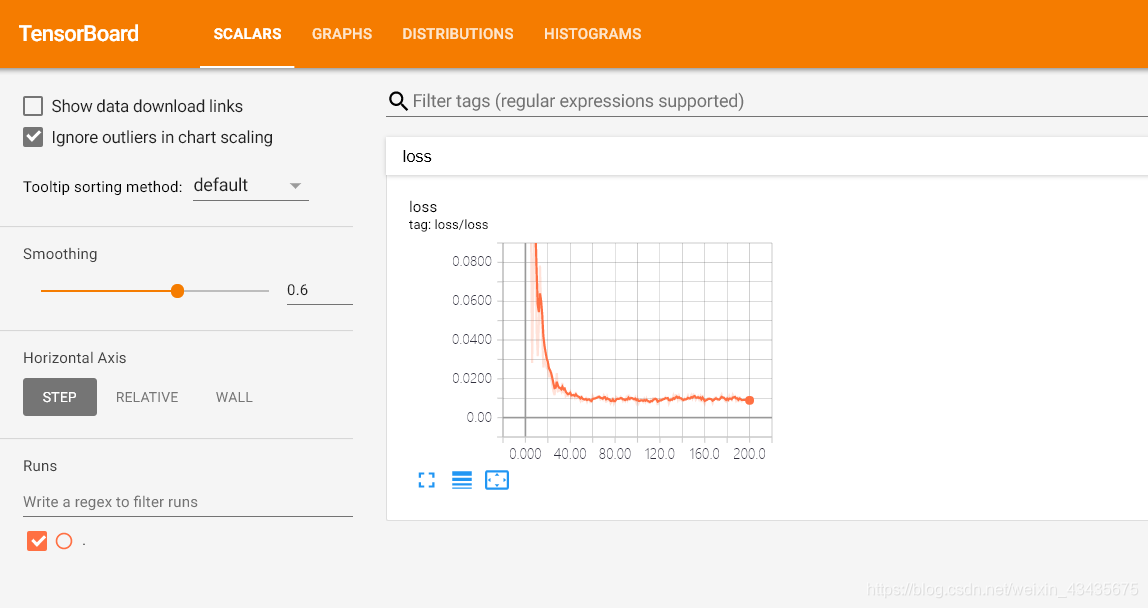
下图为loss的变化曲线图:
下图为神经网络架构图:
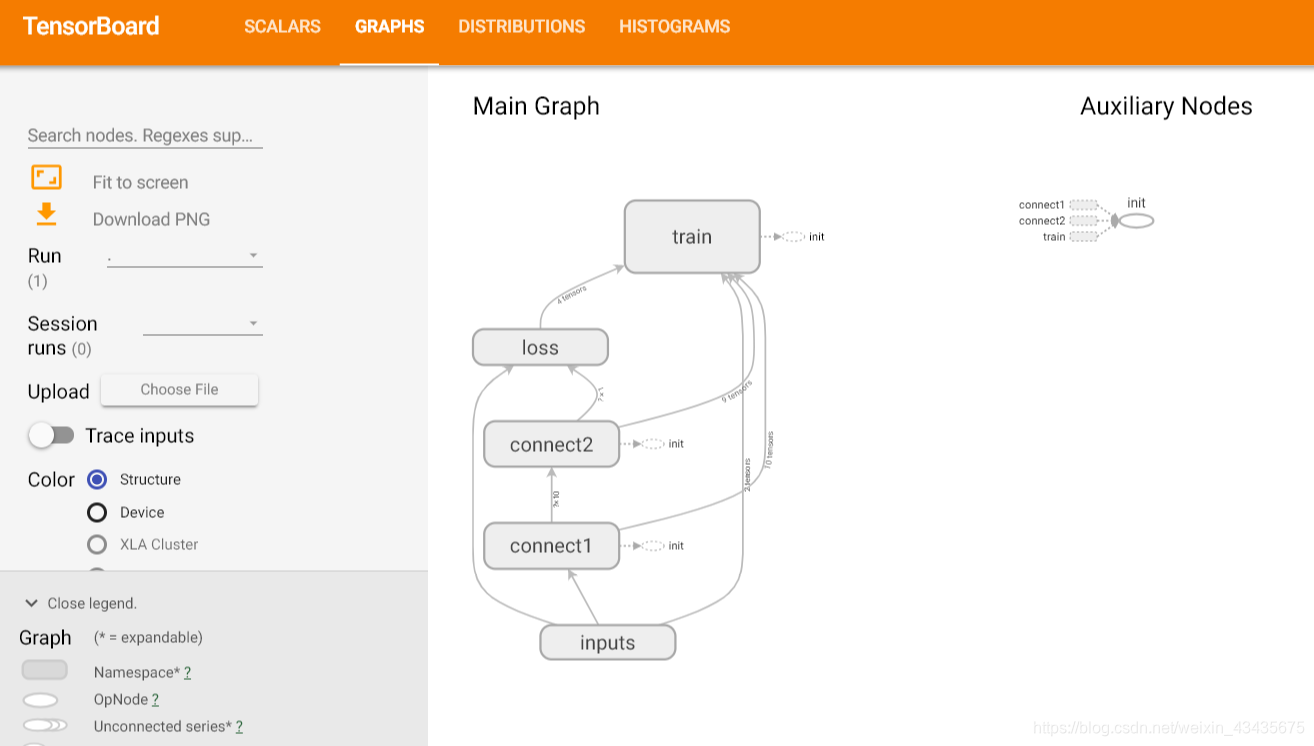
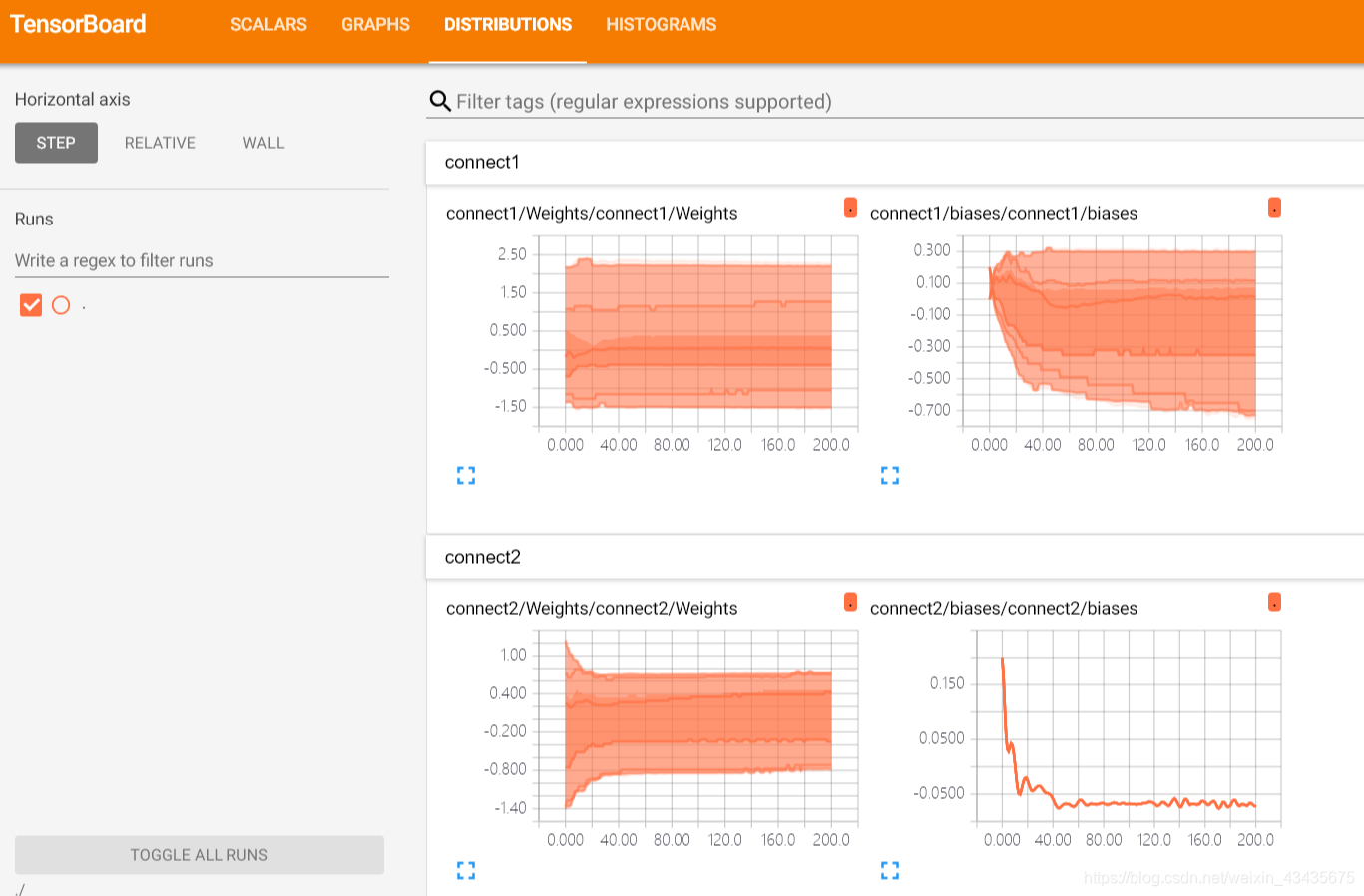
下图为权重Weights和偏置biases的变化曲线图:
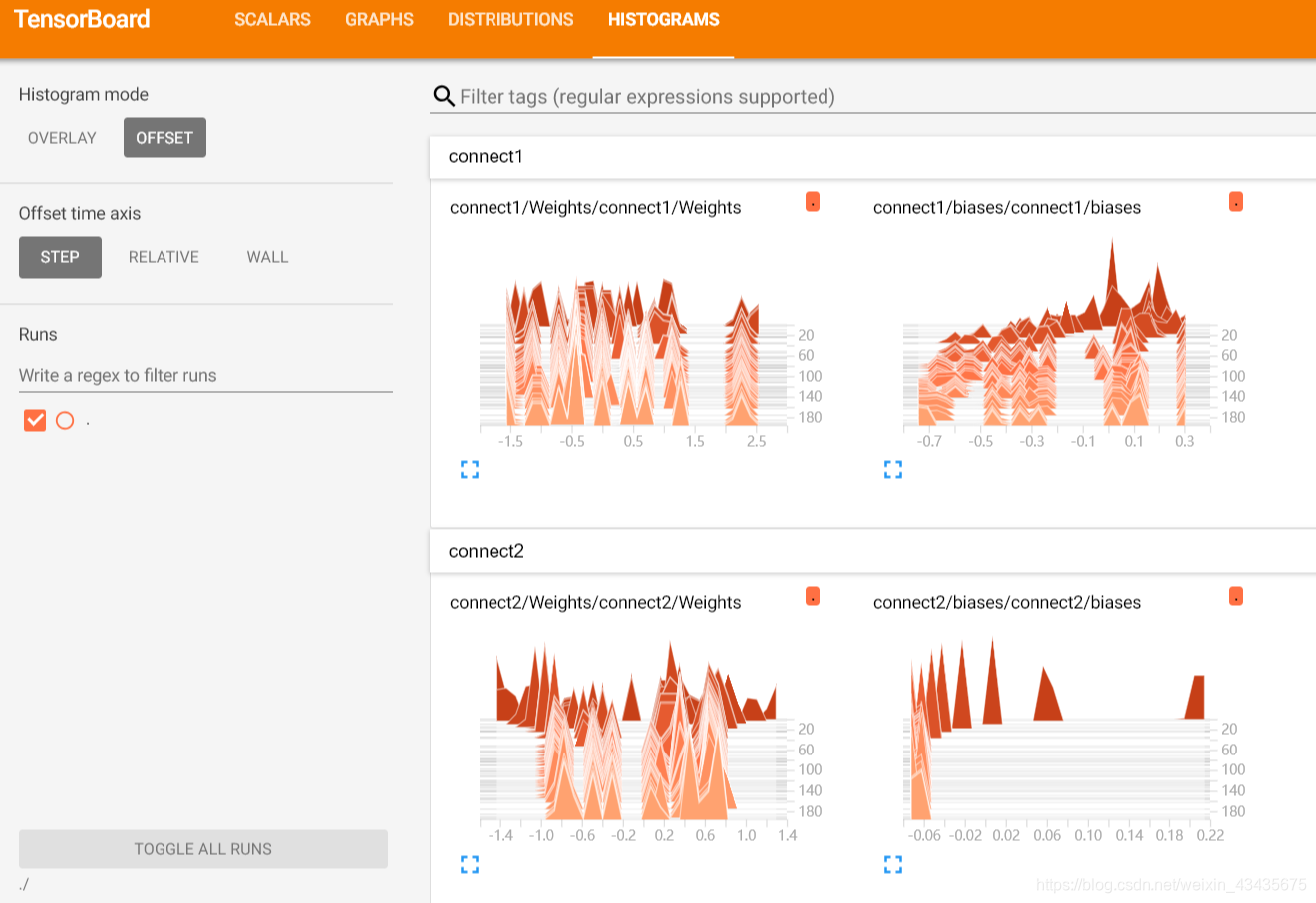
下图为权重Weights和偏置biases的分布直方图:
结合matplotlib可视化做对比: